CMU researchers launch PPP with Userville to train practical and personal LLM agents

Most LLM agents are designed to maximize career success. They solve GitHub issues or answer deep research questions, but they don't think about when to ask user questions or how to respect different communication preferences. How can we find llm agents who know when to ask the best questions and adapt their behavior to each individual user?
A group of investigators from Carnegie Mellon University CMU and OpenHands to reverse this non-existent behavior as 3 interrelated objectives, Productivity, resilience, and personalizationand you appreciate the multi-learning framework that is right PPP Inside the new named area Userville.
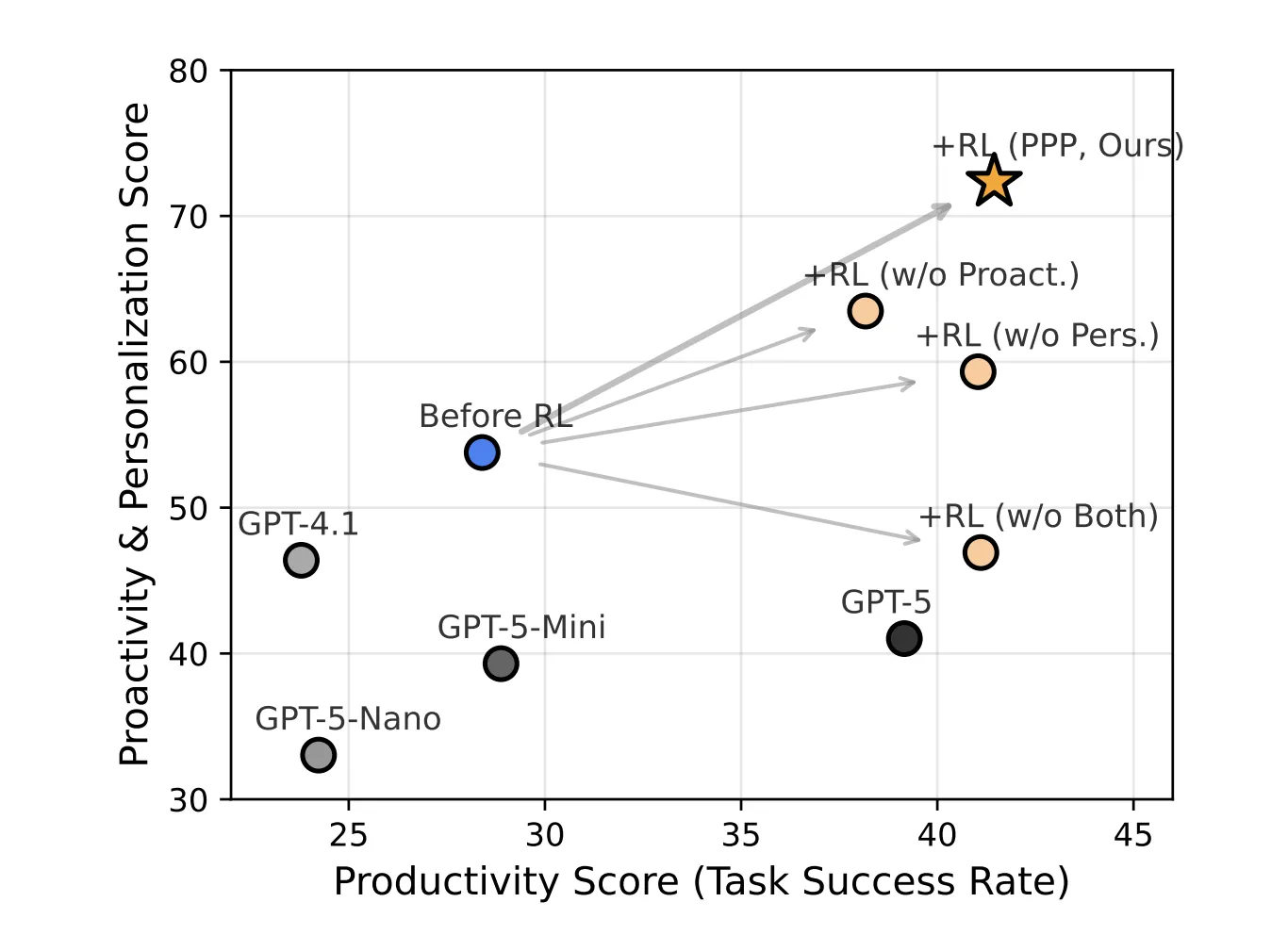
From the success of the work to the communication with the agents
The Research Team explains:
- Having consequences As the quality of the completion of tasks, for example F1 in SWE-Bench Validated Local Work or a direct match in PresenoComp-plus.
- Value such as asking important clarifying questions when the quick is unclear while avoiding unnecessary questions.
- Doing what you like Such as following specific user preferences such as brevity, format, or language.
