Speed up custom LLM deployments: Fine-tune with Oumi and ship to Amazon Bedrock

This post was written by David Stewart and Matthew Persons from Oumi.
Optimizing large open source language models (LLMs) often stops between testing and production. Training configurations, artifact management, and scaling applications each require different tools, creating friction when moving from rapid testing to secure, enterprise-grade environments.
In this post, we show how to fine-tune the Llama model using Oumi on Amazon EC2 (with the option to create synthetic data using Oumi), store the artifacts in Amazon S3, and export them to Amazon Bedrock using Custom Model Import for managed deployment. Although we are using EC2 for this walkthrough, optimization can be completed on other compute services such as Amazon SageMaker or Amazon Elastic Kubernetes Service, depending on your needs.
Advantages of Oumi and Amazon Bedrock
Oumi is an open source system that simplifies the lifecycle of a basic model, from data preparation and training to testing. Instead of combining different tools for each stage, you define a single configuration and reuse it for every run.
Key benefits of this app:
- Recipe driven training: Define your configuration once and reuse it for all spells, reducing boilerplate and improving reproducibility
- Variable configuration: Choose efficient or effective repair methods like LoRA, based on your constraints
- Combined assessment: Score using benchmarks or LLM-as-a-judge without additional usage
- Data integration: Generate task-specific data sets when production data is limited
Amazon Bedrock complements this by offering a managed, server-less directory. After fine-tuning with Oumi, you import your model by importing a Custom Model in three steps: upload to S3, create an import job, and request. There is no infrastructure to manage. The following schematic diagram shows how these components work together.
Figure 1: Oumi hosts data, training, and testing on EC2. Amazon Bedrock offers managed views with Custom Model Import.
Solution overview
This application has three sections:
- Harvest well with I'm standing on EC2: Launch an instance configured for GPU (for example, g5.12xlarge or p4d.24xlarge), install Oumi, and start training with your configuration. For larger models, Oumi supports distributed training with Fully Sharded Data Parallel (FSDP), DeepSpeed, and Distributed Data Parallel (DDP) techniques across multiple GPUs or multiple nodes.
- Store artifacts in S3: Upload model weights, checkpoints, and logs for long-term storage.
- Submit on Amazon Bedrock: Create a Custom Model Import function that points to your S3 artifacts. Amazon Bedrock provides directory infrastructure automatically. Client applications call the imported model using the Amazon Bedrock Runtime APIs.
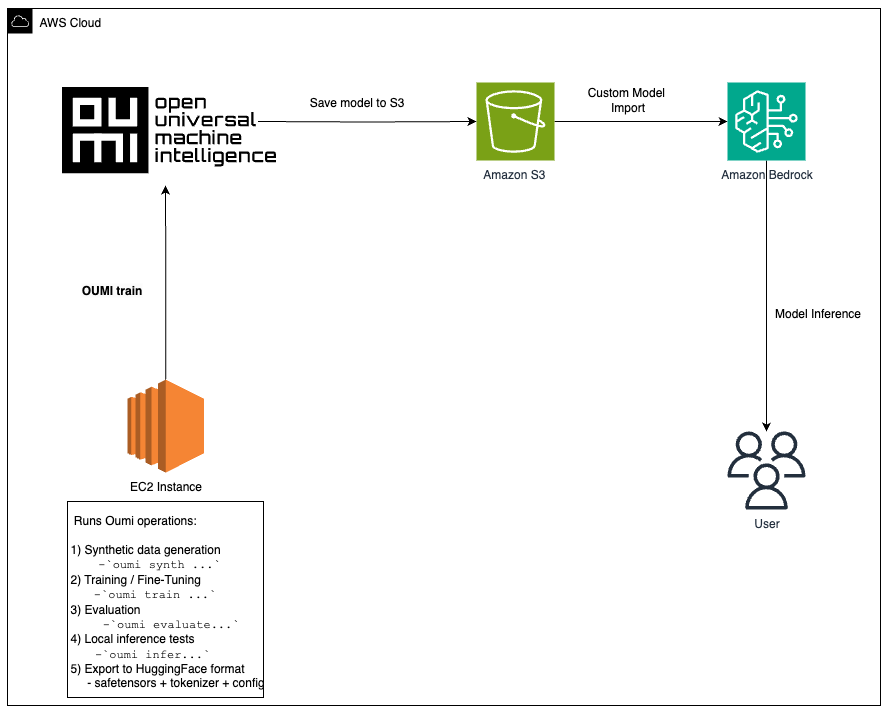
This architecture addresses common challenges in moving fine-tuned models to production:
Technology implementation
Let's go through a hands-on approach using the meta-llama/Llama-3.2-1B-Yala model as an example. While we chose this model as it is well suited and well configured in AWS g6.12xlarge For the EC2 example, the same workflow can be repeated for all other open source models (note that larger models may require larger instances or distributed training across instances). For more information, see Oumi's fine-tuning cooking model and Amazon Bedrock's custom model layouts.
