Cache-to-cache (C2C): Direct semantic connections between large language models with KV-cache fusion
: Direct semantic connections between large language models with KV-cache fusion")
Do major language models interact without sending a single text token? A group of researchers from Tsinghua University, Infinigence Ai, the Chinese University of Hong Kong, Shanghai Ai Laboratory, and Shanghai Jiao Tong University say yes. Cache-to-cache (C2C) is a new communication paradigm in which large language models exchange information through their KV-cache rather than through generated text.
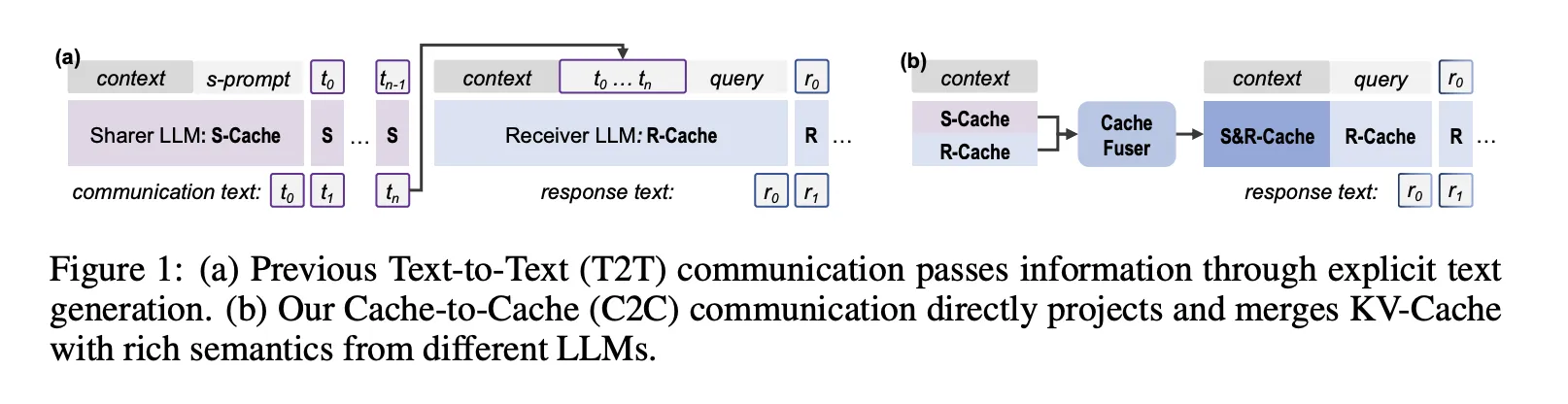
Text communication is something in the box in most LLM programs
Current Multi LLM programs use mostly text to communicate. One model writes the description, the other model reads it as context.
This design has three active costs:
- Internal activation is compressed into short natural language messages. Most of the semantic signal in KV-Cache never crosses the interface.
- Natural language is confusing. Even with structured protocols, the model coder may encode structural signals, such as an HTML role.
A tag, which does not survive an invisible text description. - Every communication step requires token by token decoration, which carries latency in the long analysis exchange.
The C2C function asks a specific question, we can treat KV-cache as a communication channel instead.
Oracle test, can be KV-cache to manage communication
The research team is starting to run two Oracle-style tests to test whether KV-cache is a useful medium.
Enrichment buffer
They compare three setups on multiple choice benches:
- Direct, FURELL in question only.
- They are Shot Shot, FUSPLATS in Exemplars and the question, long cache.
- Oracle, FUSPLARS in the examples and the query, then discard the Exemplar part and keep only the query that understands the cache piece, so the length of the cache is the same as Direct.

Oracle improves accuracy from 58.42 percent to 62.34 percent in the same cache time, while a few shots reach 63.39 percent. This shows that enriching the KV-cache query itself, even without multiple tokens, improves performance. An intuitive analysis shows that enriching only the enrichment is better than enriching all the layers, the latter promotes the gang process.
