NVIDIA AI releases nemotron-elastic-12b: a single AI model that gives you 6b / 9b / 12b variants without additional training costs

Why do Dev teams still train and maintain large models for languages that require different deployment requirements when a single elastic model can produce several sizes at the same cost? NVIDIA identifies a typical 'model family' stack for a single training task. Nvidia Ai team released Nemotron-elastic-12bthe 12b model of the reference parameter that drives the 9B and 6B variables in the same parameter space, so all three sizes come from the same multi-view point.
Many in one model family
Most production systems require several model sizes, a large model for server side loads, a mid-size model for strong GPUS, and a small model for tight latency or power budgets. A standard pipeline trains or refines each size separately, so the token costs and evaluates the storage ratio by number of variations.
Nemotron Elastic takes a different approach. It starts from the Nemotn Nano v2 12b Model for consultation and trains the Elastic Hybrid Mamba attention network. The test Nemotron-Elastic-12b can be cut in 9B and 6B variants, nemotron-elastic-9b and Nemotron-6b, 6b, using applique slicing, without spending extra money.
All variants share hardware and metadata, so training costs and shipping memory are tied to the largest model, not the number of sizes in the family.
Hybrid Mamba Transformer with Elastic Masks
Architectural, nemotron elalisastic is a mamba-2 transformer hybrid. The basic network follows the NemoTron-H Style Design, where most of the layers are Mamba-2 space sequences based on MLP and MLP, and a small set of attention that maintains the global detected field.
The durability is done by turning this hybrid into a powerful mask-controlled model:
- Width, embedding channels, Mamba heads and head channels, attention heads, and FFN center size can be reduced with binary masks.
- In depth, layers can be thrown according to the importance learned to order, in ways that are left to wound the signal flow.
The router module issues configuration decisions for each budget. These options are converted into masks by gumbel softmax, and then apply to embedding, mamba projection, attention projection, and ffn matrics. The Research Team adds several details to keep the SSM structure valid:
- The insult of the SSM who knows the SSM who respects the head of the mamba and the station team.
- Heterogeneous MLP Elastivation in which different layers can have intermediate sizes.