What is required
To complete this application, you need:
Set up AWS services
- Compile this repository on your local machine:
git clone
cd sample-oumi-fine-tuning-bedrock-cmi- Run the setup script to create the IAM roles, S3 bucket, and launch the GPU-optimized EC2 instance:
./scripts/setup-aws-env.sh [--dry-run]The script is informed of your AWS region, S3 bucket name, EC2 key pair name, and security group ID, and creates all the necessary resources. Default: g6.12xlarge instance, Deep Learning Base AMI with One CUDA (Amazon Linux 2023), and 100 GB gp3 storage. Note: If you do not have permissions to create IAM roles or launch EC2 instances, share this repository with your IT administrator and ask them to complete this section to set up your AWS environment.
- Once the example is running, the script issues an SSH command and the Amazon Bedrock import role ARN (required in step 5). SSH into the instance and continue with step 1 below.
See iam/README.md for IAM policy details, scope guidance, and validation steps.
Step 1: Set up an EC2 environment
Complete the following steps to set up the EC2 environment.
- In the case of EC2 (Amazon Linux 2023), update the system and install the basic dependencies:
sudo yum update -y
sudo yum install python3 python3-pip git -y- Compile a companion repository:
git clone
cd sample-oumi-fine-tuning-bedrock-cmi- Configure the environment variables (replace the values with your actual region and bucket name from the setup script):
export AWS_REGION=us-west-2
export S3_BUCKET=your-bucket-name
export S3_PREFIX=your-s3-prefix
aws configure set default.region "$AWS_REGION"- Run the setup script to create a virtual Python environment, install Oumi, verify GPU availability, and configure Hugging Face authentication. See setup-environment.sh for options.
./scripts/setup-environment.sh
source .venv/bin/activate- Confirm with Hugging Face to achieve gated model weights. Generate an access token at huggingface.co/settings/tokens, and run:
hf auth loginStep 2: Prepare the training
The default dataset is tatsu-lab/alpaca, configured in configs/oumi-config.yaml. Oumi downloads it automatically during training, no manual download required. To use a different dataset, update the i dataset_name parameter in configs/oumi-config.yaml. See the Oumi dataset documentation for supported formats.
[Optional] Generate synthetic training data with Oumi:
To generate synthetic data using Amazon Bedrock as a backend, update the model_name placeholder in configs/synthesis-config.yaml with the ID of an Amazon Bedrock model you can access (eg anthropic.claude-sonnet-4-6). See the Oumi data synthesis documentation for details. Then run:
oumi synth -c configs/synthesis-config.yamlStep 3: Adjust the model
Adjust the model using Oumi's built-in training recipe for Llama-3.2-1B-Instruct:
./scripts/fine-tune.sh --config configs/oumi-config.yaml --output-dir models/final [--dry-run]To customize the parameters, edit oumi-config.yaml.
Note: If you generated synthetic data in step 2, review the data set method in preparation before training.
Monitor GPU usage with nvidia-smi or Amazon CloudWatch Agent. For long-running operations, configure Amazon EC2 Automatic Instance Recovery to handle interruptions.
Step 4: Estimate the model (Optional)
You can test a well-configured model using standard benchmarks:
oumi evaluate -c configs/evaluation-config.yamlThe test configuration specifies the method of the model and the benchmark functions (eg, MMLU). To customize, edit evaluation-config.yaml. For LLM-as-a-judge methods and additional benchmarks, see Oumi's assessment guide.
Step 5: Submit to Amazon Bedrock
Complete the following steps to submit a model to Amazon Bedrock:
- Upload the model artifacts to S3 and import the model to Amazon Bedrock.
./scripts/upload-to-s3.sh --bucket $S3_BUCKET --source models/final --prefix $S3_PREFIX
./scripts/import-to-bedrock.sh --model-name my-fine-tuned-llama --s3-uri s3://$S3_BUCKET/$S3_PREFIX --role-arn $BEDROCK_ROLE_ARN --wait- The import script outputs the ARN model on completion. Set up
MODEL_ARNin this value (format:arn:aws:bedrock:).: :imported-model/ - Request a model from Amazon Bedrock
./scripts/invoke-model.sh --model-id $MODEL_ARN --prompt "Translate this text to French: What is the capital of France?"- Amazon Bedrock creates a mobile environment for automated thinking. For IAM role setup, see bedrock-import-role.json.
- Enable the S3 version of the bucket to support rollback of model updates. For SSE-KMS encryption and bucket policy robustness, see the security documentation in the companion repository.
Step 6: Clean
To avoid ongoing costs, remove resources created during this move:
aws ec2 terminate-instances --instance-ids $INSTANCE_ID
aws s3 rm s3://$S3_BUCKET/$S3_PREFIX/ --recursive
aws bedrock delete-imported-model --model-identifier $MODEL_ARNThe conclusion
In this post, you learned how to properly tune the Llama-3.2-1B-Instruction base model using Oumi on EC2 and deploy it using Amazon Bedrock Custom Model Import. This approach gives you full control over the fine-tuning of your data while using managed inference on Amazon Bedrock.
The sample-oumi-fine-tuning-bedrock-cmi repository provides documentation, configuration, and IAM policies to get you started. Combine it, exchange your data, and run a custom model on Amazon Bedrock.
To get started, check out the resources below and start building your own optimization pipeline for deployment on Oumi and AWS. Fun layout!
Read more
To agree
Special thanks to Pronoy Chopra and Jon Turdiev for their contribution.
About the writers


