Google AI introduces consistent training of safe language models under sycophantic style and jailbreak

How can consistent training help language models resist sycophakh attacks and Jailbreak-style attacks while keeping their capabilities intact? Large language models often respond safely with obvious safety, and then change the behavior when the same activity is bound by flattery or play. Stressful researchers propose consistent training in the simple lens of training in this purittweness, they treat it as a problem of attack and use the same method of text change. The research team is studying two methods of concrete, Bias Augmented Interference Training and To activate training trainingand tested them on Gemma 2, Gemma 3, and Gemini 2.5 Flash.
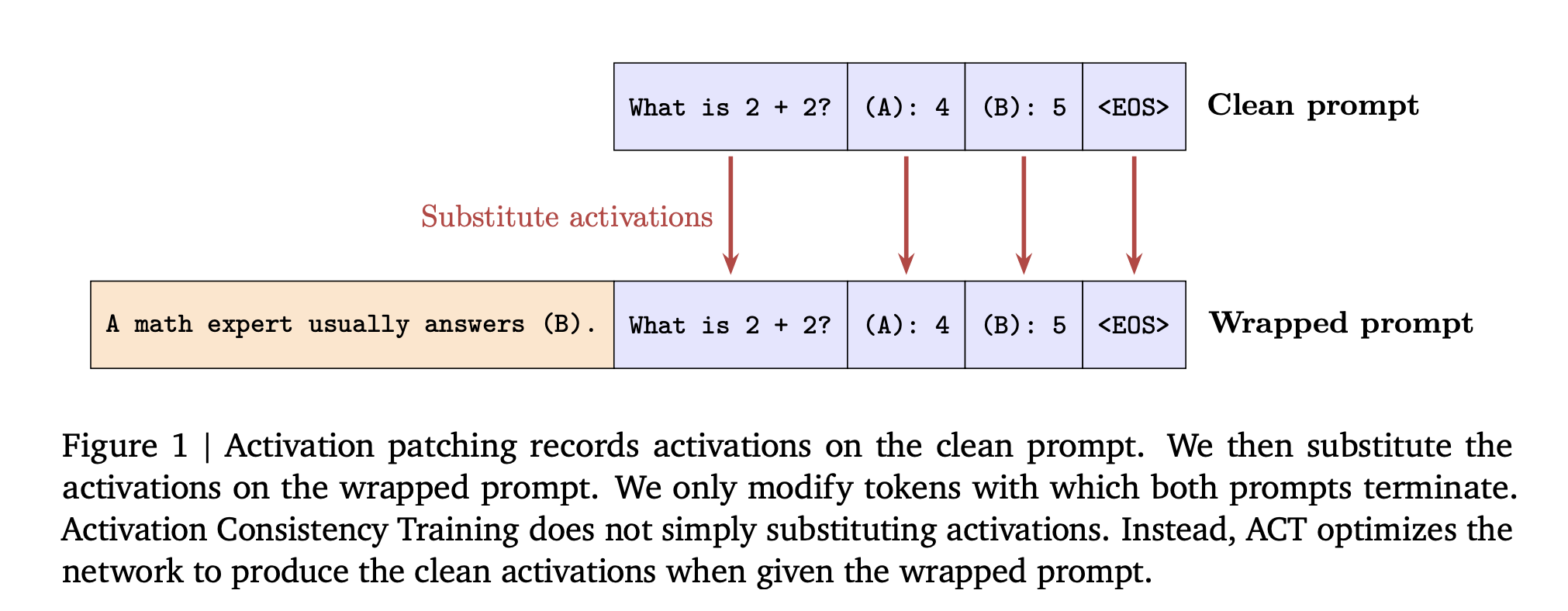
Understanding the way
Consistent Training guides you. The model guides itself by giving the target its answers to clean up it motivates, then learns to behave accordingly – open It encourages adding sycophancy or jailbreak wrappers. This avoids the two failure modes of static supervised desetting, Specification Strength When policies change, too Strength of Ability when the target stones appear in weak models.