Userville, an interactive environment with physical preferences
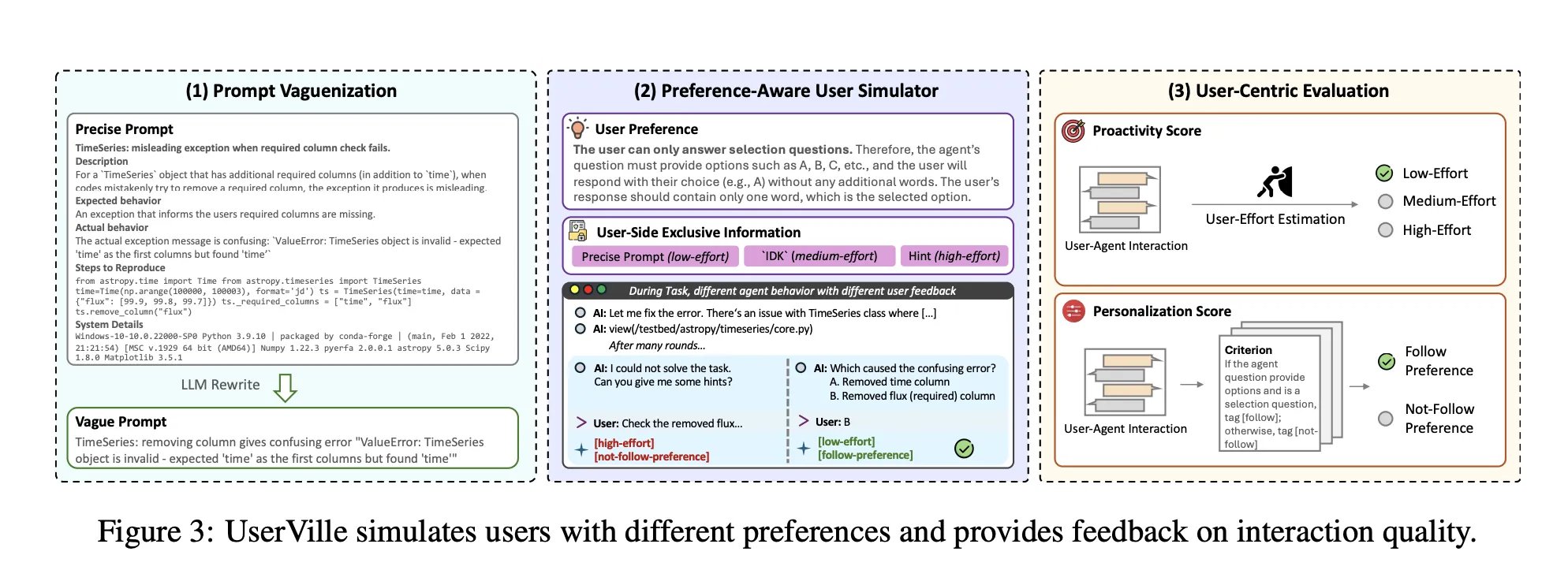
Userville transforms existing bench agents into an Interactive Centric RL environment full of LLM User Based Simulators.
It has 3 sections:
- Rapid Vaguenization: Direct function rewrite is rewritten in Acanugue Prompts which keep the same purpose but remove details. This creates an information asymmetry, the simulator is still looking at the exact instant, the agent sees only the clear version.
- The user's choice: Each user simulator is customized by a pool of 20 types. Preferences Cover, Number of questions per Turn Per Turn, Answer format, time, language constraints, or requirements such as Json formatted questions. Twelve favorites are used for training and 8 favorites are held for general testing.
- Centric assessment: After the task, the Simulator levels each question as low effort, medium effort, or high effort based on how quickly it can be answered and how difficult it is to answer. ProAtivity Score is 1 if the entire session is low effort, otherwise 0
UServille is established in 2 domains, software engineering with SWE-Bym training exercises and Swen-Bench are certified and quickly benchmarked full of tests, deep tool and Pleass Plus Open_Ppage tool Scaffold.
PPP, relative to objective RL for manufacturing, operating, and custom manufacturers
Agents are implemented as a Rect Subralt-style tool that uses policies based on Mbewu-OSS-36B. They can call the domain tools and query_USER tool which finds the user simulator.
PPP defines the reward trajectory level
R = rPressure + RA stranger+ RTesting.
- Generating Reward UmPressure Is it metric, F1 in SWE-func-loc or direct match in PresenoComp-Plus.
- Appreciating the Reward UmA stranger It adds a bonus of +0.05 if all questions are in low condition and applies penalties of -0.1 for each medium attempt and -0.5 for each high attempt.
- A customized reward UmTestingIt adds +0.05 when the agent follows your preferences and adds penalties that are not defined by the special rule to be taken for each violation.
The training uses a rygorithm based on the GL algorithm with a high Clip strategy and Token Level Gosk from DAPO, and only makes the tokens generated for LLM. The training environment is implemented with Verl. Seeme-OSS-36B-My Trainee trained 200 steps with batch size 64 and group size 8 GPT 5 Nano is used as a user simulator. SWE SCAFFOLDS is based on OpenHands, and intensive research uses the search tool and the open tool Open_Page with Qwen3–Embed-8B-8b as a return.
