I-RightNow AI Ikhipha I-AutoKernel: Uhlaka Lomthombo Ovulekile Olusebenzisa I-Autonomous Agent Loop ku-GPU Kernel Optimization for Arbitrary PyTorch Models

Ukubhala ikhodi ye-GPU esheshayo kungenye yezinto ezikhethekile ezikhathazayo kakhulu kubunjiniyela bokufunda komshini. Abacwaningi abavela kwa-RightNow AI bafuna ukuyenza ngokuzenzakalelayo ngokuphelele.
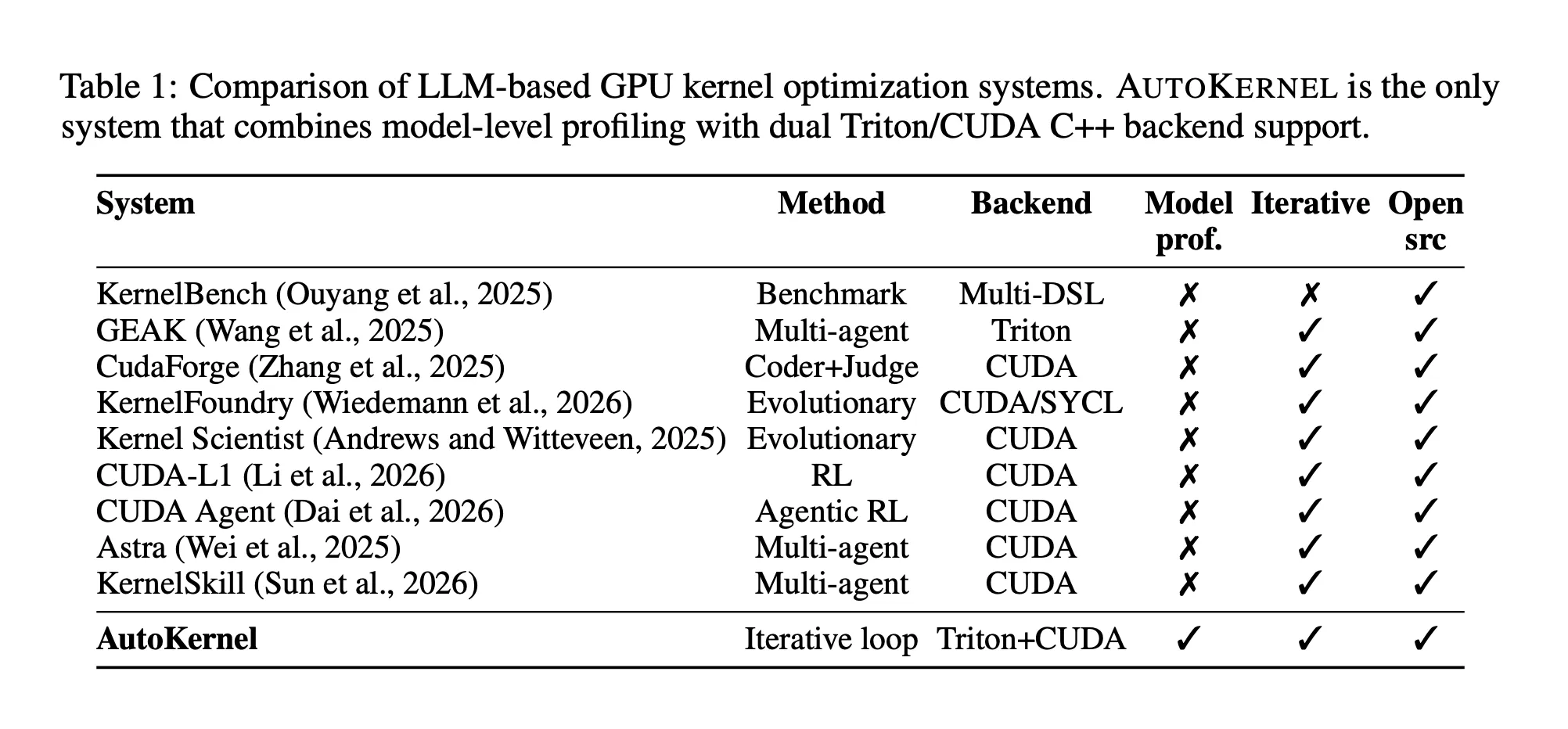
Ithimba labacwaningi be-RightNow AI likhiphe i-AutoKernel, uhlaka lomthombo ovulekile olusebenzisa i-loop ye-ejenti ye-LLM ezimele ku-GPU kernel optimization yamamodeli e-PyTorch angenangqondo. Indlela yokwenza iqondile: inikeze noma iyiphi imodeli ngaphambi kokuthi ulale, futhi uvuse ama-Triton kernels asheshayo – abukho ubuchwepheshe be-GPU obudingekayo.

