StepFun Ai Releases Step-Audio-R1: New AUDIO LLM Last End of Test Period

Why current audio ai models tend to do worse when they do long-term thinking instead of basing their decisions on the actual source. StepFun Research Team releases the step-audio-R1, a new audio LLM designed to close the testing period, to address this failure mode by showing that the decrease of the chain is not the limit of the sound but the problem of the training and the training and making the problem?
The basic problem is that the audio models reflect more than text surrogates
Many current audio models inherit their behavior through text training. They learn to communicate as if they are reading what is written, not as if they are listening. Stepkelen's group calls this text-based thinking. The model uses words and meanings that have been considered instead of acoustic cues such as pitch contour, rhythm, onset or sound background.
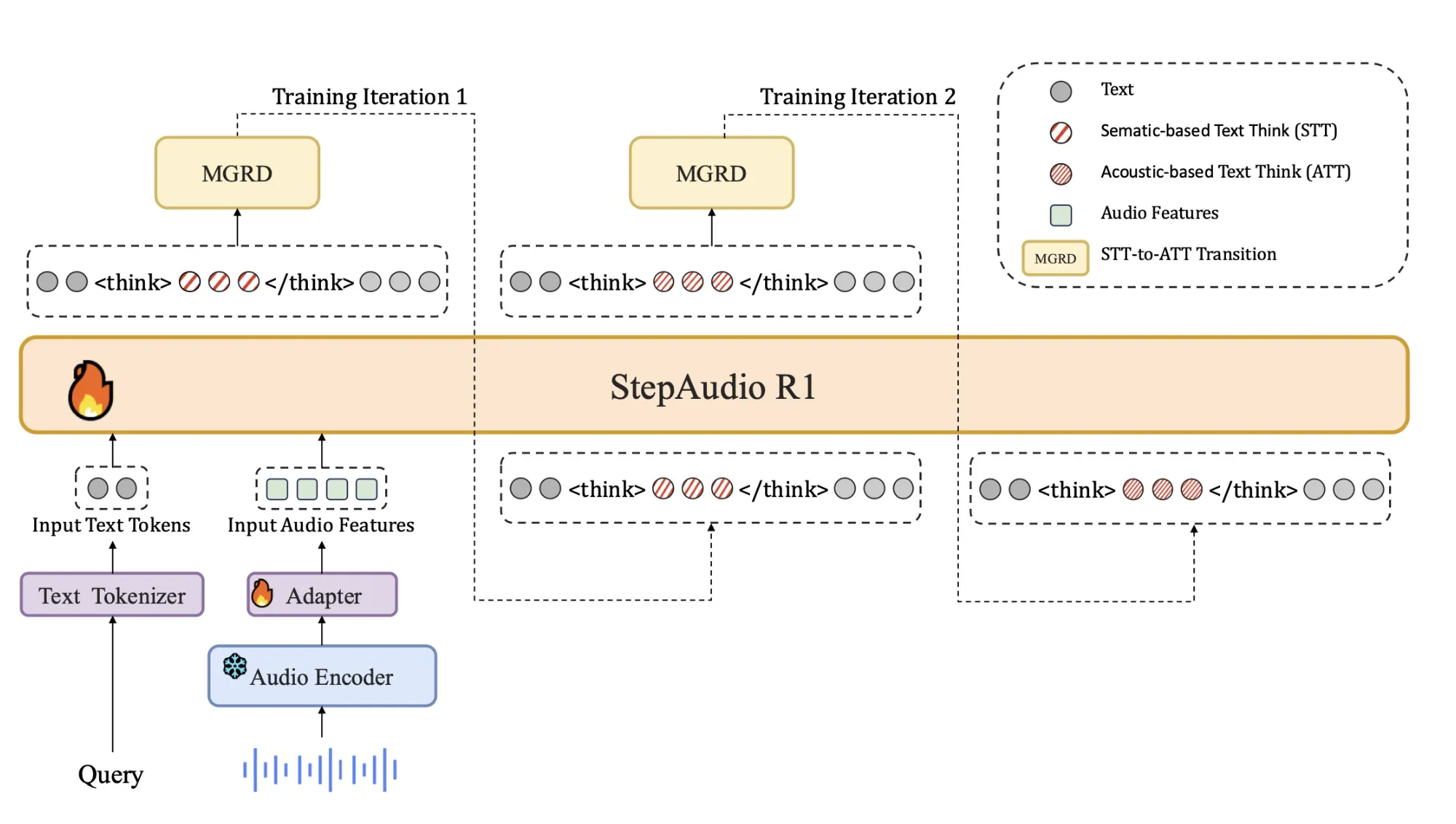
This mismatch explains why short thinking times often hurt performance in sound. The model discards many tokens that describe incorrect or incorrect assumptions. Step-Audio-R1 attacks this by forcing the model to justify responses using acoustic evidence. The training pipeline is organized according to modality at the edge of the consultation, mgrd, which selects and reduces and separates the traces that show clear sound characteristics.