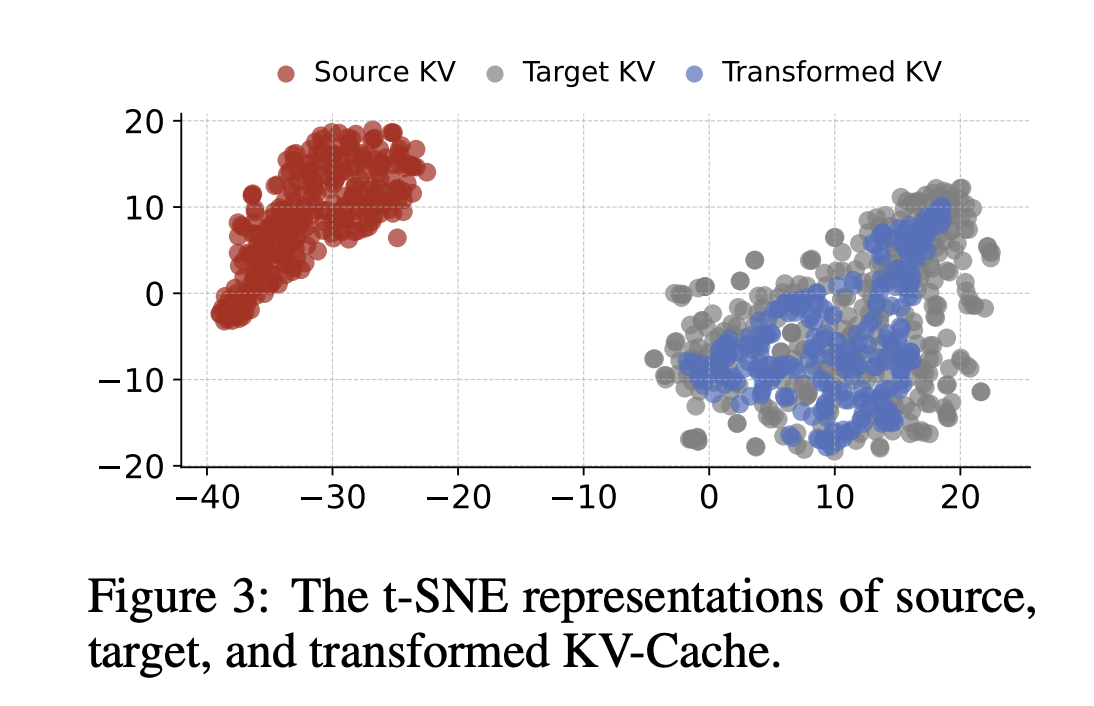
Cache Transformation Oraction
Next, they test whether a KV-cache from one model can be converted into a space for another model. Three Player MLP is trained to map KV-cache from Qwen3 4B to Qwen3 0.6b. IT SNE Plots show that the modified cache lies within the target cache, but only in the subregion.
C2C, specifically semantic communication via KV-cache
Based on these wastes, the research team defines the connection of the buffer to between the sharer and the receiving model.
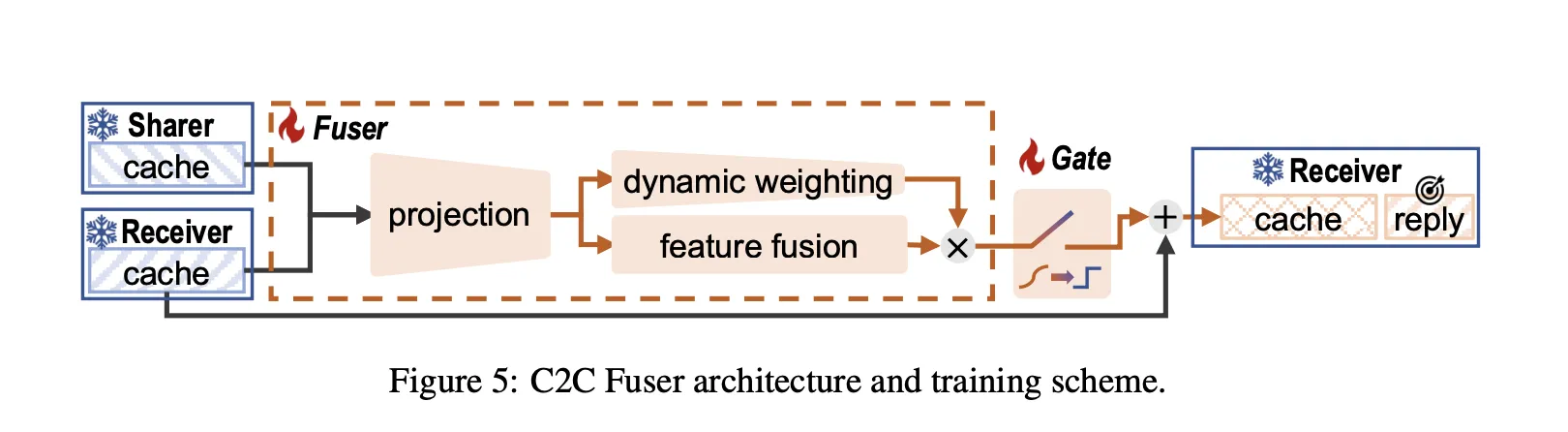
During reading, both models read the same entries and generate a smart KV-cache layer. For each receiving layer, C2C selects a mapper layer and uses the C2C Fuser to generate a combined cache. During decoration, the receiver predicts the tokens included in this combined cache instead of its original cache.
