Meta Ai 'FIRST experience' Train 'Training Language Agents Without Rewards – and Immigration

How does your agent change if the policy can only train from its outcomes – free rewards – no rewards, no demo basic studies? Meta Superintagence Labs Propose 'The first experience', The unconscious training method that promotes policy readings on language agents except major setbacks for people and without learning alignment (RL) in the main loop. Basic idea is simple: Let the agent branch from the pillar states, pick it up, collect it Resulted in the futureThen change those results into monitoring. The CASTIONA research team This is a deformed primary topic-The IFENCE World Modeling (ewm) including Meditation (sr)-Pranish consistent benefits in eight places and many basic models.
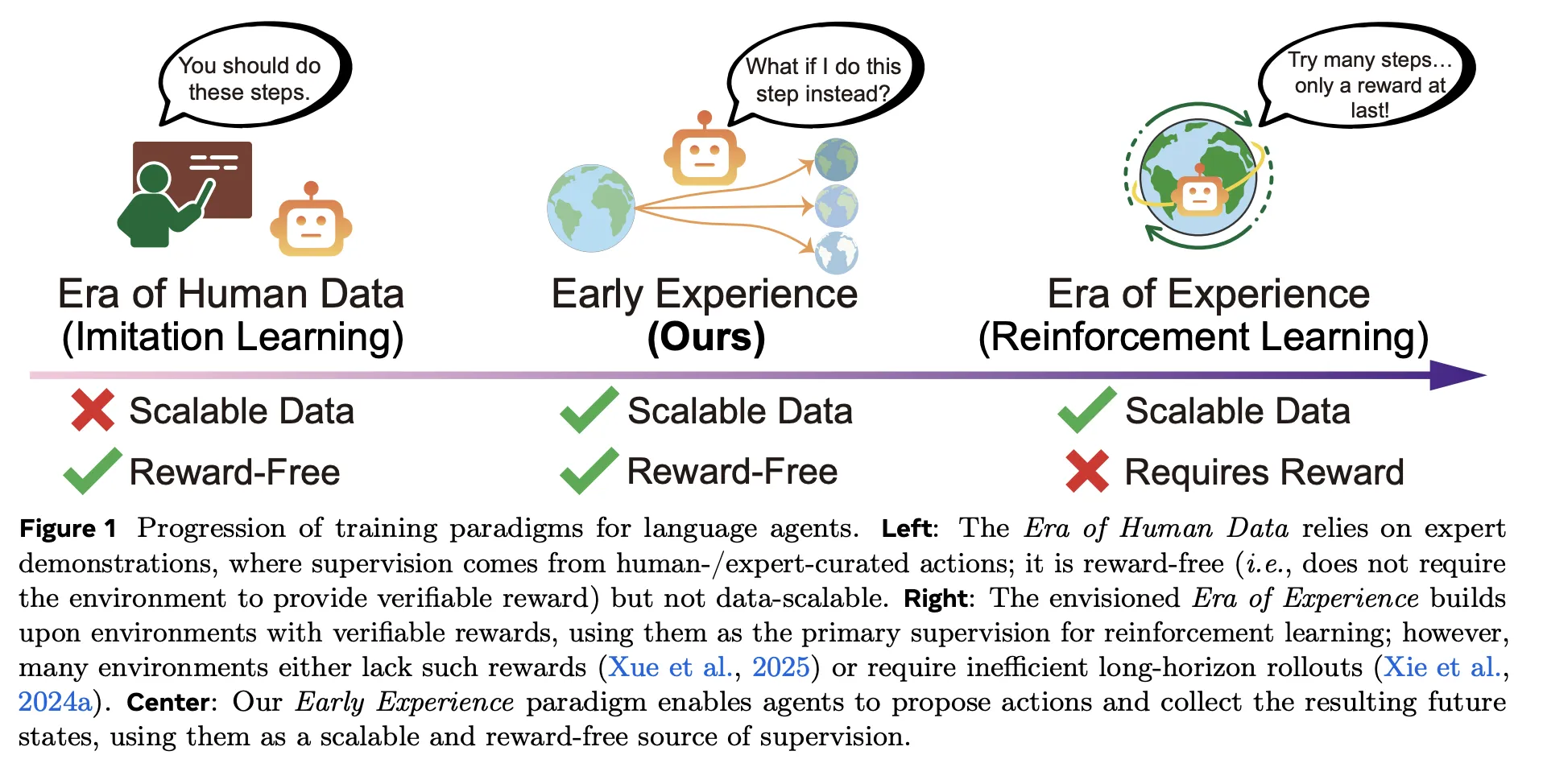
What is the first information change?