Expertise in housing construction
The construction remains close to the sound systems of the previous step:
- The QWEN2 audio process is based on a green-green audio encoder at 25 hz.
- The audio adapter drops below the output of the encoder by a factor of 2, to 12,5 hz, and aligns the frames of the Token language broadcast.
- Qwen2.5 32B decoder consumes audio elements and creates text.
The decoder always generates a clear block of internal logic tags, followed by the final answer. This separation lets training objectives shape the structure and content of reasoning without losing focus on task accuracy. The model is released as a 33B parameter audio text to text model on Hugging Face under Apache 2.0.
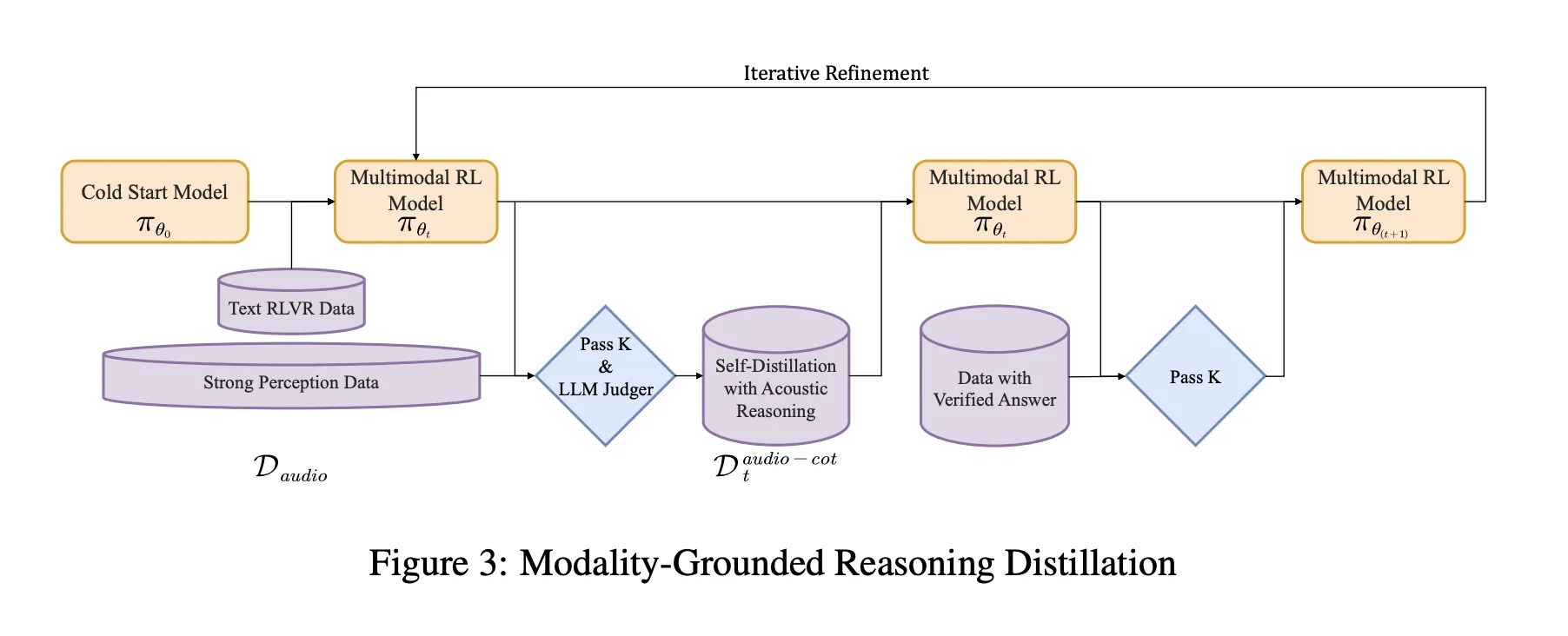
Training Pipeline, from Cold Start to Audio Grounded RL
The pipeline has a supervised cold start stage and a reinforcement learning stage that both mix text and audio tasks.
