Meet VoStream: Voro-Stwork Voru-Zero-Zero-Shot TTS original use first speaking from the first word

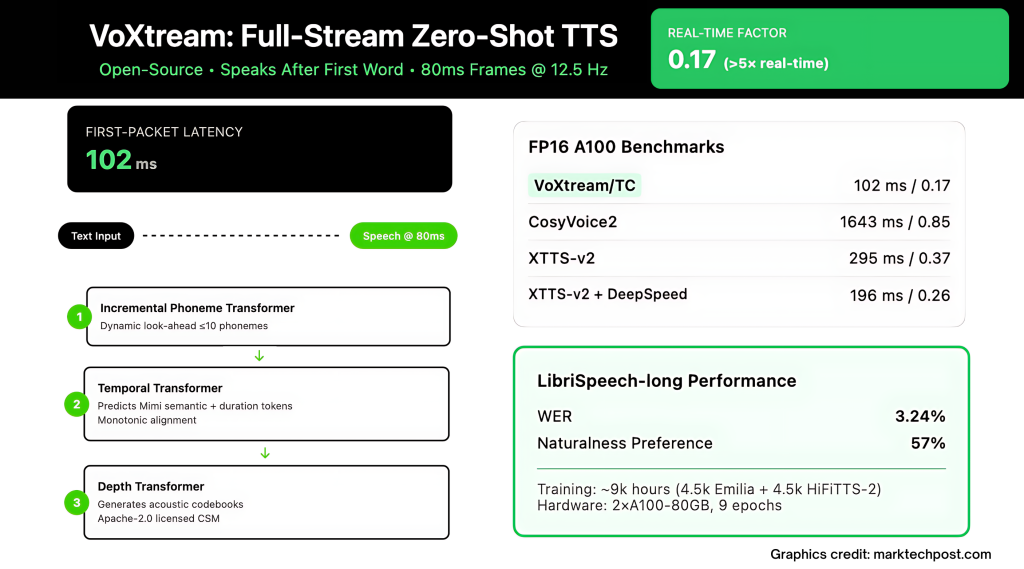
Real-time agents, live translation, and to translate the same time to a thousand milesecons. “The distribution of” TTS (Text to Expeence) Stacks are still waiting for the text chunk before they have issued a sound, so one feels peaceful beat before the Word begins. VOXTRAM-DO RED IN KITH, MUSIC AND TRAINING TRAIN THIS TRAW: It's starting to talk After the first namean audio-outgoing output in 80 MS privateand reports 102 MS First Packet Latency (FPL) in modern GPU (with Pytorch Complete).
What does “full spread” TTS and different from the “output” distribution?
Outgoing broadcast systems leave the talk with chunks but seek All Input Text forward; Clock starts late. Full stream Systems using text As it arrives (word word from the llm) and the soundstep sound. VOXTREAM uses the last: Inserts the words in addition to the broadcasts and produces audio-visual frames continuously, removing buffereing and stores low compute. The construction of buildings is clearly intended to establish the beginning of the first words rather than only a solid.