Traditional pipes dependent Imitating Reading (il) over specialist, cheap trajectories to expand but it is difficult to measure and absorb distribution; Emphasizing reading (rl) Promising reading from experience but requires certified rewards and stable infrastructure – often lost in web settings and multiple traffic. The first experience sits between them: so rewarding love Imitating Reading (il)But direction is visible The results of the agents itselfnot only professional actions. In short, the agent lifts, works, and reads from what is happening next – no reward work is needed.
- The IFENCE World Modeling (IWM): Train the model forecast Next observation If you have been given the state of the state and the selected action, it strengthens the internal agent of environmental vynamics and reducing policy drafting.
- Self-centered (sr): The current expert and other different things in the same situation; Have a model explaining Why is the professional action better Using visible results, and discuss the policy from this different signal.
Both strategies use similar budgets as decorative settings such as IL; Only the source of different data (branches produced by agents instead of the surface trajectories).
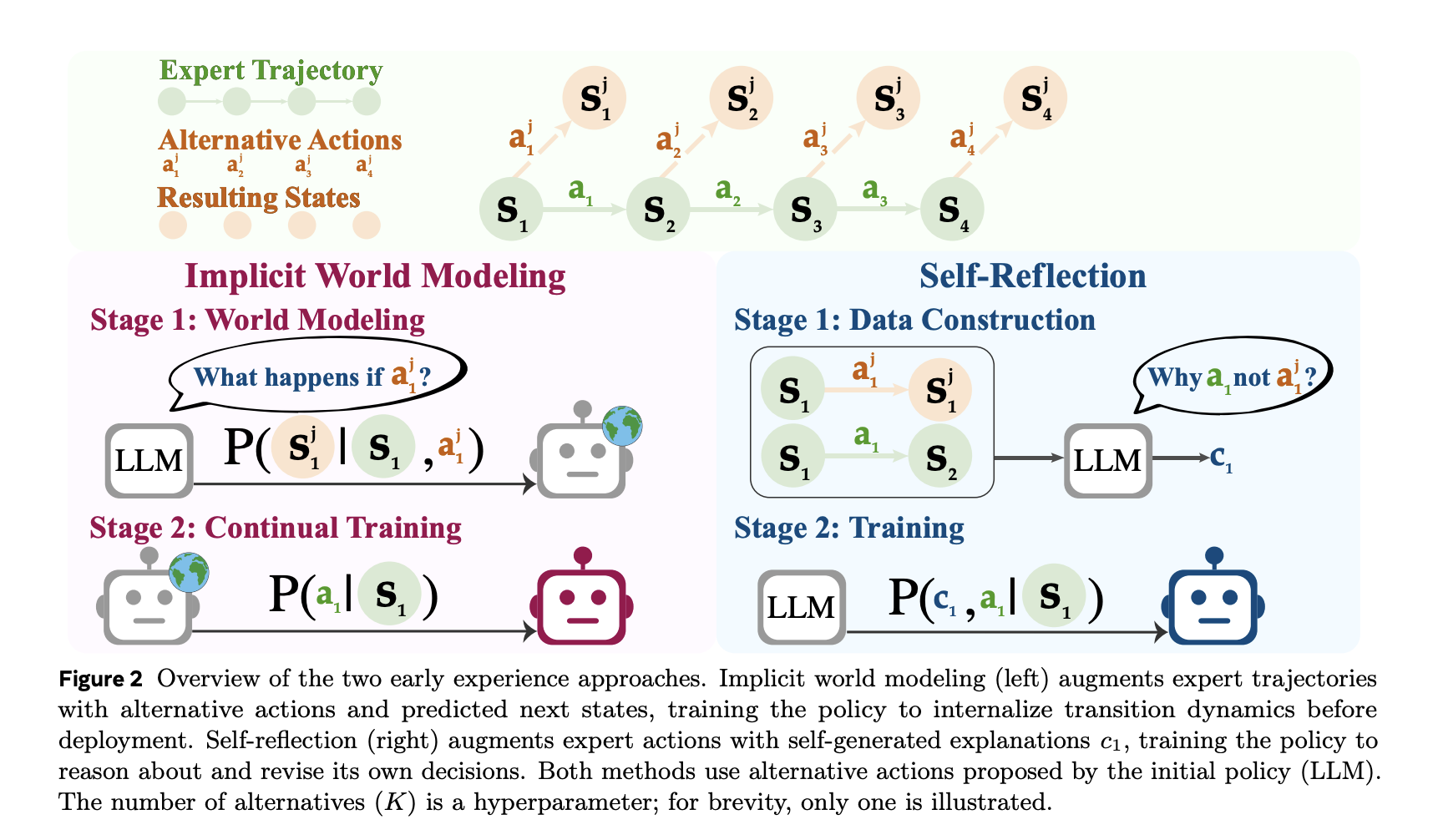
Understanding benches
The research team examines it eight Agent-agent-agent traveling areas, long planning, scientific / integrated activities, and the travel of the API functional-Domain API- Webshop (browsing applications), Travelplanner (The richest planning of stress), Scientowworld, Alfworld, Tau-benchwith others. The first experience ambition Complete Raining Rains of +9.6 Success including +9.4 Out-of-Domain (OOD) over the perfect IL matrix of jobs and models. These benefits are underwhelming when apples are used Get RL: (GRPO), improve post-rl roof by +6.4 compared to Emphasizing reading (rl) started from Imitating Reading (il).
Working well: Underlying expert data, the same budget for good use
The actual key is that Demo's well-performance. And the budget for planned, The first experience Parallels or beat IL using a piece of a scholar data. Despite of- Webshop, 1/8 of the exhibition with The first experience already passing Il is trained at the full demo Set; despite of- AlfworldEquity is beaten 1/2 Derms. Benefits grows with additional demonstrations, which indicates that the unexpected provinces of the agent provides symptoms of monitoring.
How Data is built?