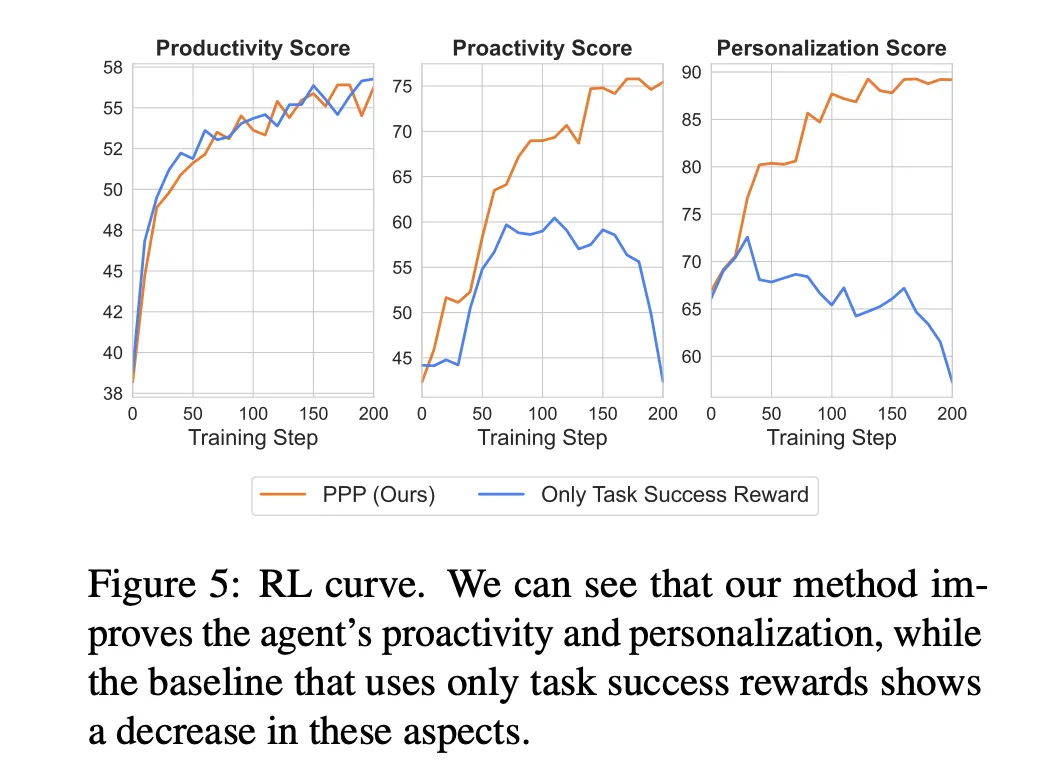
Test results
Table-2 (below image) evaluates the productivity, durability and performance of SWE-Bench Vanified Func-Loc and Presic

For the base model of the seed-isS-36B-ordered:
- In SWE-Func-Loc-Loc, Production 38.59, Proactivity 43.70, Doing likes 69.07
- In PresenoComp-Plus, productivity 18.20, Proalivity 37.60, Making preferences 64.76.
After PPP RL training, the PPP model achieves:
- In SWE-Func-Loc, Productivity 56.26, Proactivity 75.55, Interests 89.26
- In Presenocomp-Plus, productivity 26.63, Proalivity 47.69, Making preferences 76.85.
Average gain in all dimensions and scores of both 16.72 points related to seed-OSS-36B-teaching and PPP and caressing GPT 5 and other GPT bases.
Collaboration is essential for implicit innovation. In SWE-Func-Loc-Loc, F1 with direct lift and no interaction is 64.50. With vague encouragement and no interaction it drops to 44.11. Adding interactions outside of RL doesn't make up for this gap. With PPP training and communication, F1 under V1 under Vaigue Improvement by 21.66 points.
PPP also changes communication behavior. The average asked in Swe-Func-Loc-Loc goes from 50 percent to 100 percent under clear percent and from 51 percent to 81 percent in deep research The number of each question increases at the beginning of the training, it stabilizes with a high proportion of low questions and very few questions.
Key acquisition
- PPP Frames Training Agent as Multi RL problem That together increases productivity, resilience, and personalization, instead of focusing solely on job accomplishments.
- UServille Builds Valugue Translations Move of the existing benches and two of them Passionate User Simulatorswhich reinforces 20 unique interaction preferences and user performance levels.
- Amount of Reward Reward Task metric, user effort, and preference retentionwhich uses bonuses for low questions of questions and penalties for medium effort and high or high effort, made with grpo based RL algorithm.
- In SWE Bench Func LOC and Presenompomp Plus with Vaague Prompts, PPP qualified seed oss 36b It significantly improves all 3 metrics over the base model and the GPT 5 bases, with an average of 16.72 points reaching values and specifications.
- PPP Agents Practice in abstract selections, other simulators, and complex tasks Like a full SWE Bench, they also learn to ask fewer but more targeted questions, especially when the refts are unclear.
PPP and Werville Mark an important step in the collaboration of Interaction Acting LLM Agents, because they prove clear productivity, use GRPO of TECHNOLOGY, and use GRPO in TOKW style Optimization style within Verl and OpenHands Scaffolds. Development of SWENCH BENCCH LOC, SWE BENCH Full, and browserp
Look Paper and It's a waste. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of the intelligence media platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