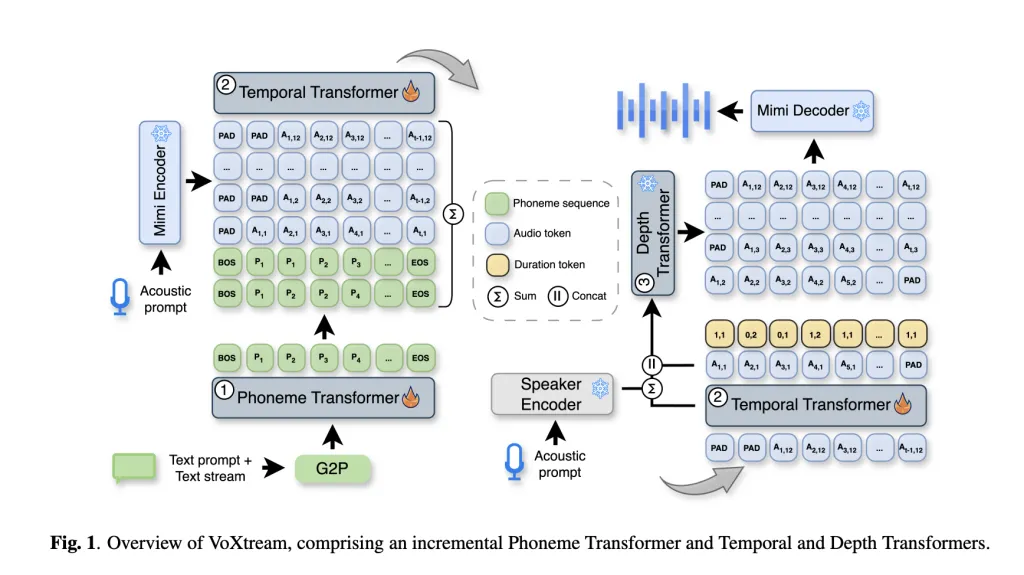
How does Voxtror Raise speak without waiting for future words?
The basic trick is this Dynamic Poneme look-forward inside a Increased Poneme Transformmer (PT). The color of the models maybe Peek until 10 Phones strengthening prosody, but It does not wait For that context; The generation can start immediately after the first name comes into a buffer. This avoids organized windows added to the first delay.
What is the stack model under the hood?
Voxtream is the Single, Completely-autoregripent (ar) Pipe with three transformers:
- Phoneme Transformer (PT): Decoder-only, climbing; Strong appearance – forward ≤ 10 phonets; Phonemic disease with G2PE at word level.
- Temporary transformer (TT): AR Preaator over Me measure Semantic tokens as well as a Time token That includes monotonic phone-to-audio alignment (“Stay / Go” and {1, 2} Ponemes on each frame). Ann runs at 12.5 hz (→ 80 ms frames).
- Deleting Design (DT): A ar of the ar of the mimi already left Acoustic codesThere is a situation at the outdoor TT and a Lower The speaker embursime Zero-shot The Word builds. Dicoder DECORROCOURROR RESUCTING THE WIVEFORM FRAME-DOWN DOWN, enabling continuous exit.
Codec for MIMI CODE to broadcast and the fast-documented monitoring; VOXTREAM USE its first CodeBook as the “Semantic” and high reconstruction.
Is it really quick to practice – or just “faster on paper”?
The last place includes a Benchmark script That's estimating both FPL including Real-time feature (RTF). Despite of- A100Research team report 171 ms / 1.00 vtf Without combination again 102 MS / 0.17 RTF By integrating; despite of- RTX 3090, 205 ms / 1.19 vtf does not work again 123 ms / 0.19 vtf combined.
How compared with modern popular broadcasting foundations?
Research team checks The distribution of a short form form including full stream Conditions. Despite of- Librispecteech-length Full distribution (where text arrives-by name), Voxtream shows WER WER (3.24%) than Cosyvoice2 (6.11%) as well as a The most popular of nature With voxtream in the alaler Study (p ≤ 5E-10) While Cosyvoices2 Points are the same exactly like a speaker – agrees with his flip decoder. At the time of launching, Voxtream has a very low FPL between the comparisons of public broadcastingand by combining it works > 5 × faster than real time (RTF ≈ 0.17).
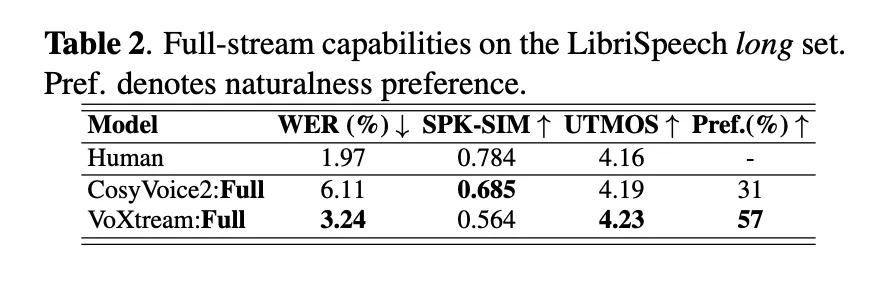
Why is this a Ar crowned by Flow / Flow Stacks in the entry?