Kungani I-GPU Kernels Kunzima Kangaka Ukuzilungiselela
I-GPU kernel iwumsebenzi osebenza ngokufana ezinkulungwaneni zama-GPU cores. Uma usebenzisa imodeli ye-transformer efana ne-LLaMA noma i-GPT-2, isikhathi esiningi sokubala sichithwa ngaphakathi kwezinhlamvu zemisebenzi efana nokuphindaphinda kwe-matrix (i-matmul), i-softmax, ukujwayela kwesendlalelo, nokunaka. Lezi zinhlamvu zihlala kulabhulali efana ne-cuBLAS ne-cuDNN, noma zikhiqizwe ngokuzenzakalelayo ipayipi lokuhlanganiswa le-PyTorch.
Inkinga ukuthi ukuminyanisa ukusebenza okuphezulu kulawa ma-kernel kudinga ukucabanga ngesikhathi esisodwa mayelana nokuqina kwe-arithmetic, ukuhlangana kwenkumbulo, ukucindezela kwerejista, osayizi bamathayela, ukuvumelanisa kwezinga le-warp, nokukhetha kwemiyalelo eyinhloko ye-tensor – inhlanganisela yamakhono athatha iminyaka ukuthuthuka. I-matmul kernel eyodwa esebenza kahle ingase ifake imigqa engu-200+ ye-CUDA noma ikhodi ye-Triton enenqwaba yamapharamitha ancike kwelinye. Lobu buchwepheshe buyindlala, futhi inqubo yokushuna mathupha ikhula kabi njengoba amamodeli ezakhiwo athuthuka.
I-benchmark suite i-KernelBench, ehlola ama-LLM emngceleni ezinkingeni ze-kernel ye-GPU engu-250, ithole ukuthi namamodeli angcono kakhulu ahambisana nokusebenza kwesisekelo se-PyTorch ngaphansi kwama-20% wamacala asebenzisa isizukulwane seshothi eyodwa. I-AutoKernel yakhiwe ngokuqondile ngokuphendula lelo gebe.
I-Loop: Hlela, Benchmark, Gcina noma Buyisela
Ukuqonda okuyinhloko kwe-AutoKernel ukuthi ukuhamba komsebenzi kanjiniyela we-kernel ochwepheshe kumane kuyiluphu elula: bhala ikhandidethi, lilinganise, gcina ukuthuthukiswa, lahla ukuhlehla, phinda. Uhlaka lusebenza ngomshini le loop. I-ejenti ye-LLM ilungisa ifayela elilodwa — kernel.py — iharness yebhentshimakhi engaguquki iqinisekisa ukulunga futhi ikala okuphumayo, futhi umphumela unquma ukuthi ushintsho luyaqhubeka yini. Okubaluleke kakhulu, zonke izivivinyo zifaka ukuzinikela kwe-git. Izivivinyo ezigciniwe ziqhubekisela phambili igatsha; ukuhlolwa okubuyiselwe kususwa ngokuhlanzekile nge git reset. Wonke umlando ungaphequluka ngamathuluzi ajwayelekile e-git, futhi imiphumela yokuhlolwa ifakwe kufayela le-results elihlukaniswe ngethebhu elingenalutho — alincikile, liyafundeka ngabantu, futhi lihlukaniseka kancane yi-ejenti.