Cold start uses about 5 million examples, covering 1 billion tokens of text only data and 4 billion tokens from audio paired data. Audio tasks include automatic speech recognition, paralinguistic understanding and audio question text answer style dialogs. A fraction of the audio data carries audio chain of thought traces generated by an earlier model. Text data covers multi turn dialog, knowledge question answering, math and code reasoning. All samples share a format where reasoning is wrapped in
Directing Learning Trains Step-Audio-R1 follows this format and produces effective audio and text reasoning. This provides a basic chain of thought behavior, but it is done as if it is considered in the thinking of the text.
Modality is the basis of reasoning Mhld
MGRD is used in several iterations. In each round, the research group of the sample where the label depends on the actual acoustic properties. For example, questions about the Spokesman, Backstage Events at Fun Games or Music Building. The current model generates multiple thinking and response options for each question. The filter keeps only chains that meet three problems:
- They look for acoustic cues, not mere textual descriptions or imagined texts.
- They are logically organized as short step-by-step explanations.
- Their final answers are correct according to labels or smart checks.
This reception is accepted to form a reduced noise series of the thought data. The model is well fitted to this data and to the original textual consultation data. This is followed by reinforcing learning with guaranteed rewards, RLVR. For text questions, rewards are based on correct answers. For audio questions, a mix of reward answers for accuracy and consultation format, with an average weight of 0.8 for accuracy and 0.2 for consultation. Training uses a PPO with up to 16 rapidly sampled responses and supports sequences of up to 10 10 10 tokens to allow for long-term inference.
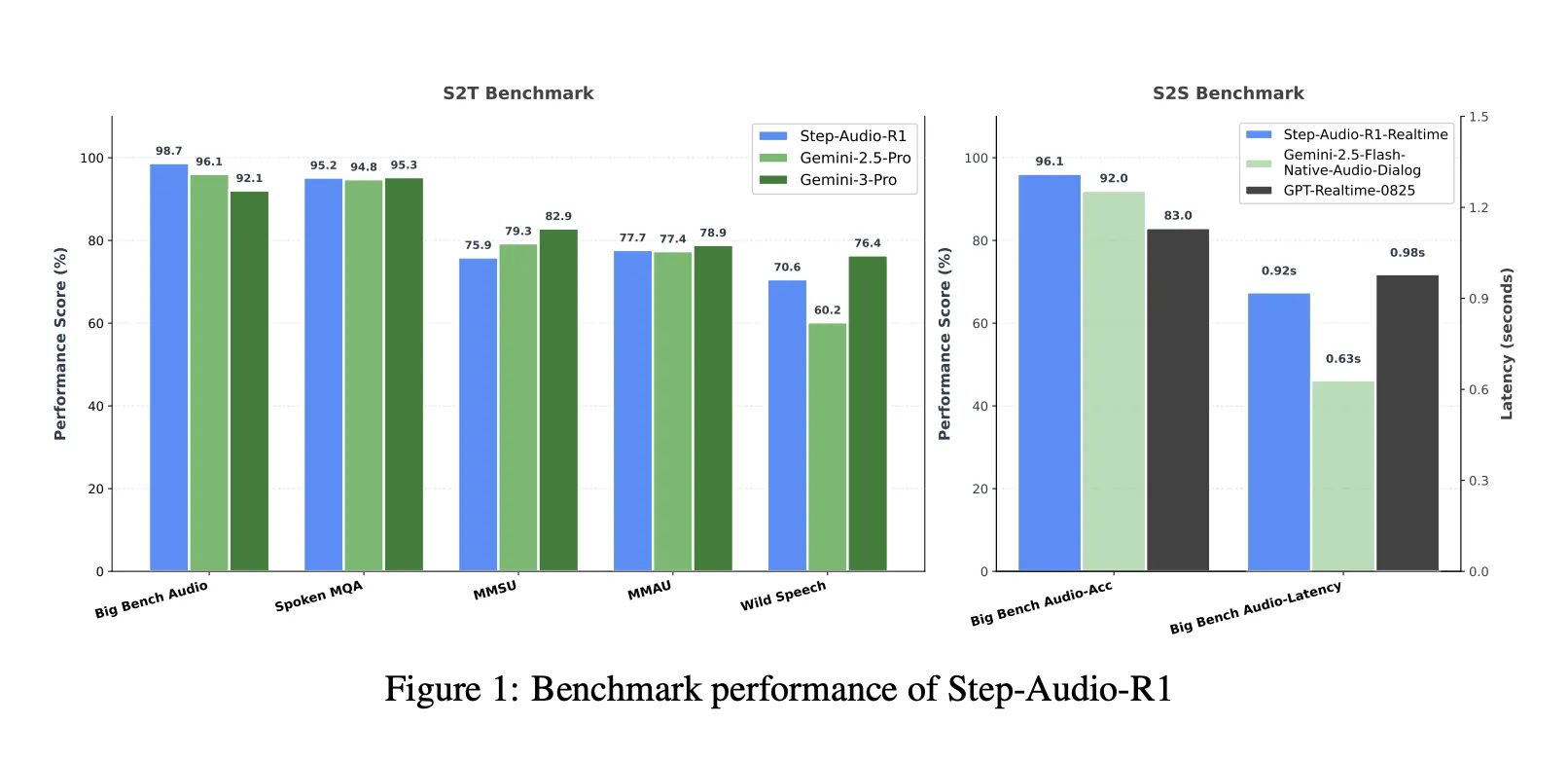
Benches, close the gap on the Gemini 3 Pro
With the combined speech to text Benchmark Suite that includes Bench AUDY Audio, MMSU, MMAU and wild speech, step-Audio-R1 reaches an average of 83.6 percent. Gemini 2.5 Pro reports 81.5 percent and Gemini 3 Pro reaches about 85.1 percent. In Big Bench Audio only, the step-Audio-R1 reaches about 98.7 percent, which is higher than both versions of Gemini.
To talk about the speech Consultation, the Step-Audio-R1 Realtime is a different time alternative Listen while you think and think while you speak broadcast style. In the Big Bench Audio speech, it reaches 96.1 percent accuracy with the first Packet around 0.92 seconds. This feature surpasses the original GPT Realtime and Gemini 2.5 Flash style audio streams while maintaining a low-second connection.
