Ant Ling Team Release 2.0: Demonstration series of consultations – Moe's first is built on the law to work individually with the power of consultation

How do you build a language model that grows in volume but keeps the integration of each addressee almost unchanged? The ANGNUSISIT AI team from the ANT team is compressing large sparse models in a way to extract Ling 2.0. LING 2.0 is a demonstration of a language-based language model based on the idea that every action should translate directly into a powerful cognitive behavior. It's one of the latest ways to show how you can keep working small while moving from 16b to 1t without rewriting the recipe. The series has three versions, Ling Mini 2.0 in 16B total with 1.4B activated, Ling Flash 2.0 in the 100B category with 6.1b activated with 1b activated per TOKEN.
Sparse moe as medium composition
Every Ling 2.0 model uses the same sparse mix of expert layouts. Each layer has 256 customized information and one shared expert. The router takes 8 experts competing for every token, the shared expert is constant, so it's about 9 experts who won out of 257 already used for a ratio of 1/32. The research group reports 7 times more efficiency compared to the same fuzzy model because you train and serve a smaller part of the network per token while maintaining a much larger parameter pool.
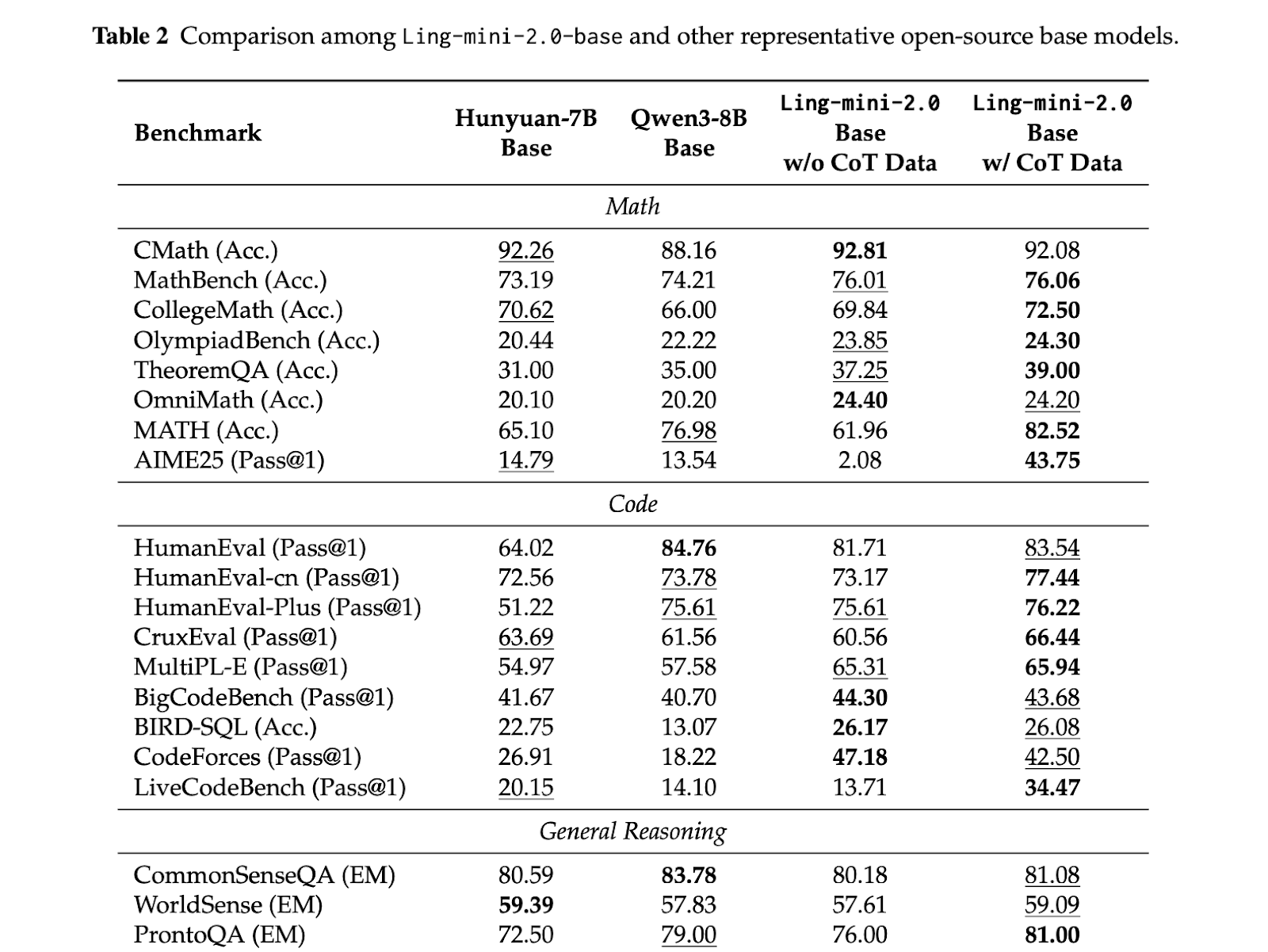
Ling 2.0 brings integrated progress across four layers of the stack, model architecture, pre-training, post-training and underlying FP8 infrastructure:
Model Architecture: Construction is chosen using the rules of proportionality, not by trial and error. To support the measurement rules, the group runs what they call the Ling wind tunnel, a limited set of MOE runs under the same specifications as the voluntary rules, and then it is put into the money of the prediction power in a very large size. This gives them a low-cost way to choose between 1/32, 256 competing experts and 1 written expert before implementing GPUS at 1T scale. Routing is AUX-lossy SigMoid Scoring, and the stack uses standard QK, MTP loss and partial threading to maintain stable depth. Because the same rule chose the composition, 2 mini mini
Prior training: This series has been trained on more than 20t tokens, from the context of 4K and mixing where heavy sources such as statistics and code are shown gradually increasing the portion of the corpus. The mid-year training stage reaches 32K on the 150B selected token market, then adds another 600b of high-quality tokens for consideration, before finally extending 128k on a short leash while maintaining short quality. This pipeline ensures that the long context and logic are introduced early, not just added to the SFT step.