Ukuphindaphinda ngakunye kuthatha cishe amasekhondi angu-90 — amasekhondi angu-30 ukuhlola ukulunga, imizuzwana engu-30 yokulinganisa ukusebenza nge-Triton's do_bench, kanye nemizuzwana engu-30 yokucabanga komenzeli nokuguqulwa kwekhodi. Cishe ekuhlolweni okungu-40 ngehora, ukugijima kwamahora angu-10 ngobusuku obubodwa kuveza ukuhlola okungu-300 kuya ku-400 kuma-kernel amaningi.
Lo mklamo usuka ngokuqondile kuphrojekthi yocwaningo lwe-autoresearch ka-Andrej Karpathy, ebonise ukuthi i-ejenti ye-AI esebenzisa i-keep/revert loop kukhodi yokuqeqesha ye-LLM ingathola ukulungiselelwa okungu-20 kuzo zonke izivivinyo ezingu-700 ezinsukwini ezimbili ku-GPU eyodwa. I-AutoKernel idlulisela le loop kukhodi ye-kernel, ngesikhala sokusesha esihlukile kanye nebhentshimakhi enesango lokunemba njengomsebenzi wokuhlola esikhundleni sokulahlekelwa kokuqinisekisa.
Umenzeli ufunda idokhumenti yeziqondiso enemigqa engu-909 ebizwa ngokuthi i-program.md, ehlanganisa ulwazi lochwepheshe encwadini yokudlala yokuthuthukisa enezigaba eziyisithupha. Ama-tiers aqhubekela phambili ukusuka ekushuneni kosayizi webhulokhi (ubukhulu bethayela obushanela ngamandla angu-2, ukulungisa i-num_warps kanye ne-num_stages) ngokusebenzisa amaphethini okufinyelela kumemori (imithwalo ehlanganisiwe, ukulanda kuqala kwesofthiwe, ukuswayipha kwe-L2), ukulungiselelwa kwekhompyutha (ukuqoqwa kwe-TF32, ukuhlanganiswa kwe-epilogue), amasu athuthukile (i-splittunes, i-warsisppeel, i-warsisppeel amasu aqondene nezakhiwo (i-TMA ku-Hopper, i-cp.async ku-Ampere, osayizi abalungisiwe be-L4/RTX), futhi ekugcineni ama-algorithms aqondene ne-kernel afana ne-softmax eku-inthanethi ukuze inakwe kanye ne-algorithm ye-Welford yokujwayela. Idokhumenti yomyalelo ihlanganisa ngamabomu ukuze umenzeli akwazi ukusebenza amahora angu-10+ ngaphandle kokubambeka.
Ukwenza Iphrofayela Okokuqala, Ukulungiselela Lapho Okubalulekile
Ngokungafani nomsebenzi wangaphambilini ophatha izinkinga ze-kernel ngokuhlukana, i-AutoKernel iqala kumodeli ephelele ye-PyTorch. Isebenzisa i-torch.profiler enokurekhoda komumo ukuze ithwebule isikhathi se-GPU ye-kernel ngayinye, bese ilinganisa okuqondiwe kokuthuthukisa usebenzisa umthetho we-Amdahl – isimiso sezibalo sokuthi ukusheshisa okuphelele ongasifinyelela kunqunyelwe ukuthi singakanani isikhathi esiphelele esimele leyo ngxenye. I-speedup engu-1.5× ku-kernel edla u-60% wesamba sesikhathi sokusebenza kukhiqiza inzuzo yokugcina engu-1.25× ekupheleni. Ukusheshisa okufanayo ku-kernel edla u-5% wesikhathi sokusebenza kukhiqiza kuphela i-1.03×.
