A new Google Ai's Region Model (RLM) framework makes the industrial system predict the industrial system directly from the green text data
 framework makes the industrial system predict the industrial system directly from the green text data")
The new method of new Google (RLM) is enabling industrial systems (llMs) to predict the industrial system directly from green text data, without leaning on complex engineering or tabor formats.
Challenge for predicting industrial program
Predurating the performance of large industrial programs – such as cultural computers and traditions – is traditionally necessary for the engineering features of specialized features of the Actuoning and Tabrar, making flexibility and adaptability. Logs, Configuration files, variable mixing, and integrated activity details cannot be easily taken or made of normal classical registro models. As a result, efficiency and transmission of work is usually Brittle, it is expensive, and a little, especially when launching new types of work or hardware.
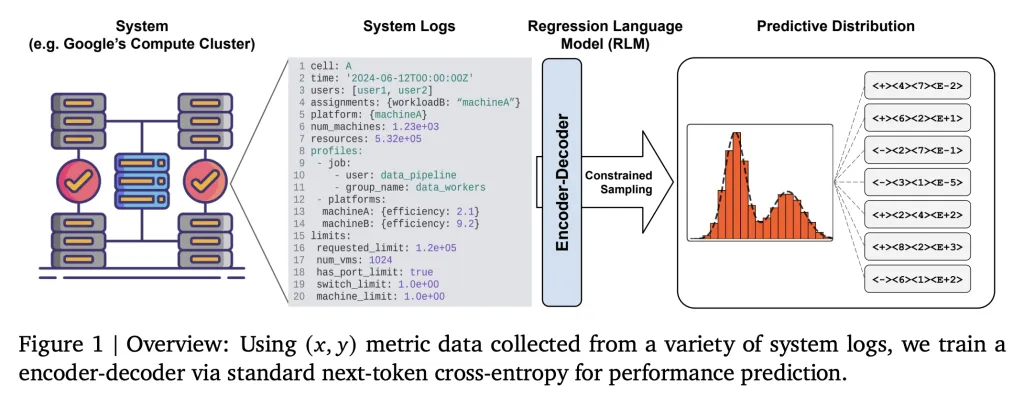
The main idea: Text-To-Text Regression
Google Regression Language (RLM) modifies the Regression as a Scriptural status activity: All details of the System (Configuration, Works, Hardware Profiles) are included in the formal XXX defects. Lyy replacement model
- No numeric features of tabar: This eliminates the need for a pre-defined feature set, general, and solid code applications.
- Universalization of the universe: Any condition is not represented as a rope; Heterogeneous, with characteristics that appeared, or flexible are supported.
Technical Information: Properties and Training
This method uses the Encoder-Decoder of the small (60m) encoder training with the loss of the following-token entropy angropy at the ropes of xxx and yyy. The model is not available in the general language of copying – training can start in random implementation, focusing directly on the consequences of the NUMERIC communications system.
- Custom Mucic Tokozation: The results are well received (eg
- A number of conversion RLMS is available faster in new jobs that have a few examples as 500 examples, adapt to new collections or months within hours, not weeks.
- Consumer estimate: Models can process the longest installation documents (thousands of tokens), to ensure complex nations are completely seen.
Working: It results in Borgus Cluster
Examination in the Borg Cluster, RLMS reached on 0.99 Spearman position test (0.9 Average) Between predicted and the fact of GCU with GCU, with A lower 100x fault There are Tabular foundations. Models preferred uncertainty in sample of more submission to each installation, supporting the projecting of the probabilistic function
- Uncertainty Diminity: RLMS take both of these aleaateoric (natural) and epistemic (unknown due to limited recognition) uncertainty, unlike the black box ragger.
- Simulators Universal: The power of the Density RLMS suggests its use in creating a 1-year digitist of large programs, accelerating the functioning of infrastructure, and the actual response.
Comparison: RLMS VS REGRISION NAME
| Advance | Data format | Engineering feature | Alienate | Performance | Uncertainty |
|---|---|---|---|---|---|
| Tangayal Return | Pets, numbers | The manual is required | Low | Limited with features | Notexual |
| Rlm (text-to-text) | Organized, Schedulable Text | Nothing is needed | Excessive | Values nearby | The full spectrum |
Applications and abbreviation
- Cloud oil and computer: Directorcycling for performance and efficiency of great, moving infrastructure.
- Manufacturing and IT: The Universal Universal Focord Sumulators to predict various industrial pipes.
- Scientific examination: The end models of the end where the provinces of installation are complex, statistically defined, and diversity.
This new language adjustments – removing memorable obstacles to Simulation, and it helps a quick prediction of new areas, and supports uncertainty forecasts, all the key to the next industrial AI.
Look Paper, codes and technical details. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.

Michal Sutter is a Master of Science for Science in Data Science from the University of Padova. On the basis of a solid mathematical, machine-study, and data engineering, Excerels in transforming complex information from effective access.



