
How can healthcare decisions become more accurate when patient data is scattered across reports, images, and monitoring systems?
Despite advances in artificial intelligence, most healthcare AI tools still operate in silos, limiting their real-world impact, and this is where the Multimodal AI addresses this gap by integrating multiple data types, such as clinical text, medical imaging, and physiological signals into a unified intelligence framework.
In this blog, we explore how multimodal AI is transforming healthcare by enabling more context-aware diagnostics, personalized treatment strategies, and efficient clinical workflows, while also highlighting why it represents the next frontier for healthcare.
Summarize this article with ChatGPT
Get key takeaways & ask questions
What is Multimodal AI?
Multimodal AI refers to artificial intelligence systems designed to process and integrate multiple types of data simultaneously. Multimodal AI can interpret combinations of data types to extract richer, more contextual insights.
In healthcare, this means analyzing clinical notes, medical images, lab results, biosignals from wearables, and even patient-reported symptoms together rather than in isolation.
By doing so, multimodal AI enables a more accurate understanding of patient health, bridging gaps that single-modality AI systems often leave unaddressed.
Core Modalities in Healthcare
- Clinical Text: This includes Electronic Health Records (EHRs), structured physician notes, discharge summaries, and patient histories. It provides the “narrative” and context of a patient’s journey.
- Medical Imaging: Data from X-rays, MRIs, CT scans, and ultrasounds. AI can detect patterns in pixels that might be invisible to the human eye, such as minute textural changes in tissue.
- Biosignals: Continuous data streams from ECGs (heart), EEGs (brain), and real-time vitals from hospital monitors or consumer wearables (like smartwatches).
- Audio: Natural language processing (NLP) applied to doctor-patient conversations. This can capture nuances in speech, cough patterns for respiratory diagnosis, or cognitive markers in vocal tone.
- Genomic and Lab Data: Large-scale “Omics” data (genomics, proteomics) and standard blood panels. These provide the molecular-level ground truth of a patient’s biological state.
How Multimodal Fusion Enables Holistic Patient Understanding?
Multimodal fusion is the process of combining and aligning data from different modalities into a unified representation for AI models. This integration allows AI to:
- Capture Interdependencies: Subtle patterns in imaging may correlate with lab anomalies or textual observations in patient records.
- Reduce Diagnostic Blind Spots: By cross-referencing multiple data sources, clinicians can detect conditions earlier and with higher confidence.
- Support Personalized Treatment: Multimodal fusion allows AI to understand the patient’s health story in its entirety, including medical history, genetics, lifestyle, and real-time vitals, enabling truly personalized interventions.
- Enhance Predictive Insights: Combining predictive modalities improves the AI’s ability to forecast disease progression, treatment response, and potential complications.
Example:
In oncology, fusing MRI scans, biopsy results, genetic markers, and clinical notes allows AI to recommend targeted therapies tailored to the patient’s unique profile, rather than relying on generalized treatment protocols.