Pipeline seeds from a limited set of expanding is to find independent provinces. In selected provinces, the agent suggests Different actionsget them away, record them The following is viewed.
- A Members EwmTraining data is Triplets ⟨state, action, Next-State⟩ and purpose Forecast for the following state.
- A Members Srmotivated include technical action and many other forms and outcomes. The model produces a Practical Reason Explaining why specialist action is popular, and this is used to improve policy.
Where the reading is to be certified (RL)?
The first experience Is – “Rl without rewards.” It is guarded recipe The results with an Agent Like the labels. In certified voices, the easiest research team Add RL in the background The first experience. Because the implementation is better than IL, the Same schedule of rl It goes up and quickly, with Up to +6.4 Last success above IL-Genying RL integrated with checked backgrounds. This puts the first experience as bridge: Pre-reward training from results, followed (where possible) with Standard Emphasizing reading (rl).
Healed Key
- Free Training With Reward With Agent – Producted The World to come (not reward) using The perfect World Model including Meditation Imitation of Outperforms imitations in all eight places.
- Reported complete profit of IL: +18.4 (WebShop), +15.0 (Travplanner), +13.3 (ScienceWorld) under the same budgets and settings.
- Demo's well-performance: passes il in webshop with 1/8 of demonstrations; reaches the alfworld parity with 1/2-Atly prepared cost.
- As the first, The first experience Boosts Supsequent RL (GRPO) Endpoints by Up to +6.4 Versus rl started from IL.
- Verified in many Backbile (3B-8B) families with domain development and domain cells; placed as a bridge in the middle Imitating Reading (il) including Emphasizing reading (rl).
The first experience Is a Pragnican contribution: Only the Britle Mosune-Only Income to add the higher higher level from the agent it can be generated. Different World Models (Next predicting speculation in Anchor Envirection Dynamics) and reflecting the consistent in the military) – an attack on eight in the area used as the GRPO initializer. In situations of the web and tool when vindicated rewards are scarce, this reward does not mean anything between IL and RL and works quickly in the production agency.
Look Paper here. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper. Wait! Do you with a telegram? Now you can join us with a telegram.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
Follow MarkteachPost: We have added like a favorite source to Google.