Arguments, the most important of auditory thinking
The Ablation category offers several features for developers:
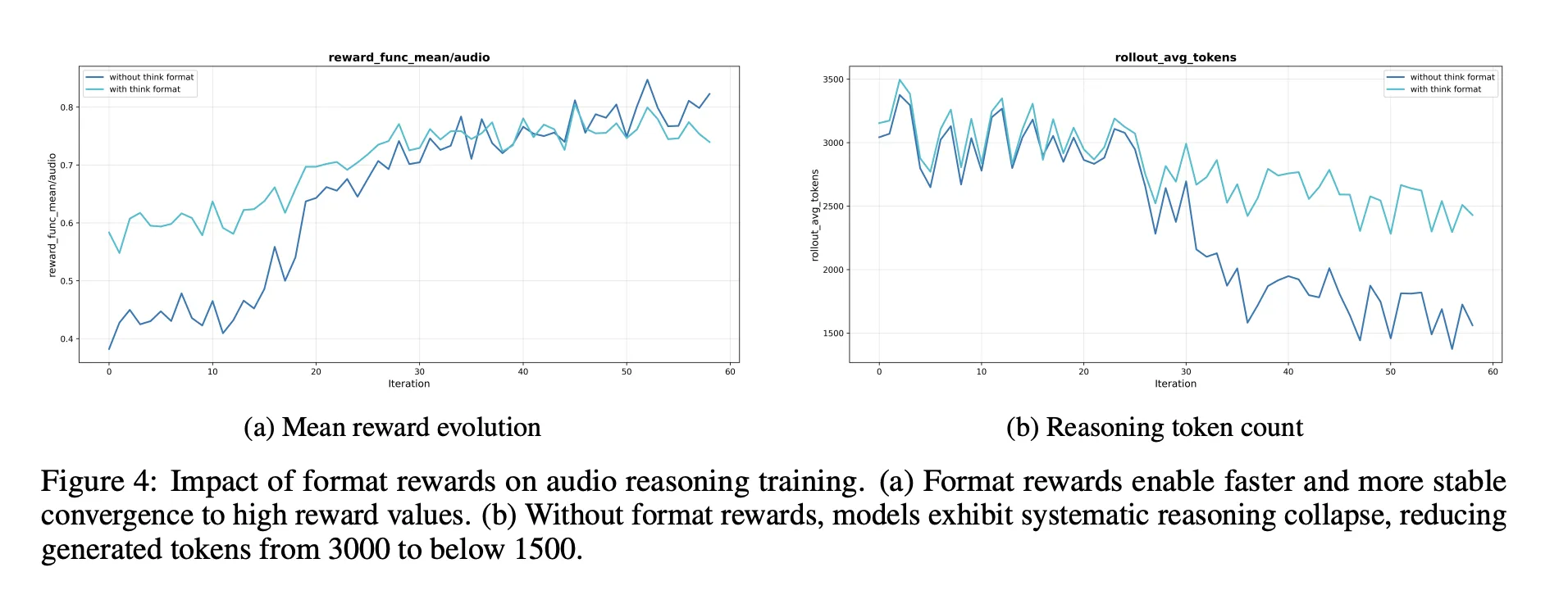
- A consultation format reward is required. Without it, the reinforcement often reduces or eliminates the chain of thought, which takes the audio benchmark scores.
- RL data should target problems of moderate difficulty. Choosing questions where 8 lies pass in the middle band gives a strong reward and keeps long thinking.
- Estimating RL noise data without such selection is useless. The quality of incentives and labels matters more than raw size.
The researchers also described the pipeline of self-perception and benefits of responses such as 'I can only read text and I can't hear sound' in a model trained to process sound. This uses specific preferences for ease of use with two selected preferences when the behavior is appropriate to accept and use audio input.
Key acquisition
- Step-Audio-R1 is one of the first models of the audio language that turns into a long series that is a constant advantage to find the accuracy of audio functions, solving the visual measurement failure seen in the previous LLMS.
- The model clearly aims to be a surrogate that shows the reflection through the use of thoughts based on the distillation test, which bothers and strips only those reflections that depend on acoustics, timbre and rhythm instead of being written down.
- ArchitEctaly, the Step-Audio-R1 combines a Qwen2 audio-based adapter and a Qwen2.5 32B decoder that always produces
- Beyond audio-visual understanding and consultation benches that cover speech, environmental sounds and music, step-audio-R1 pro surpasses Gemini 2.5 Pro, while supporting real performance with low latency speech in large connections.
- The training recipe includes a large scale managed by a series of thinking, the flexibility of the base and the reinforcement of guaranteed rewards with guaranteed rewards, providing a proven blueprint and providing a concrete and reconstructable blueprint for building future consulting models that benefit from the time of the evaluation of the integrators.

Editorial notes
Step-Audio-R1 is an important release because it transforms the chain of thought from debt into a useful tool for direct consultation by consulting with verified information with guaranteed rewards. It shows that the computer calculation test time can benefit the audio models when it shows that it is included in the acoustic characteristics and provides the benchmark results compared to the gemini 3 pro while working with the engineers. Overall this research work turns the LLMS acoustic expansion from a static failure mode into a creative and dynamic pattern.
Look Paper, repo, project page and Model weight. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