Architecture Behind Multimodal Healthcare AI Systems
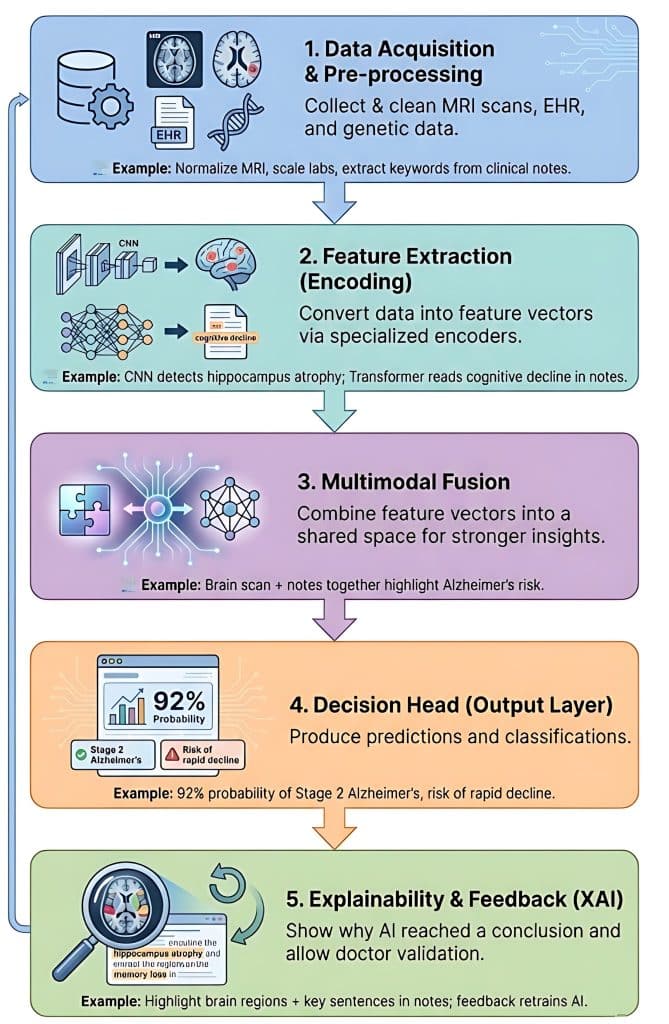
Building a multimodal healthcare AI system involves integrating diverse data types, such as medical images, electronic health records (EHRs), and genomic sequences, to provide a comprehensive view of a patient’s health.
To illustrate this, let’s use the example of diagnosing and predicting the progression of Alzheimer’s Disease.
1. Data Acquisition and Pre-processing
In this stage, the system collects raw data from various sources. Because these sources speak “different languages,” they must be cleaned and standardized.
- Imaging Data (Computer Vision): Raw MRI or PET scans are normalized for intensity and resized.
- Structured Data (Tabular): Patient age, genetic markers (like APOE4 status), and lab results are scaled.
- Unstructured Data (NLP): Clinical notes from neurologists are processed to extract keywords like “memory loss” or “disorientation.”
Each data type is sent through a specialized encoder (a neural network) that translates raw data into a mathematical representation called a feature vector. Example:
- The CNN encoder processes the MRI and detects “atrophy in the hippocampus.”
- The Transformer encoder processes clinical notes and identifies “progressive cognitive decline.”
- The MLP encoder processes the genetic data, flagging a high risk due to specific biomarkers.
3. Multimodal Fusion
This is the “brain” of the architecture. The system must decide how to combine these different feature vectors. There are three common strategies:
- Early Fusion: Combining raw features immediately (often messy due to different scales).
- Late Fusion: Each model makes a separate “vote,” and the results are averaged.
- Intermediate (Joint) Fusion: The most common approach, where feature vectors are projected into a shared mathematical space to find correlations.
- Example: The system notices that the hippocampal shrinkage (from the image) aligns perfectly with the low cognitive scores (from the notes), creating a much stronger “signal” for Alzheimer’s than either would alone.
4. The Decision Head (Output Layer)
The fused information is passed to a final set of fully connected layers that produce the specific clinical output needed. The Example: The system outputs two things:
- Classification: “92% probability of Stage 2 Alzheimer’s.”
- Prediction: “High risk of rapid decline within 12 months.”
5. Explainability and Feedback Loop (XAI)
In healthcare, a “black box” isn’t enough. The system uses an explainability layer (like SHAP or Attention Maps) to show the doctor why it reached a conclusion. Example:
The system highlights the specific area of the brain scan and the specific sentences in the clinical notes that led to the diagnosis. The doctor can then confirm or correct the output, which helps retrain the model.
As multimodal AI becomes central to modern healthcare, there’s a growing need for professionals who can combine clinical knowledge with technical expertise.
The Johns Hopkins University’s AI in Healthcare Certificate Program equips you with skills in medical imaging, precision medicine, and regulatory frameworks like FDA and HIPAA, preparing you to design, evaluate, and implement safe, effective AI systems. Enroll today to become a future-ready healthcare AI professional and drive the next generation of clinical innovation.