C2C Fuser follows the principle of residual fusion and consists of three modules:
- Projection module The Consaterate Sharer and Receiver KV-cache vector, uses the projection layer, then the Fusion layer feature.
- Powerful weight loss module Moquulates Heads according to input so that other heads are considered to be more dependent on negative information.
- Readable Gate It adds a gate to each layer that determines whether it injects shared context into that layer. The gate uses a gumbel sigmoid during training and becomes binary during detection.
The machine and receiver can come from different families and organizations, so C2C also defines:
- Token alignment by decoding tokens in line and re-entering with an extended tokenizer, then selects the extended tokens with masked masterimal string.
- Laser alignment uses a cutting edge technique in which the upper layers are applied first and worked backwards until the shallow model is completely covered.
During training, both LLMS are frozen. Only the C2C module is trained, which uses the loss of the token prediction following the acquisition. FIAD C2C FUSErs are trained on the first 500K samples of open data2.5, and tested on OpenBookqa, ARC challenge, MMLU Relux and C Sout.
Accuracy and latency, C2C and text communication comparison
Across combinations of shared shares built from Qwen2.5, Qwen3, LWAN3.2 and Gemma3, C2C consistently improves the accuracy you receive and reduces latency. For results:
- C2C achieves about 8.5 to 10.5% higher accuracy percentage than individual models.
- C2C outperforms Text Communications by about 3.0 to 5.0 percent on average.
- C2C delivers up to 2x the average latency compared to text-based interactions, and in some configurations the speed is greater.
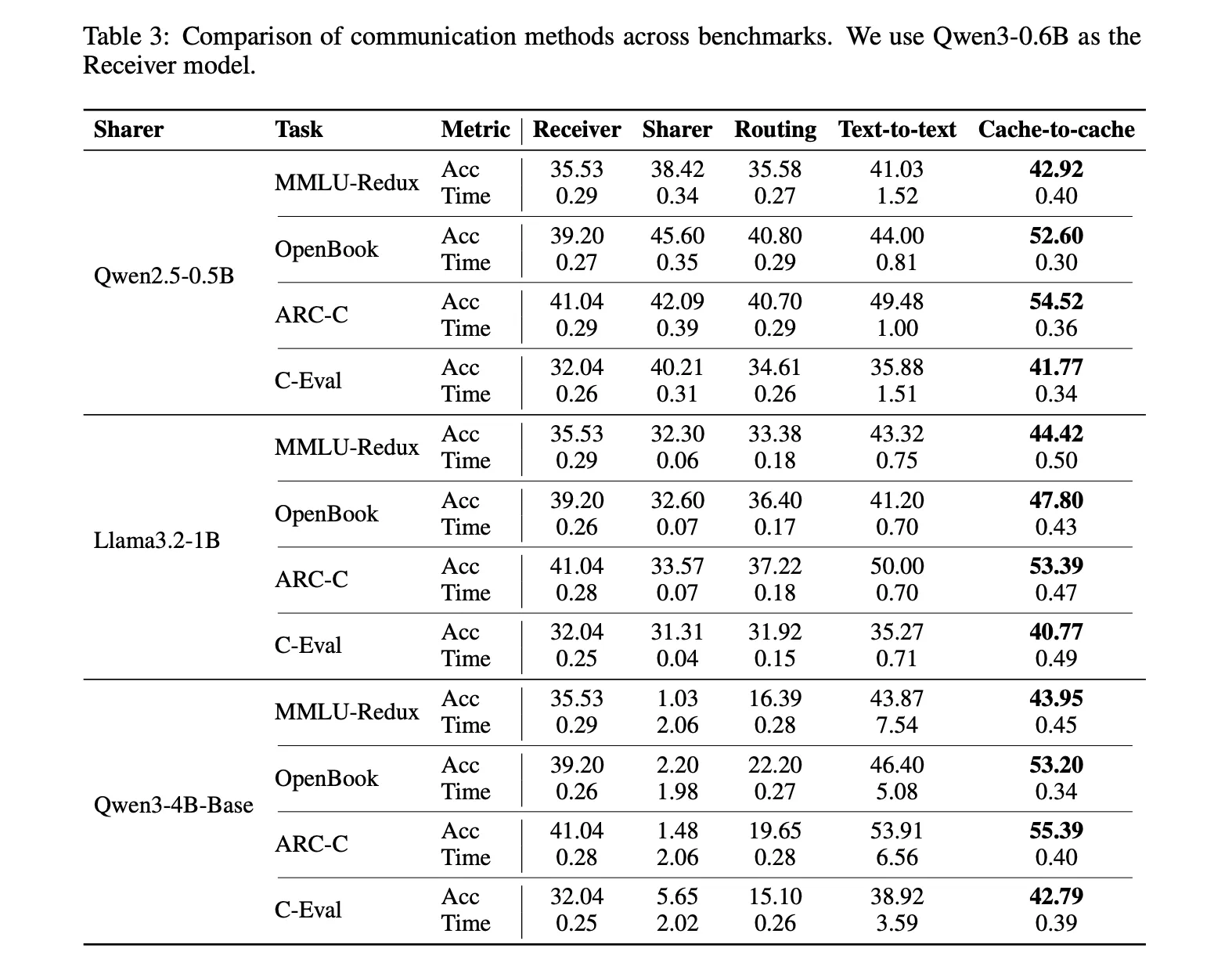
A cheat example uses Qwen3 0.6b as the receiver and qwen2.5 0.5b as the sharer. In MMLU Redux, only receiver reaches 35.53 percent, text to text reaches 41.03 percent, and C2C reaches 42.92 percent. The average time per query text to Text is 1.52 units, while C2C stays close to the single model at 0.40. Similar patterns appear in OpenBookqa, ARC challenge and C Stud.