- The importance of layering based on the standard method is to determine which layers remain when the depth is reduced.
Small variations are always selected first in the list of items to be calculated, making the 68 and 9B models combined by the combined subnetworks of the 12b parent.
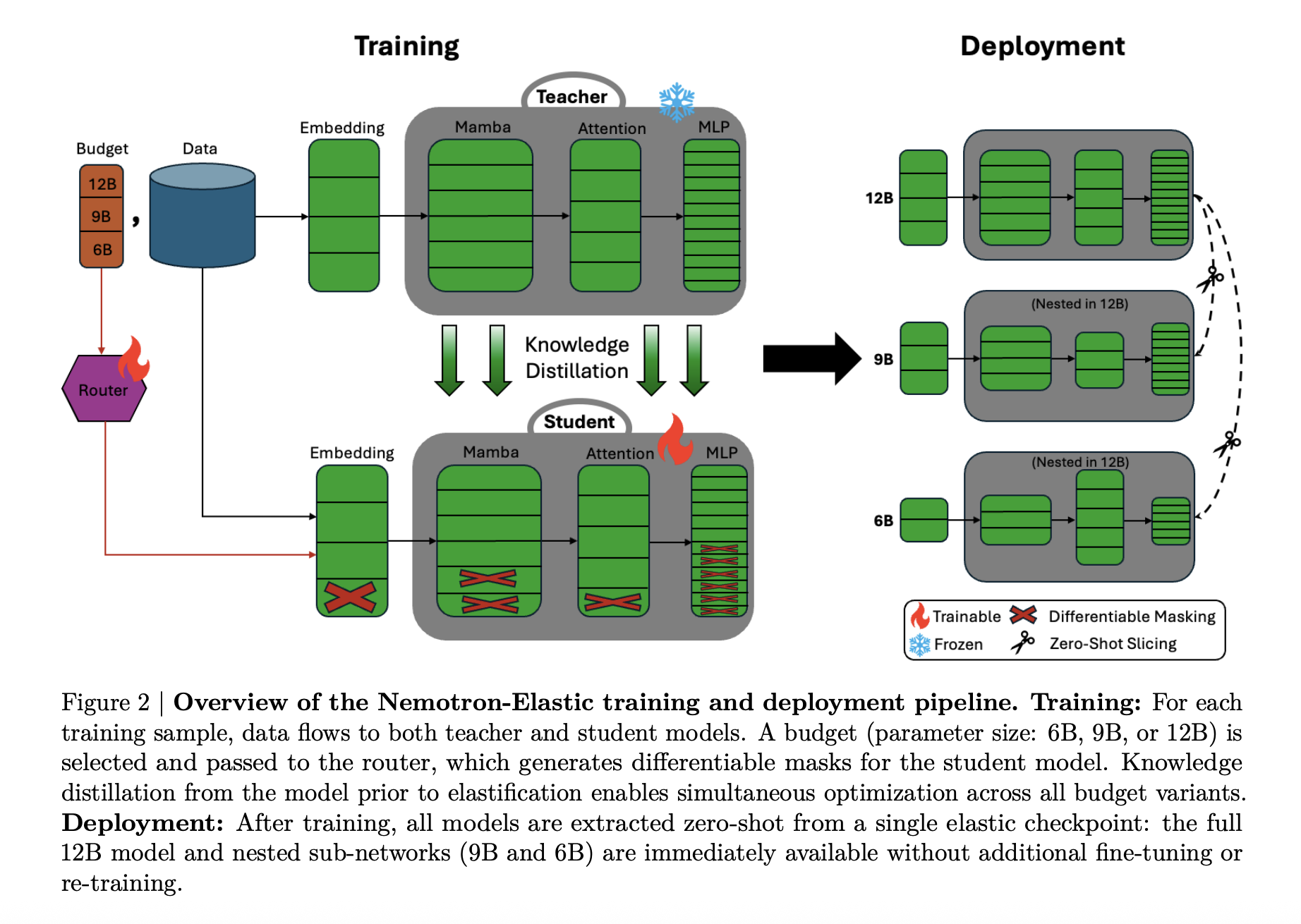
Two training sessions for consulting luggage
Nemotron Elastic is trained as a frozen teacher consultation model. The teacher is a consultation model of Nemotn-Nano-V2-12-1. The elastic-12b reader is performed well together in all three budgets, 6B, 9B, 12b, using the information of the distillation plus language.
The training runs in two phases:
- Section 1: short context, bequence length 8192, batch size 1536, around 65b tokens, for the same sample of three budgets.
- Section 2: Expanded context, sequence length 49152, batch size 512, around 45b tokens, with a random sample favoring a full budget of 12B.
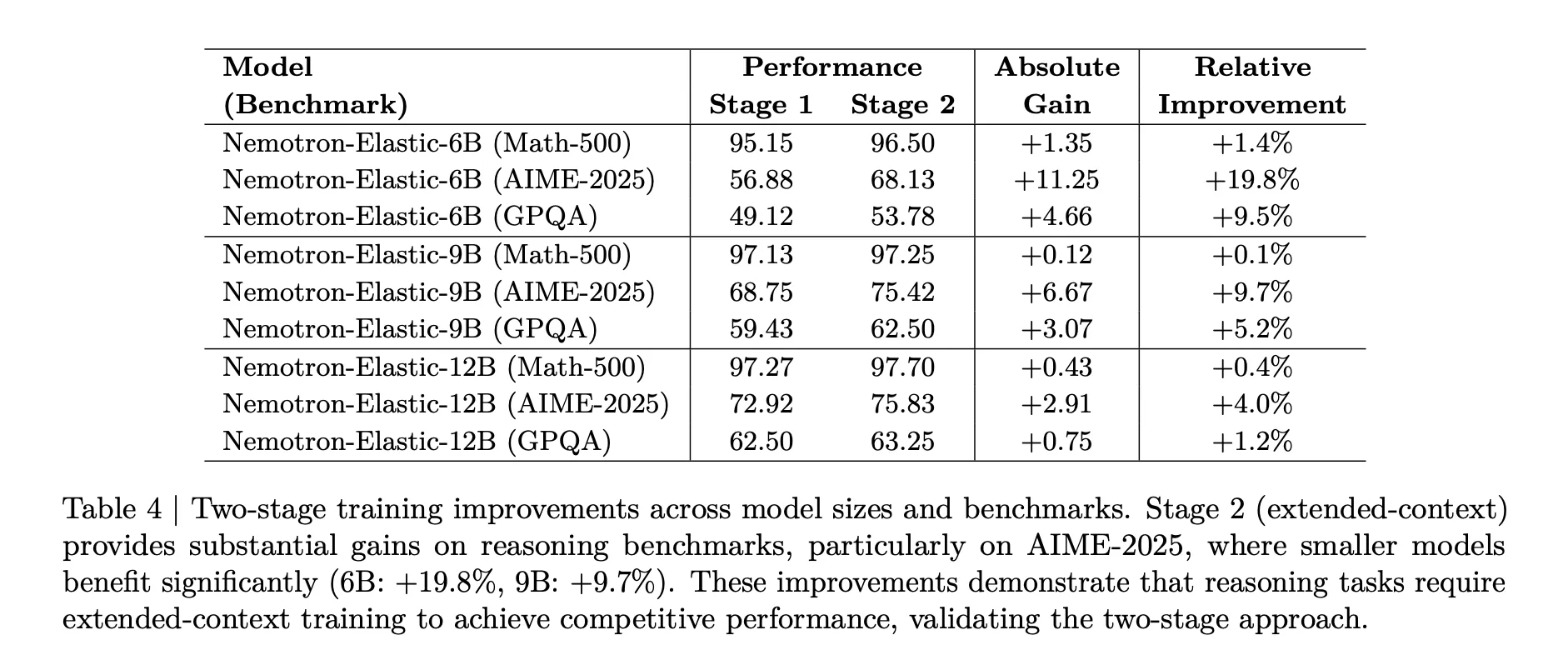
The second phase is important for consulting activities. The table above shows that with AIE 2025, the 68 model improves from 56.88 to 68.13, a correlation gain of 19.8 percent, while the 9b model receives 9.7 percent that receives additional context training.
A sample budget is also planned. In phase 2, the non-uniform weights of 0.5, 0.3, 0.2 with 12b, 9b, 6b avoid the largest model damage and keep all the variables of calculations 500, aime 2025, and GPQA.