Iphrofayili ithola ihadiwe ye-GPU kusizindalwazi semininingwane eyaziwayo ehlanganisa kokubili i-NVIDIA (H100, A100, L40S, L4, A10, RTX 4090/4080/3090/3080) kanye ne-AMD (MI300X, MI325X, MI350X, MI355X a). Kuma-GPU angaziwa, ilinganisela inani eliphakeme le-FP16 eliphuma ekubalweni kwe-SM, izinga lewashi, namandla okwenza ikhompuyutha – okwenza uhlelo lusetshenziswe kulo lonke uhla olubanzi lwehadiwe kunokunikezwa kwakamuva kwe-NVIDIA.
I-orchestrator (orchestrate.py) ishintsha isuka ku-kernel eyodwa iye kwelandelayo lapho noma yiziphi izimo ezine kuhlangatshezwana nazo: ukubuyiselwa okuhlanu okulandelanayo, u-90% wokusetshenziswa okuphezulu kwe-GPU okufinyelelwe, isabelomali sesikhathi esidlulile samahora amabili, noma isivinini esingu-2× esivele sizuziwe kuleyo kernel. Lokhu kuvimbela umenzeli ukuthi angachithi isikhathi esiningi kuma-kernel anembuyiselo enciphayo kuyilapho okuqondiwe komthelela ophezulu kulindile.
Izibopho Zokulunga Zezigaba Ezinhlanu
Ukusebenza ngaphandle kokunemba akusizi, futhi i-AutoKernel icophelela kakhulu kulokhu. Yonke i-kernel yekhandidethi idlula ezigabeni ezinhlanu zokuqinisekisa ngaphambi kokuthi kuqoshwe noma yikuphi ukusheshisa. Isigaba 1 senza ukuhlolwa kwentuthu kokokufaka okuncane ukuze kubanjwe amaphutha okuhlanganiswa kanye nokuma okungafani ngaphansi kwesekhondi. Isiteji sesi-2 sishanela ekulungiseni okokufaka okungu-8 kuye kwayi-10 kanye nezinhlobo ezintathu zedatha – FP16, BF16, ne-FP32 – ukuze sibambe iziphazamisi ezincike kusayizi njengokuphatha umngcele kanye nokucabanga okusele kwethayela. Isiteji sesi-3 sihlola ukuqina kwezinombolo ngaphansi kokokufaka kwe-adversarial: ku-softmax, imigqa yamanani amakhulu afanayo; ku-matmul, uhla oluguquguqukayo ngokwedlulele; ngokujwayelekile, ukuhluka okusondele kuqanda. Isiteji sesi-4 siqinisekisa i-determinism ngokusebenzisa okokufaka okufanayo izikhathi ezintathu futhi sidinga okuphumayo okufana kancane kancane, okubamba izimo zomjaho ekuncishisweni okuhambisanayo nama-athomu anganqumeli. Isiteji sesi-5 sihlola izilinganiso ezingewona amandla-okubili njengo-1023, 4097, kanye no-1537 ukuze kudalule iziphazamisi zokufihla ubuso namaphutha asele ethayela.
Ukubekezelela kuncike ku-dtype-specific: I-FP16 isebenzisa i-atol = 10⁻², i-BF16 isebenzisa 2 × 10⁻², futhi i-FP32 isebenzisa 10⁻⁴. Ekuhloleni okuphelele kwephepha kukho konke ukulungiselelwa okungu-34 ku-NVIDIA H100, bonke abangu-34 baphase ukulunga ngokuhluleka okuyiziro kuyo yonke imiphumela enomdlandla, ehlanganisiwe, nengokwezifiso.