Viocessions / flow vocoders usually produce the sound within ChunksTherefore whether the Audio Connection is smart, Voca Shoider puts down the first pack of package. Voxtream is keeping All categories ar and frame-synchronous-Pt → Tt → DT → → 80 ms The package appears after one passage in stack rather than a multi-steps. A survey of the previously submission and integrated methods and explains how Decoders are sprayed used in the IST-LM and Cosyvoice2 Prevent the low FPL despite the steady quality of online.
Did they come here with large data – or something little and clean?
Voxtream trains in ~ 9K-HOUR MID-SCALE CORPUS: About 4.5Khhh Emilia including 4.5Khh HIFITTS-2 (22 kHz sumset). Group Diarised To remove multiple speaker clips, Slarged Scriptures Using Asr, and worked Viola disposing of a low level sound. Everything has been rebuilt 24 khzAnd the Database card shows the art of Pipeline Pipeles Popressing (MIMI Tokens, Compliance of the MFA, Times Labels, and Special Tables).
Does the quality of heads of heads hold on without selected cherry fragments?
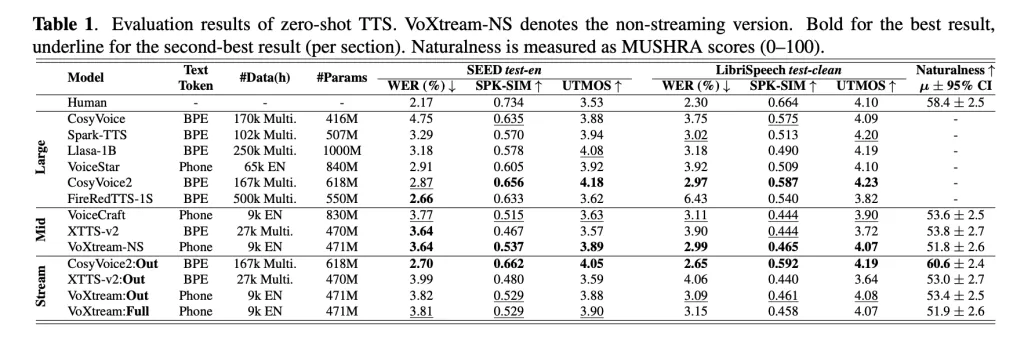
Table 1 (Zero-shot TTS) shows VOXTREAM Compete Other Page False, Utmos (Mos Predictor), and Speaker matches abroad Seed-TS test-en including Librispecteech Test-Clean; The research team also runs Variety: Adding CSM Deadness Transformer including Madam Speaker Obviously optimizes similarities without an important penalties related to the free basic basis. The study is using protocol like Mushra and a second phase testing that complies with the full generation.
What country is this TTS site?
According to the research paper, it puts voxtream among the latest InderLEAVED AR + NAR VOCERDER approaches Lm-codec Stacks. The basic donation is not a new codec or a large model – it is Arrival of Ar focused Ar as well as a Turation-toke that is the preserved Substyclock Spread. If live agents, important trading is clear: Small down the same vs. Order-of-Magnitutue low FPL There are nar vocoders in full conditions.
Look Paper, model in kissing, GitTub page including The project page. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Content Collaboration / promotion in MarkTechPost.com, please talk to us
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
🔥[Recommended Read] NVIDIA AI Open-Spaces Vipe (Video Video Engine): A Powerful and Powerful Tool to Enter the 3D Reference for 3D for Spatial Ai
 Open Model with 21B Functional Parameters and 256K Content")