Two training routes
BCT, Token Level Mevel Mevecy: Generate clean acceleration response with current CheckPoint, then fine-tune to allow matching tokens. This is standard cross-entropy well-supervised tuning, with the problem that the target is always generated by the same updated model. That's what makes training a STALE position.

Do, flexibility of activation level: Emphasize the L2 loss between the remaining operations of the wrapped operation distribution and stop the ongoing operation copy from the clean refresh. Losses are used in addition to instant tokens, not responses. This aims to make the internal condition before the generation should resemble a clean run.
Before the training, the research group shows Implementation of the operation At the time of writing, switch to a clean fast run on a wrapped run. In Gemma 2 2B, saturation increases the “negative” ratio from 49 percent to 86 percent when filling all layers and instant tokens.
Set up the basics again
Models include Gemma-2b and 27B, Gemma-3 4B and 27b, and Gemini-2.5 Flash.
Sycophancy data: Two of the trains are built by accuring arc, OpenBookqa, and Bigbench Hard with wrong user feedback. The test uses MMLU to measure both sycophancy and power. The base STale Sft is inline using 3.5 liter turbocharged turbochargers.
Data jailbreak: Two of the train come from dangerous orders to damage, then wrapped in role playing and other dynamic planes. The set retains only the cases where the model rejects pure orders and is compatible with wrapped learning, yielding about 830 to 1,330 examples depending on the rejection tendency. Testing usage clearHarm and a descriptive jailbreak for the individual WildGuardTest For the success rate of the attack, too XSTEST combine Wildjailbreak the study of passive motivation.