Benchmark results
Nemotron Elastic has been tested on heavy benchmarks, stat 500, aim 2024, aim 2025, GPQA, livecodebench v5, and MMLU Pro. The table below summarizes the passes with 1 precision.

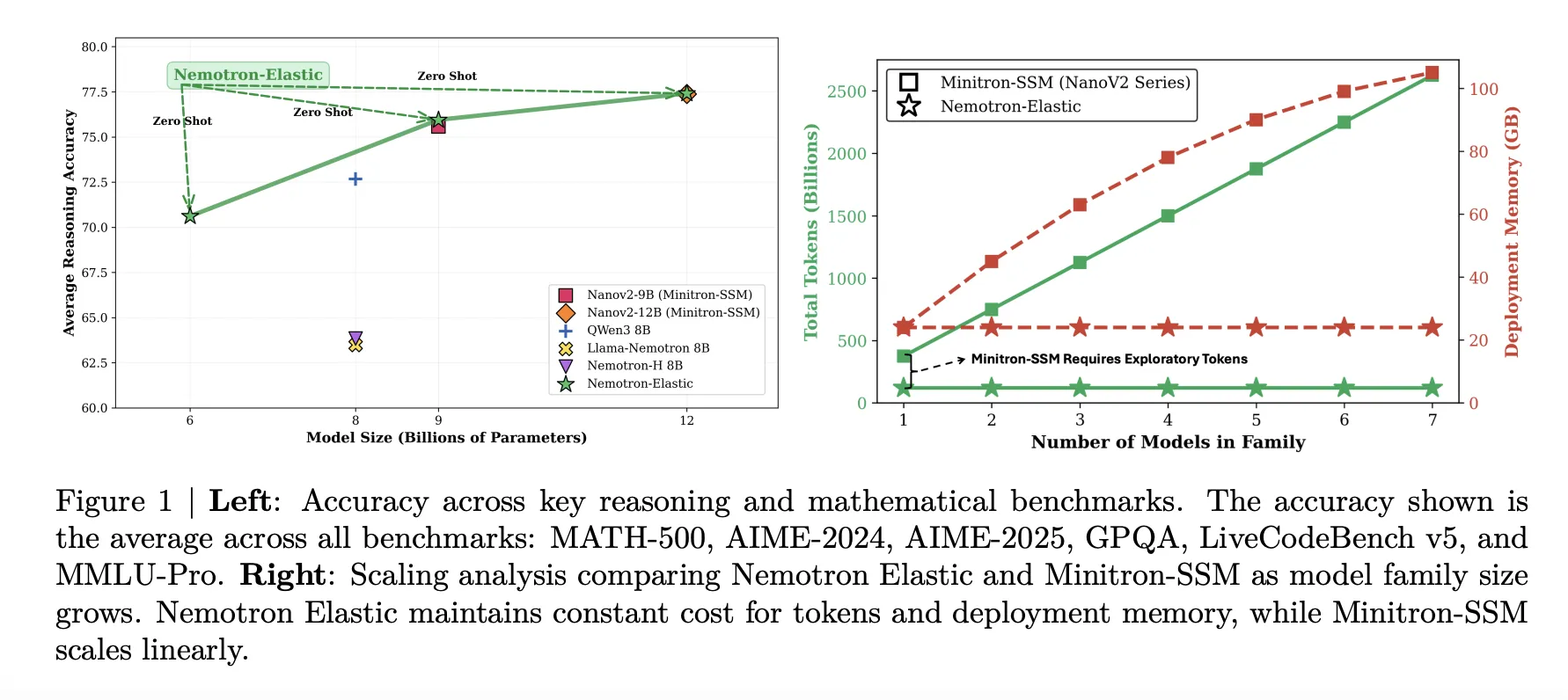
The 12b elastic model is similar to the basic nanov2-12bsine on average, 77.41 Versus 77.38, while providing 9B and 6B variations from the same run. The 9b elastic model tracks the basic nanov2-9bsine closely, 75.95 versus 75.99. The 6b elastic model reaches 70.61, less than Qwen3-8B at 72.68 but still strong in its parameter calculation given that it is not trained.
Training token and Memory Savings
The disposable Nemotron is aimed squarely at the cost problem. The table below compares the token budget required to get the 6b and 9B models from the 12b parent:
- Nanov2 Pretspain for 6B and 9B, 40t Token.
- Nanov2 Compression and Minitron SSM, 480B Plus 270B Final, 750b tokens.
- Nemotron Elastic, 110b tokens for Elastic Distillation Run.
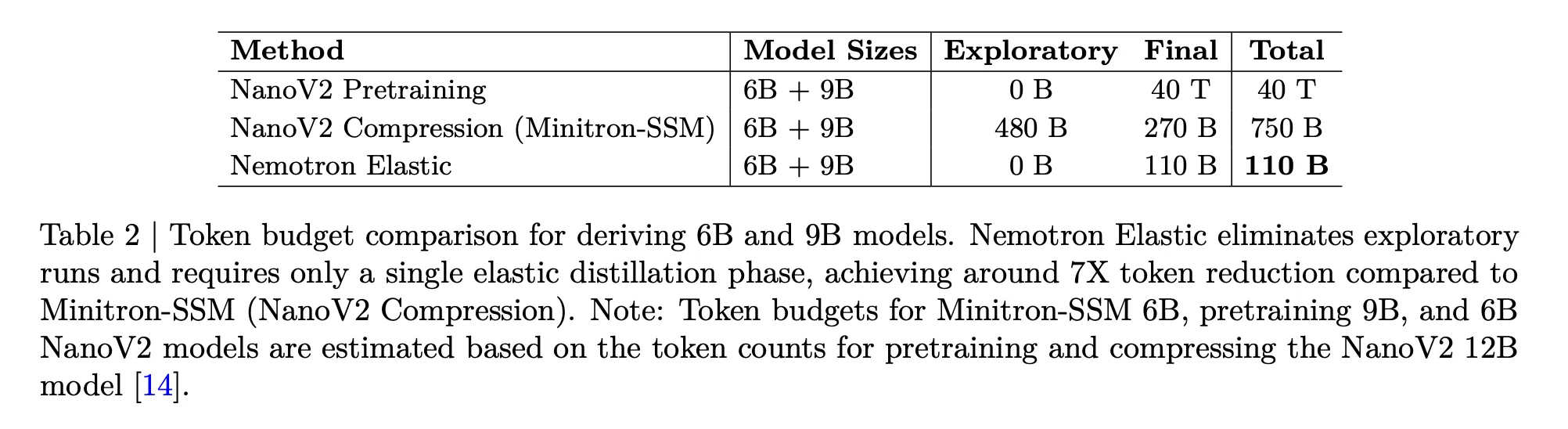
The research group reports that this provides a 360-times reduction in training two additional models from scratch, and a 7-fold reduction compared to the baseline compression.