Post Training: Alignment is divided into COOCK BASS and preferred pass. First, well-intentioned planning teaches the model to switch between quick responses and deep deliberation through the renewal of a different system, then the environmental policy situation expands and finally the sentence-level policy situation, and finally the group-level policy situation with pure human character fields in human races in Group Adgeraction. This constrained alignment is what allows a non-thinking foundation to access mathematics, coding and teaching without increasing the overall response.
Infrastructure: LING 2.0 trains natively with FP8 with protections, keeping the curve loss within the narrow gap of BF16 while achieving 15% utilization of the reported hardware. Great speeds, around 40 percent, come from the heterogeneine pipeline parallelism, connected one forward execution to the other and separation known as MTP block, not only in accuracy. By cooperating with stable integration, which replaces the decomposition of LR by combining test points, this stack company makes the 1T scale work well in existing clusters.
Understanding the results
Testing is not consistent in pattern, small functional moe models deliver competitive quality while keeping every token low. The Ling Mini 2.0 has 16B parameters, works 1.4B per token, and is reported to perform a dense band of up to 8b. (Reddit) Ling Flash 2.0 keeps the same 1/32 activation recipe, has 100b and activates 6.1B per token. Ling 1T is an abstract reasoning model, it has 1t and 50b active parameters per token, maintaining 1/32 sparsity and extending scaling rules that are compatible with millions.
Key acquisition
- Ling 2.0 is built around a 1/32 activation MoE architecture, selected using Ling Scaling Laws so that 256 routed experts plus 1 shared expert stay optimal from 16B up to 1T.
- Ling Mini 2.0 has 16B parameters with 1.4b sing per Token and is reported to match 8b tokens up to 800 tokens per second with H20.
- Ling Flash 2.0 keeps the same recipe, with 6.1b active parameters and staying in the 100b range, offering the option of higher skills without increasing each token compute.
- Ling 1t features full build, full 1T parameters with 50B active per token, 128k core, and Evo Cot Plus LPO training style active compression.
- For all sizes, circling more than 7 times more than the returned bases is obtained by a combination of sparseization, FP8 training, and quality scaling by considering non-scripting.
This release shows the full stack of sparse moe. The measurement rules identify 1/32 performance as efficient, building keys in 256 directed accidents decorated and shared common scholar, and 16 were used. Training, context expansion and preferred optimization are all compatible with what is selected, so small performance does not prevent calculations, code or long context, and fp8 pipelines and heterogeneous Save costs in active applications. It is a clear indication that billions of trillions of thoughts can be arranged in a systematic order instead of scaling up a large computer.
Look Weight in HF, repo and paper. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.
 Open Model with 21B Functional Parameters and 256K Content")