High-Impact Use Cases Showing Why Multimodal AI is The Next Frontier in Healthcare

1. Multimodal Clinical Decision Support (CDS)
Traditional clinical decision support (CDS) often relies on isolated alerts, such as a high heart rate trigger. Multimodal CDS, however, integrates multiple streams of patient information to provide a holistic view.
- Integration: It correlates real-time vital signs, longitudinal laboratory results, and unstructured physician notes to create a comprehensive patient profile.
- Early Detection: In conditions like sepsis, AI can identify subtle changes in cognitive state or speech patterns from nurse notes hours before vital signs deteriorate. In oncology, it combines pathology images with genetic markers to detect aggressive mutations early.
- Reducing Uncertainty: The system identifies and highlights conflicting data, for example, when lab results suggest one diagnosis but physical exams indicate another, enabling timely human review.
- Outcome: This approach reduces clinician “alarm fatigue” and supports 24/7 proactive monitoring, contributing to a measurable decrease in preventable mortality.
2. Intelligent Medical Imaging & Radiology
Medical imaging is evolving from simple detection (“What is in this image?”) to patient-specific interpretation (“What does this image mean for this patient?”).
- Context-Driven Interpretation: AI cross-references imaging findings with clinical data, such as patient history, prior biopsies, and documented symptoms, to provide meaningful insights.
- Automated Prioritization: Scans are analyzed in real-time. For urgent findings, such as intracranial hemorrhage, the system prioritizes these cases for immediate radiologist review.
- Augmentation: AI acts as an additional expert, highlighting subtle abnormalities, providing automated measurements, and comparing current scans with previous imaging to assist radiologists in decision-making.
- Outcome: This leads to faster emergency interventions and improved diagnostic accuracy, particularly in complex or rare conditions, enhancing overall patient care.
3. AI-Powered Virtual Care & Digital Assistants
AI-driven virtual care tools extend the reach of clinics into patients’ homes, enabling a “hospital at home” model.
- Holistic Triage: Virtual assistants analyze multiple inputs, voice patterns, symptom descriptions, and wearable device data to determine whether a patient requires an emergency visit or can be managed at home.
- Clinical Memory: Unlike basic chatbots, these systems retain detailed patient histories. For instance, a headache reported by a hypertension patient is flagged with higher urgency than the same symptom in a healthy individual.
- Continuous Engagement: Post-surgery follow-ups are automated, ensuring medication adherence, monitoring physical therapy, and detecting potential complications such as an infected surgical site before hospital readmission becomes necessary.
- Outcome: This approach reduces emergency department congestion, enhances patient compliance, and improves satisfaction through personalized, continuous care.
4. Precision Medicine & Personalized Treatment
Precision medicine shifts healthcare from a “one-size-fits-all” approach to treatments tailored to each patient’s molecular and clinical profile.
- Omics Integration: AI combines genomics, transcriptomics, and radiomics to construct a comprehensive, multi-dimensional map of a patient’s disease.
- Dosage Optimization: Using real-time data on kidney function and genetic metabolism, AI predicts the precise chemotherapy dosage that maximizes effectiveness while minimizing toxicity.
- Predictive Modeling: Digital twin simulations allow clinicians to forecast how a specific patient will respond to different treatments, such as immunotherapy versus chemotherapy, before therapy begins.
- Outcome: This strategy transforms previously terminal illnesses into manageable conditions and eliminates the traditional trial-and-error approach in high-risk therapies.
5. Hospital Operations & Workflow Optimization
AI applies multimodal analytics to the complex, dynamic environment of hospital operations, treating the facility as a “living organism.”
- Capacity Planning: By analyzing factors such as seasonal illness patterns, local events, staffing levels, and patient acuity in the ER, AI can accurately forecast bed demand and prepare resources in advance.
- Predicting Bottlenecks: The system identifies potential delays, for example, a hold-up in the MRI suite that could cascade into surgical discharge delay,s allowing managers to proactively redirect staff and resources.