I-backend ekabili: i-Triton ne-CUDA C++
I-AutoKernel isekela kokubili okungemuva kwe-Triton ne-CUDA C++ ngaphakathi kohlaka olufanayo. I-Triton iwulimi oluthize olufana nesizinda se-Python oluhlanganisa i-JIT ngesekhondi elingu-1 ukuya kwangu-5, okuyenza ifaneleke ukuphindaphinda ngokushesha — umenzeli angashintsha osayizi bebhulokhi, ukubalwa kwe-warp, izigaba zamapayipi, ukunemba kwe-accumulator, nokwakheka kweluphu. I-Triton ngokuvamile ifinyelela ku-80 kuya ku-95% we-cuBLAS throughput ye-matmul. I-CUDA C++ ifakwe emacaleni adinga ukufinyelela okuqondile kwama-primitives e-warp-level, imiyalelo ye-WMMA tensor core (usebenzisa izingcezu eziyi-16×16×16), imithwalo evezwayo nge-float4 ne-half2, izakhiwo zememori ezabiwe ezingenazo izingxabano, kanye nokubhafa kabili. Kokubili okungemuva kuveza isixhumi esibonakalayo se-kernel_fn(), ngakho ingqalasizinda yebhentshimakhi isebenza ngokufanayo kungakhathaliseki ukuthi i-backend.
Uhlelo luhlanganisa izinhlobo eziyisishiyagalolunye ze-kernel ezihlanganisa imisebenzi evelele ekwakhiweni kwe-transformer yesimanje: matmul, flash_attention, fused_mlp, softmax, layernorm, rmsnorm, cross_entropy, rotary_embedding, kanye nokunciphisa. Ngayinye inokusetshenziswa kwereferensi ye-PyTorch ku-reference.py esebenza njenge-oracle elungile, futhi ibhentshimakhi ibala ukuphuma ku-TFLOPS noma i-GB/s eduze nokusetshenziswa komugqa wophahla ngokumelene nenani eliphakeme le-GPU elitholiwe.
Imiphumela yeBenchmark ku-H100
Kukalwe ku-NVIDIA H100 80GB HBM3 GPU (132 SMs, compute capability 9.0, CUDA 12.8) ngokumelene ne-PyTorch eager kanye ne-torch.compile nge-max-autotune, imiphumela yezinhlamvu eziboshwe kwimemori ibalulekile. I-RMSNorm ifinyelela ku-5.29× ngokulangazela nokungu-2.83× ngaphezulu kwetoshi.hlanganisa ngosayizi omkhulu ohloliwe, ifinyelela ku-2,788 GB/s — 83% we-H100's 3,352 GB/s yomkhawulokudonsa ophezulu. I-Softmax ifinyelela ku-2,800 GB/s nge-speedup engu-2.82× ngokulangazela kanye no-3.44× phezu kwe-torch.compile. I-Cross-entropy ifinyelela ku-2.21× ngokulangazela kanye no-2.94× phezu kwe-torch.compile, ifinyelela ku-2,070 GB/s. Izinzuzo kulawa ma-kernels zivela ekuhlanganiseni ukubola kwe-ATen okune-multi-operation ibe yizinhlamvu ze-Triton ezine-pass eyodwa ezinciphisa ithrafikhi ye-HBM (High Bandwidth Memory).
I-AutoKernel idlula i-torch.hlanganisa kokungu-12 kwezingu-16 ezimele ezibekwe uphawu ephepheni, naphezu kwe-torch.ihlanganisa ne-max-autotune esebenzisa eyakho i-Triton autotuning. I-TorchInductor's generic fusion kanye ne-autotuning ayihlali ithola amasu akhethekile okufaka amathayela nokunciphisa asetshenziswa ukusetshenziswa okuqondene ne-kernel.
I-Matmul ilukhuni ngokuphawulekayo – I-backend ye-cuBLAS ye-PyTorch ishunwe kabanzi ngesakhiwo ngasinye se-GPU. I-Triton starter ifinyelela ku-278 TFLOPS, ngaphansi kwe-cuBLAS. Nokho, ngosayizi we-2048³, i-AutoKernel ishaya i-torch.compile ngo-1.55×, okubonisa ukuthi i-matmul autotuning ye-TorchInductor ayihlali ilungile futhi. Ukuvala igebe le-cuBLAS kusewumgomo oyinhloko wokuphindaphinda i-ejenti.