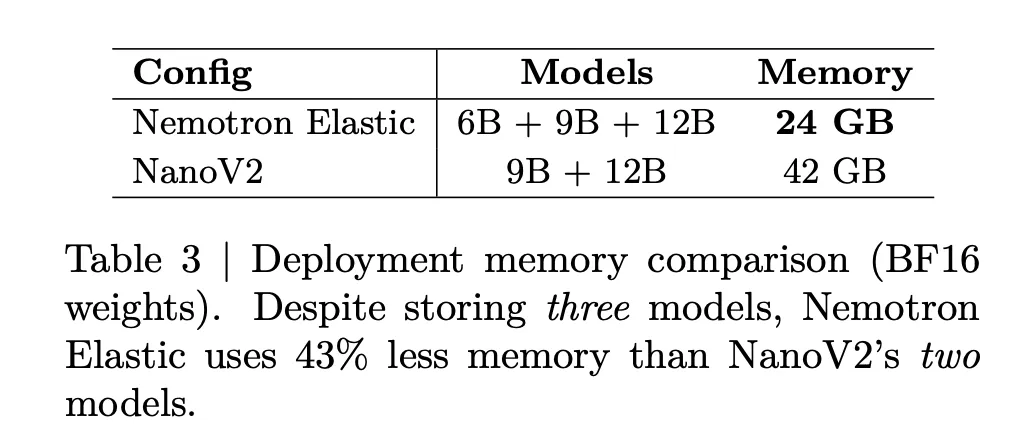
The navigation memory is also reduced. The table below says that storing Nemotron Elastic 6B, 9B, and 12b together requires 24GB of BF16 mass, while storing Nanov2 9b plus 12b requires 42GB requires 42GB requires 42GB requires 42GB requires 42GB requires 42GB requires 42GB requires 42GB requires 42GB requires 42GB needs 42GB needs 42GB needs 42GB needs 42GB needs 42GB. This is a 43 percent memory reduction while also featuring an additional 6B in size.
Matching
| How to do it | Sizes (b) | AVG Scoring Thinking * | 6b + 9b tokens | BF16 memory |
|---|---|---|---|---|
| Nemotron Elastic | 6, 9, 12 | 70.61/75.95 / 77.41 | 110b | 24GB |
| Nanov2 Compression | 9, 12 | 75.99/77.38 | 750b | 42GB |
| Q3 | 8 | 72.68 | n / a | n / a |
Key acquisition
- Nemotron Elastic trains a single 12b reference model containing 9B and 6 thousand variables that can be out-voted without further training.
- The elastic family uses a hybrid mamba-2 architecture and a transformer construction and a learned router that uses a structured mask due to the width and depth to define each subrode.
- The method requires 110b training tokens to get 6b and 9B tokens from a 12b parent which is about 7 fewer tokens than 750b fewer minitron ssm
- In the benchmarks benchmarks such as math 500, aime 2024 and 2025, GPQA, livecode models and MMLU Pro the 6b, 95.91 with 77.41 without nanov2 bases and competing with qwen3-8b.
- All three sizes share a single test of 24GB BF16 Memory transfer remains constant in the family compared to 42GB of the different nanov2-9b and 12b models.
Nemotron-elastic-12b is an effective step in making portable households that are cheap to build and operate. One extended experiment produces 6b, 9b, and 12b variants with a mamba-2 hybrid and a construction transformer, a learned router, and programmed masks that last. The token slicing method costs related to different partitioning or expiration as if it works and saves shipping memory and keeps shipping memory at 24GB for all sizes of multi tier llm deployments. Overall, the NemoTron-elastic-12b turns the size-variable LLMS into a single design problem.
Look Paper weight and model. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