- Autonomous Coordination: AI can automatically trigger transport teams or housekeeping once a patient discharge is recorded in the electronic health record, reducing bed turnaround times and maintaining smooth patient flow.
- Outcome: Hospitals achieve higher patient throughput, lower operational costs, and reduced clinician burnout, optimizing overall efficiency without compromising quality of care.
Implementation Challenges vs. Best Practices
| Challenge | Description | Best Practice for Adoption |
| Data Quality & Modality Imbalance | Discrepancies in data frequency (e.g., thousands of vitals vs. one MRI) and “noisy” or missing labels in clinical notes. | Use “Late Fusion” techniques to weight modalities differently and employ synthetic data generation to fill gaps in rarer data types. |
| Privacy & Regulatory Compliance | Managing consent and security across diverse data streams (voice, video, and genomic) under HIPAA/GDPR. | Train models across decentralized servers so raw patient data never leaves the hospital, and utilize automated redaction for PII in unstructured text/video. |
| Explainability & Clinical Trust | The “Black Box” problem: clinicians are hesitant to act on AI advice if they can’t see why the AI correlated a lab result with an image. | Implement “Attention Maps” that visually highlight which part of an X-ray or which specific sentence in a note triggered the AI’s decision. |
| Bias Propagation | Biases in one modality (e.g., pulse oximetry inaccuracies on darker skin) can “infect” the entire multimodal output. | Conduct “Subgroup Analysis” to test model performance across different demographics and use algorithmic “de-biasing” during the training phase. |
| Legacy System Integration | Most hospitals use fragmented EHRs and PACS systems that weren’t designed to talk to high-compute AI models. | Adopt Fast Healthcare Interoperability Resources (FHIR) APIs to create a standardized “data highway” between old databases and new AI engines. |
What’s Next for Multimodal AI in Healthcare?
1. Multimodal Foundation Models as Healthcare Infrastructure
By 2026, multimodal foundation models (FMs) will be the core intelligence layer of implementing AI in healthcare.
These models provide cross-modal representation learning across imaging, clinical text, biosignals, and lab data, replacing fragmented, task-specific AI tools.
Operating as a clinical “AI operating system,” they enable real-time inference, shared embeddings, and synchronized risk scoring across radiology, pathology, and EHR platforms.
2. Continuous Learning in Clinical AI Systems
Healthcare AI is shifting from static models to continuous learning architectures using techniques such as Elastic Weight Consolidation (EWC) and online fine-tuning.
These systems adapt to data drift, population heterogeneity, and emerging disease patterns while preventing catastrophic forgetting, ensuring sustained clinical accuracy without repeated model redeployment.
3. Agentic AI for End-to-End Care
Agentic AI introduces autonomous, goal-driven systems capable of multi-step clinical reasoning and workflow. Leveraging tool use, planning algorithms, and system interoperability, AI agents coordinate diagnostics, data aggregation, and multidisciplinary decision-making, significantly reducing clinician cognitive load and operational latency.
4. Adaptive Regulatory Frameworks for Learning AI
Regulatory bodies are enabling adaptive AI through mechanisms such as Predetermined Change Control Plans (PCCPs). These frameworks allow controlled post-deployment model updates, continuous performance monitoring, and bounded learning, supporting real-world optimization while maintaining safety, auditability, and compliance.
The next frontier of healthcare AI is cognitive infrastructure. Multimodal, agentic, and continuously learning systems will fade into the background—augmenting clinical intelligence, minimizing friction, and becoming as foundational to care delivery as clinical instrumentation.
Conclusion
Multimodal AI represents a fundamental shift in how intelligence is embedded across healthcare systems. By unifying diverse data modalities, enabling continuous learning, and care through agentic systems, it moves AI from isolated prediction tools to a scalable clinical infrastructure. The true impact lies not in replacing clinicians but in reducing cognitive burden, improving decision fidelity, and enabling faster, more personalized care.