In Longbenchv1, with the same pair, C2C Ofterforms Prenscoment Publication communication in all buckets of consecutive length. With a range of 0 to 4k tokens, text communication reaches 29.47 while C2C reaches 36.64. Icons are always 4K to 8k and longer.
Key acquisition
- Cache connection to cache It allows the shared model to send information to the receiving model directly through KV-cache, so the interaction does not require intermediate messages, eliminating the loss of modern model systems.
- Two Oracle courses Show that enriching only the query corresponding to the piece of cache improves the accuracy of the planned length, and that the KV-cache from the small model space can be placed in the small project space, confirming the cache as a virtual communication method.
- C2C FUSER properties Combine shared wrappers and cacheiver caches with the Projection module, Dynamic Head weight and each gate of the layer, and includes everything in the path that was left, which allows to accept abremer anger abror semantics without reversing its representations.
- Consistent accuracy and latency gains they are seen across QWEN2.5, Qwen3, LLEN3.2 and gemma3 model models, with 10.5 %% getting more accurate than one model, and 2x faster responses because fast smearing is removed.
Cache-to-cache is a cache-to-move LLM multi-interface as a direct semantic transfer problem, not an engineering problem. By inserting a KV-cache between the participant and the receiver with a neural fuser and learned gaiting, C2C uses high semantics exclusive to both models while avoiding clear middleware bottlenecks and latency costs. With 8.5 to 10.5% higher accuracy and 2x lower than text communication, C2C is a strong step to the limits of the level of KV interaction between models.
Look Paper and Codes. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



