Large-scale linguistic models (MLLMS) are increasingly deployed in real-world, agentic settings where the output must not only be correct, but also agree with predefined data decisions. Despite recent progress in systematic generation in the textual domain, there is still no mkarkmark that systematically examines the extraction of schema information and consultation through visual input. In this work, we conduct a comprehensive study of the output capabilities of MLLMS with our carefully designed benchmark. Covering four visual domains, including UI screens, natural images, documents, and charts, the bench is built from more than 6.5k different The models of measurement of bitter and fried models reveal persistent gaps in predicting consistent results, of available schema, highlighting the need for better multimodal consultation. Regardless of observation, we continue to conduct training exercises to significantly improve the effectiveness of systematic evacuation. We plan to make the bench available to the public.
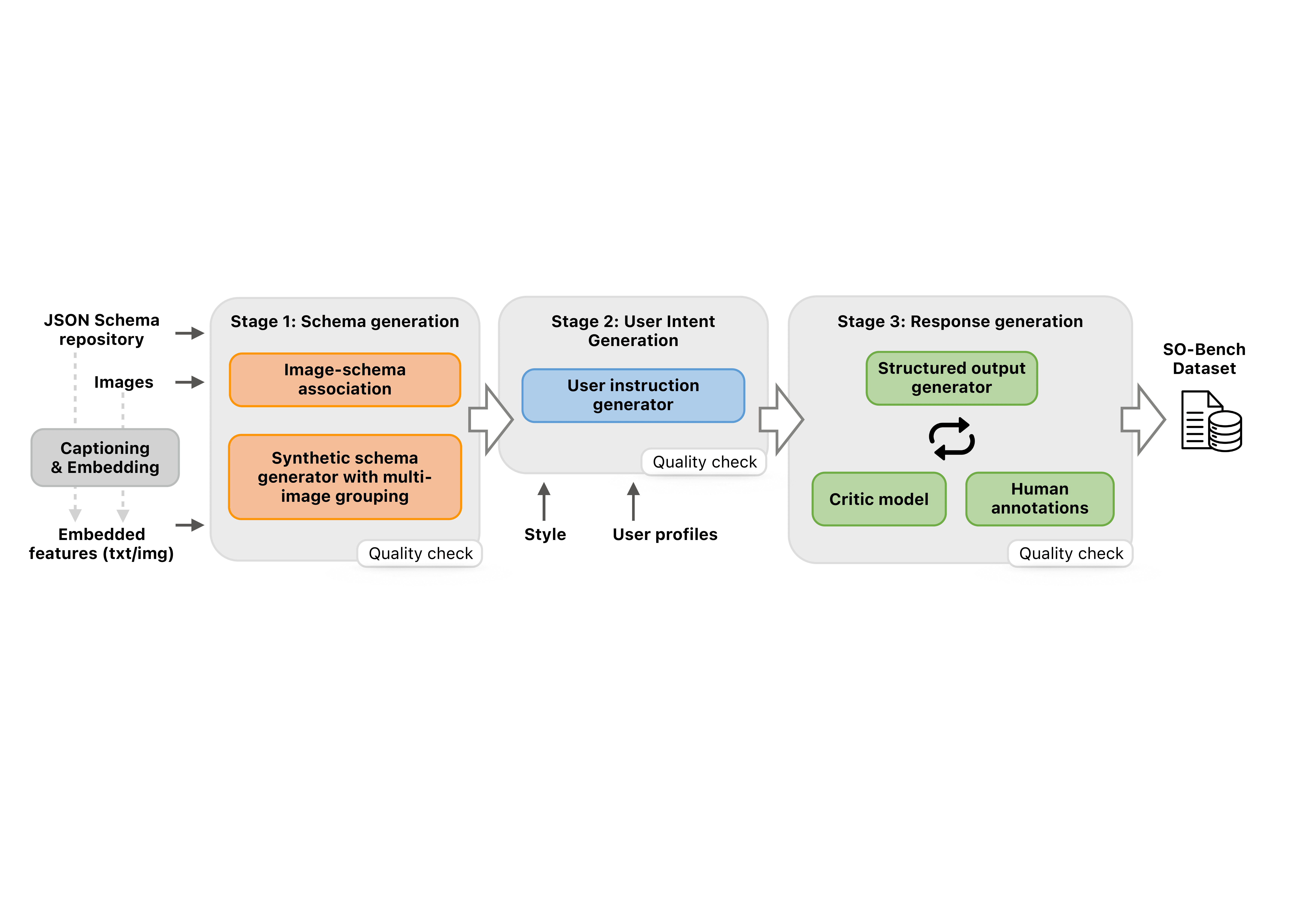
Figure 1: Left: An overview of the Shench bench's multi-database data generation pipeline, including schema generation, user residual generation, and response stages. In each category, the proprientier Frontier models such as GPT-5 and Gemini-2.5-Pro as a generator with carefully designed incentives. Human resource specialists review data from each stage before progressing to the next. Before schema generation, input images and JONSON Schemas are entered using the search Clip model. Right: Results of benchmarking between open top models and proprietary Frontier models.
Figure 2: Overview of So-Bench's Multi-Stag Generation data generation pipeline, including schema generation, user residual generation, and feedback stages. In each category, the proprientier Frontier models such as GPT-5 and Gemini-2.5-Pro as a generator with carefully designed incentives. Human resource specialists review data from each stage before progressing to the next. Before schema generation, input images and JONSON Schemas are entered using the search Clip model.