
This year, I published an industry report called Remediation at Scale analyzing how application security (AppSec) teams are remediating vulnerabilities in their code. Dataset: tens of thousands of databases, a full year of scan data, and organizations from startups to enterprises. In total, north of 127 million data points include individual findings, scan events, and corrective actions across two types of security scans (SAST and SCA).
I am a Senior Technical PMM at Semgrep with a background in computer science, data science, and solutions engineering. I like to build things. This project allowed me to put all that together in one go: writing SQL, creating scripts to manage the analysis, analyzing and cleaning the data, finding the story the data tells, and shipping the final polished product.
This post goes over five lessons I've picked up along the way. If you've ever had to take a large data set, find a narrative within it, and make it something that a technical and non-technical audience can take action on, some of these might be useful.
1. Start with the data, not the story
The temptation with any data project is to decide your narrative first, then go find the numbers to back it up. I do the opposite.
I spent weeks in pure test mode. It asks Snowflake, looking at the distribution, using the combination of different dimensions. No hypothesis, no angle. Just trying to understand what the data actually showed.
This was uncomfortable. Stakeholders wanted to know what the report would say. I still haven't received an answer.
But it was the most important phase of the whole project. The data told a story I wouldn't have guessed: the gap between the best-performing security teams and everyone else wasn't about implementation. It was about systematic maintenance tracking. I wouldn't have gotten to that point if I started with a thesis.
You must also be willing to kill your loved ones. There were several findings that I wanted to be true that the data did not support. On the other hand, some of the most interesting information comes from places I wasn't looking. I used local LLMs with Ollama to classify 10,000+ text-based triage records into 20 thematic categories. What emerged was a clear pattern: the most common themes were about test files, frame protection, and trusted services. That told a story about how teams actually use triage tools that I wouldn't have found by looking at aggregated metrics.
A few things that helped during testing:
- Run the diagnostic questions first. I built a set of 12+ data quality tests before touching on the analysis. One of them holds that the key metric (parse_rate) is only included in a small part of the repos. I switched to another field (NUM_BYTES_SCANNED) which has 90%+ coverage. Without that diagnosis, every analysis found on each line of code would be incorrectly computed.
- Create a checkpoint/restart in your pipeline. I had 108+ SQL queries across multiple report categories. I wrote a shell script that automatically found the .sql files, tracked which ones already generated CSV output, and skipped them on restart. When queries fail in the middle (and they do), I can pick up where I left off instead of starting everything over.
- Document as you go. All the exciting results, all the dead ends, all the speculation. That active log became the backbone of the report's how-to section and saved me weeks when I needed to retrace my steps.
2. Become a domain expert
You can't tell a story with data you don't understand. Before I could write a single paragraph, I needed to know how static analysis scans work, how the remediation flow works in practice, and what metrics are important to security teams.
Several aerospace companies publish annual reports on similar topics. I collected and learned as much as I could. Not copying, but understanding the format, depth, and expectations. Reading them gave me the idea that:
- What the industry expects from this type of resource
- What has been covered well
- Where there is room to say something new
This also helped me spot the gaps. Most reports focus on acquisition volume. Very few grasp what happens after adoption. That was our angle.
Skipping this section would have meant writing a report full of high-quality observations that were not separated from other good content produced by others.
3. Talk to your target audience early and often
Earlier versions of the analysis just showed averages. Average repair rate, average repair time, recovery rate per repo. The numbers were right. The story was boring.
The breakthrough came after talking to real employees: security engineers, AppSec leads, and CISOs who will be learning the final product. Everyone wanted to answer one question: How do I compare to teams that do this well?
That response directly shaped two major decisions in the report.
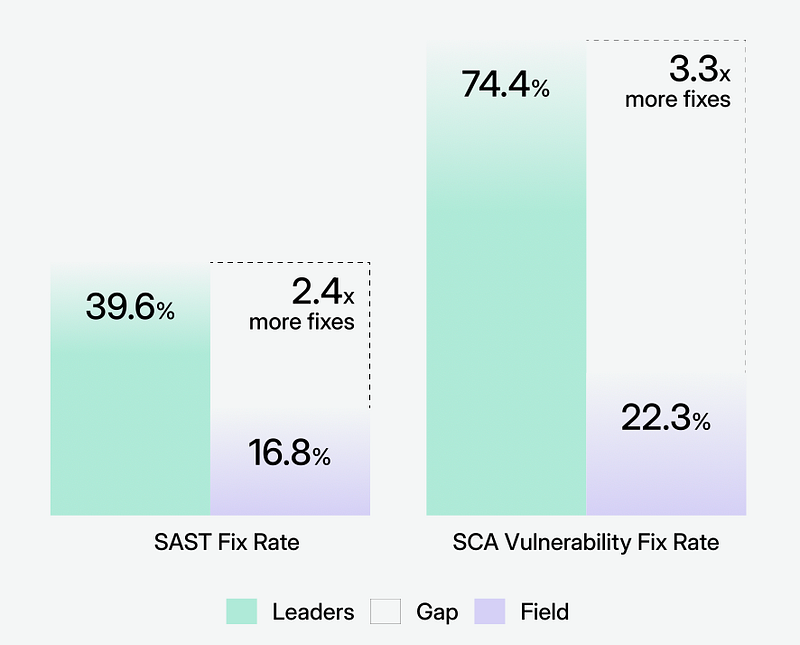
First, it led to group-based segregation. I divided the organizations into two groups: the top 15% by repair rate (“leaders”) and everyone else (“the field”). This is similar to the method of segmenting survey-based reports by developmental level, except that I was using behavioral data rather than self-reported responses. The data soon became inconsistent:
- Leaders fix 2–3 times more risk
- They resolve finds caught during code reviews 9x faster than finds from full repository scans
- They use automated workflow features at higher rates and extract more value from them
The segment was the difference between “here are the numbers” and “here is something you can do.”
Second, reshape the structure of the report. People didn't just want benchmarks. They wanted to know what to do with them. “Great, the leadership team fixes a lot of code security vulnerabilities. How do I become a leader?” That response led me to add an evidence-based recommendations section organized by implementation speed:
- This week's quick win
- Process changes this quarter
- Strategic investment in the segment
The final report is like a playbook as you make the estimate. None of this would have been possible without putting the previous draft in front of real readers.
4. Get the design involved early
I almost read this one too late. Data reports live or die by how they look. A wall of charts with no visual hierarchy is as bad as no data at all.
I brought our design team in earlier than I could have done and spent time with them on site. What does “accessibility analysis” mean? Why does the group split up? When designers understand the story, they make choices (color coding of groups, callout boxes for important details, before/after code examples) that emphasize it without me explaining it in text.

5. Take your time
This work took months. Data testing alone was weeks. Then there is iteration in the analysis as I get new angles, design cycles, legal reviews, and feedback from stakeholders across the company.
If I had tried to post this in a quarter, the result would have been forgotten.
Where he arrived
Looking back, the two things I would change are both about speed. I will write down all the explanations and considerations on the first day. Things like “what counts as a working cache” or “how do we calculate the maintenance rate” seem obvious at first. They quickly argued. In the end I created a formal definitions document covering 40+ metrics, but doing it earlier would have saved several rounds of rework. And I brought a second set of eyes during the test. Working alone meant that no one would check whether the findings were interesting or just noisy.
The report itself, Remediation at Scale, includes six evidence-backed patterns that distinguish high-performing security teams from others. If you've ever tackled a similar data-heavy reporting project, I'd be curious to hear what you learned along the way.