Ekuphakanyisweni komphakathi, i-kernel eyenziwe kahle ye-AutoKernel ithathe indawo yokuqala kubhodi yabaphambili ye-vectorsum_v2 B200 ene-latency engu-44.086µs, isebenze kahle kakhulu ngokungena endaweni yesibili ngo-44.249µs nendawo yesithathu ku-46.553µs. Umsebenzisi womphakathi uphinde wabika ukuthi ukwaziswa okukodwa kwe-AutoKernel – okudinga cishe imizuzu emithathu yokusebenzisana kwe-ejenti – kukhiqize i-Triton FP4 matrix yokuphindaphinda ikernel edlula i-CUTLASS ngo-1.63× kuya ku-2.15× kuzo zonke izimo eziningi ku-H100. I-CUTLASS imele ikhodi yesifanekiso ye-C++ eyenziwe kahle ngesandla eklanyelwe ama-NVIDIA tensor cores, okwenza lo mphumela uphawuleke ngokukhethekile.
Okuthathwayo Okubalulekile
- I-AutoKernel iguqula amaviki e-GPU engochwepheshe ibe inqubo yokuzimela ebusuku. Ngomshini i-writ-benchmark-keep/revert loop onjiniyela be-kernel abangochwepheshe asebevele bayilandela, isistimu isebenzisa izivivinyo ezingu-300 kuya kwezingu-400 ngeseshini ngayinye yasebusuku ku-GPU eyodwa ngaphandle kokungenelela komuntu.
- Ukulunga akuxoxiswana ngakho ngaphambi kokuthi kuqoshwe noma yikuphi ukusheshisa. Yonke i-kernel yekhandidethi kufanele iphumelele ihhanisi elinezigaba ezinhlanu elimboza ukuhlolwa kwentuthu, umumo ushanela kuzo zonke izimo ezingu-10+, ukuzinza kwezinombolo ngaphansi kokufakwayo okuphikisayo, ukuqinisekiswa kwe-determinism, kanye nezimo ezingezona zomphetho ezimbili – ukususa ubungozi bomenzeli “wokwenza ngokugcwele” indlela yakhe emiphumeleni engalungile.
- Izinhlamvu eziboshelwe kwinkumbulo zibona izinzuzo ezinkulu kukho kokubili i-PyTorch elangazelela kanye ne-torch.compile. Ku-NVIDIA H100, i-AutoKernel's Triton kernels ifinyelela ku-5.29× ngokulangazela ngaphezu kwe-RMSNorm, 2.82× ku-softmax, kanye no-2.21× ku-cross-entropy – ngezinzuzo ezitholakala ngokuhlanganisa ukusebenza okuningi kwe-ATen ukubola kube yizinhlamvu ze-single-pass ezinciphisa ithrafikhi ye-HBM.
- Umthetho ka-Amdahl ushayela lapho umenzeli echitha isikhathi sawo. Kunokuba ithuthukise izinhlamvu zodwa, i-AutoKernel iphrofayili yonke imodeli ye-PyTorch futhi yabela umzamo ngokulingana nesabelo se-kernel ngayinye sengqikithi yesikhathi sokusebenza se-GPU – iqinisekisa ukuthi ukuthuthukiswa kuhlanganiswe ezingeni lemodeli, hhayi nje izinga le-kernel.
Hlola Iphepha futhi I-Repo. Futhi, zizwe ukhululekile ukusilandela Twitter futhi ungakhohlwa ukujoyina wethu 120k+ ML SubReddit futhi Bhalisela ku Iphephandaba lethu. Linda! ukutelegram? manje ungasijoyina kuthelegramu futhi.
Udinga ukusebenzisana nathi ekuthuthukiseni i-GitHub Repo yakho NOMA Ikhasi Lobuso Lokugona NOMA Ukukhishwa Komkhiqizo NOMA I-Webinar njll.? Xhuma nathi
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