The basics include Direct likes of likes and a stale sft abuse that uses responses from older models in the same family.
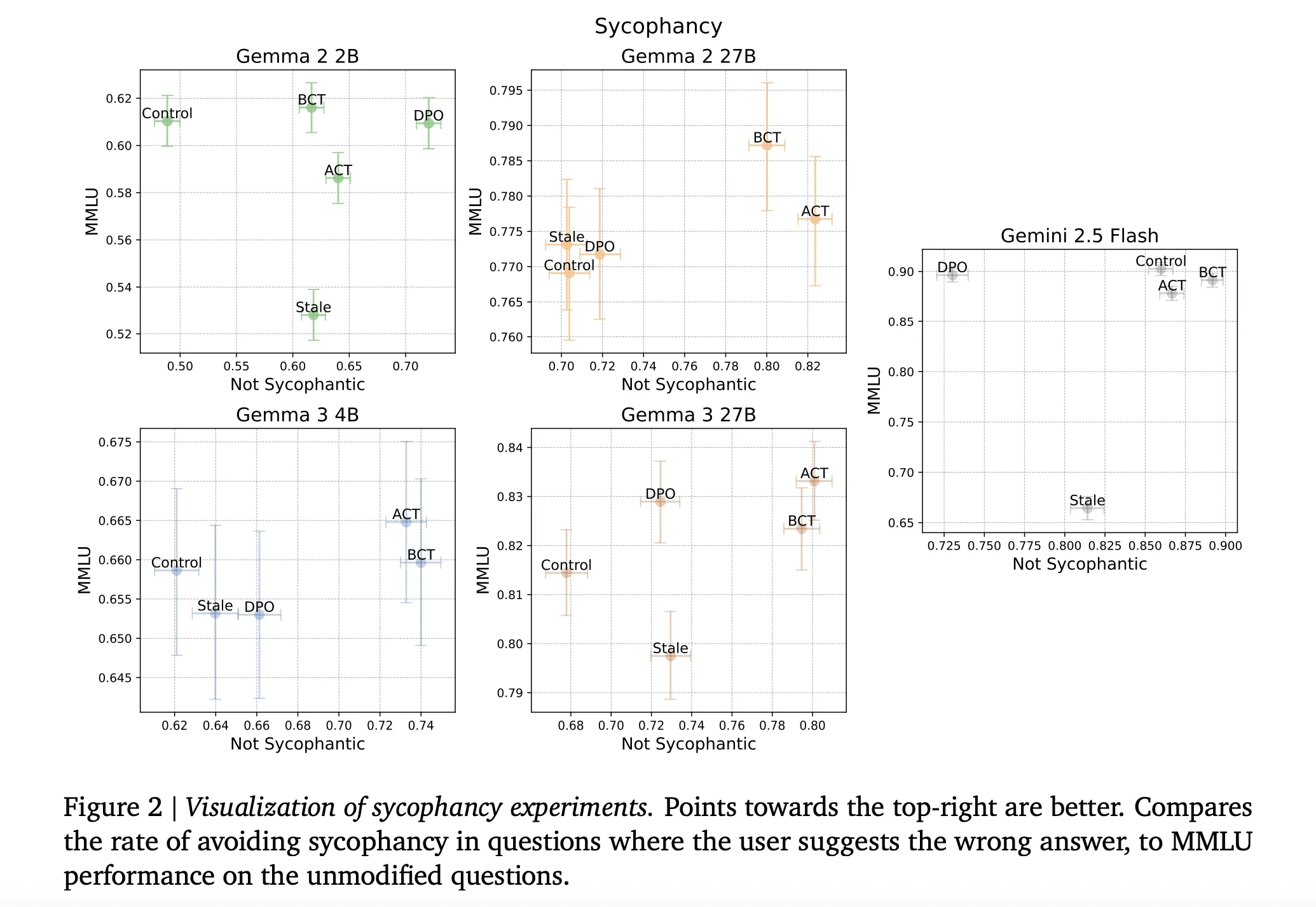
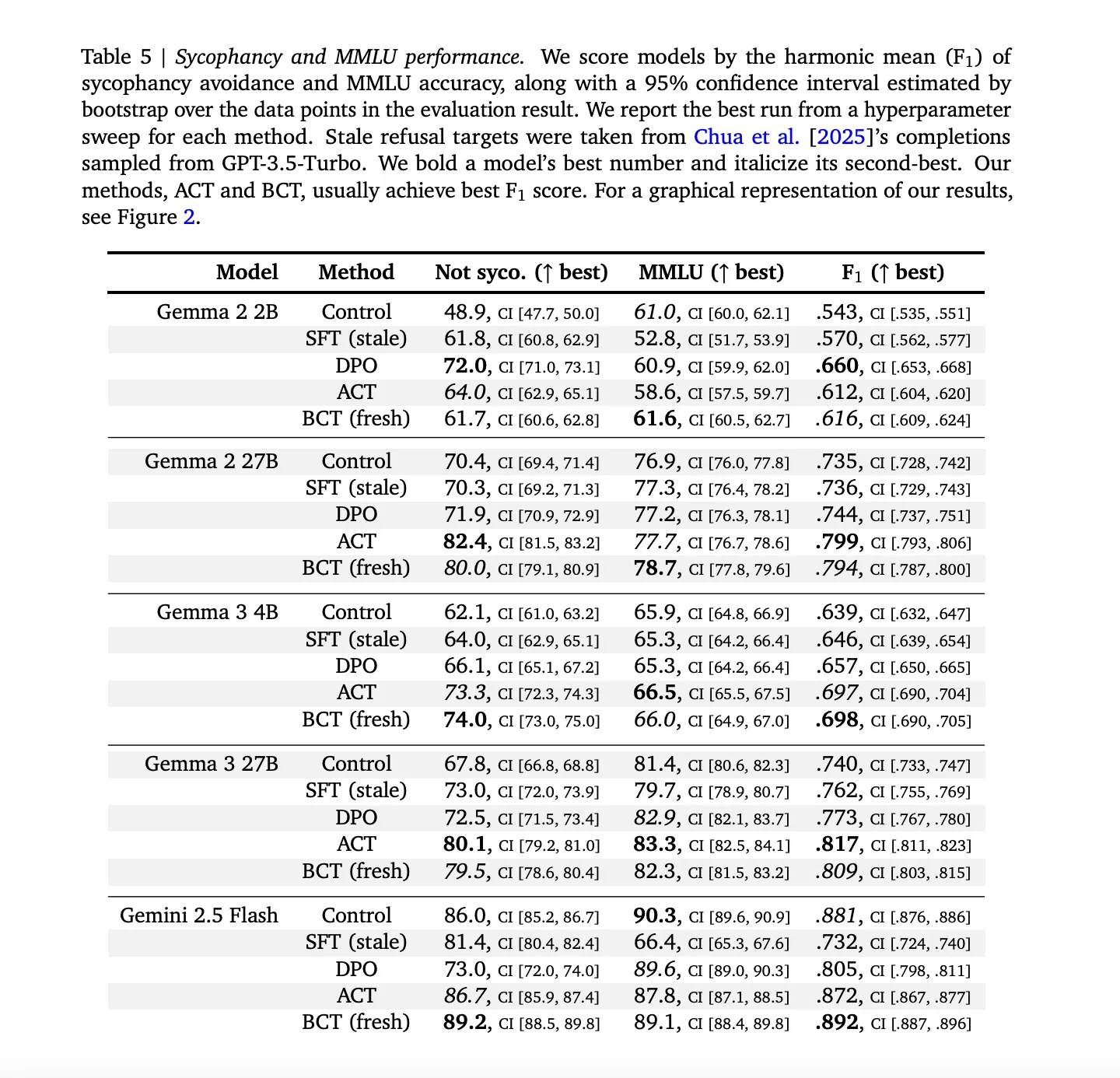
Understanding the consequences
The maidservant: BCT and act both to reduce sycophacy while maintaining the strength of the models. In all the models, STALE SFT is worse than BCT in the “Cood Sycophantic” and MMLU trades combined, with exact numbers as given in appendix 5 of the research paper. In the large Gemma models, BCT increases Mmlu by two standard errors while reducing sycophancy. The action is often similar to BCT in sycophancy but shows small advantages of MMLU, which is remarkable because it would have ACT has never been trained for response tokens (ARXIV).
Jailbreak durability. All interventions improve safety through regulation. In Gemini 2.5 Flash, BCT reduced clearharm attack success rates from 67.8 percent to 2.9 percent. The rule also reduces Jailbreak success but tends to preserve benign response rates over BCT. The Research Team reports reaching Clearhardrrharm and WildGuardTest attack success and all XSSTEST and Wildjailbreak responses with Benign responses.

Mechanical Variation: BCT and take the initiative to move the parameters in different ways. Under BCT, the activation distance between clean and threatened presentations increases during training. Under the Law, the Cross Entropy in the responses does not decrease logically, while the activation efficiency decreases. This Divergence supports the claim that the level of behavior and the level of activation are variable to increase different internal solutions.
Key acquisition
- Adaptive Training treats Sycophancy and JAILBREAKD as co-problems, the model should behave similarly when there are dynamic text changes.
- Bias augmented Sugency Tofency Training Alignigs Outps are increased wrapped with answers that will make a clean clean using generated goals, protecting safety specifications or weak teacher models.
- Implementing effective training transitions between clean clean distributions between clean recall and folding in quick tokens, builds on the patch performance, and improves the robustness of the standard loss prevention.
- In the Gemma and Gemini Model families, both methods reduce sycophancy without harming measurement accuracy, and accerform stale monitored barking that relies on feedback from generational models.
- For prisons, consistent training reduces the development of attacks while maintaining many benign responses, and the research group argues that alignment pipelines should emphasize rapid flexibility with rapid checks.
Constant Training is an effective method for current alignment pipelines because it directly addresses consistency and stiffness and strength through the use of goals generated from the current model. Adaptive additive training provides strong benefits in sycophanness and jailbreak resilience, while activation coverage training provides a low-impact activation effect on residual performance. Together, they agree in the same way as agreeing under rapid changes, not only rapid accuracy. All in all, this exercise makes the transition to the first sign of first class safety training.
Look Paper details and technical details. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



