Google Cloud AI Research Introduces ReasoningBank: A Memory Framework That Decomposes Reasoning Strategies From Agent Success and Failure

Most AI agents today suffer from the basic problem of amnesia. Use one to browse the web, troubleshoot GitHub issues, or navigate the shopping mall, and it approaches every single task like it's never seen anything like it before. No matter how many times he stumbles upon the same type of problem, he repeats the same mistakes. Valuable lessons evaporate when the job ends.
A team of researchers from Google Cloud AI, the University of Illinois Urbana-Champaign and Yale University presented ReasoningBanka frame of memory that not only records what the agent does – it dissolves it why something that has worked or failed in reusable, generic thinking techniques.
Problem with Existing Agent Memory
To understand why ReasoningBank is important, you need to understand what the agent's existing memory actually does. Two popular methods are trajectory memory (used in a system called Synapse) and workflow memory (used in Agent Workflow Memory, or AWM). Trajectory memory stores raw action logs – every click, scroll, and typed query used by the agent. Workflow memory goes further and extracts reusable step-by-step procedures effectively it only runs.
Both have critical blind spots. Raw trajectories are noisy and too long to be directly useful for new tasks. The workflow memory only captures successful attempts, which means that the rich learning signal buried in every failure – and the agents that fail the most – is completely discarded.
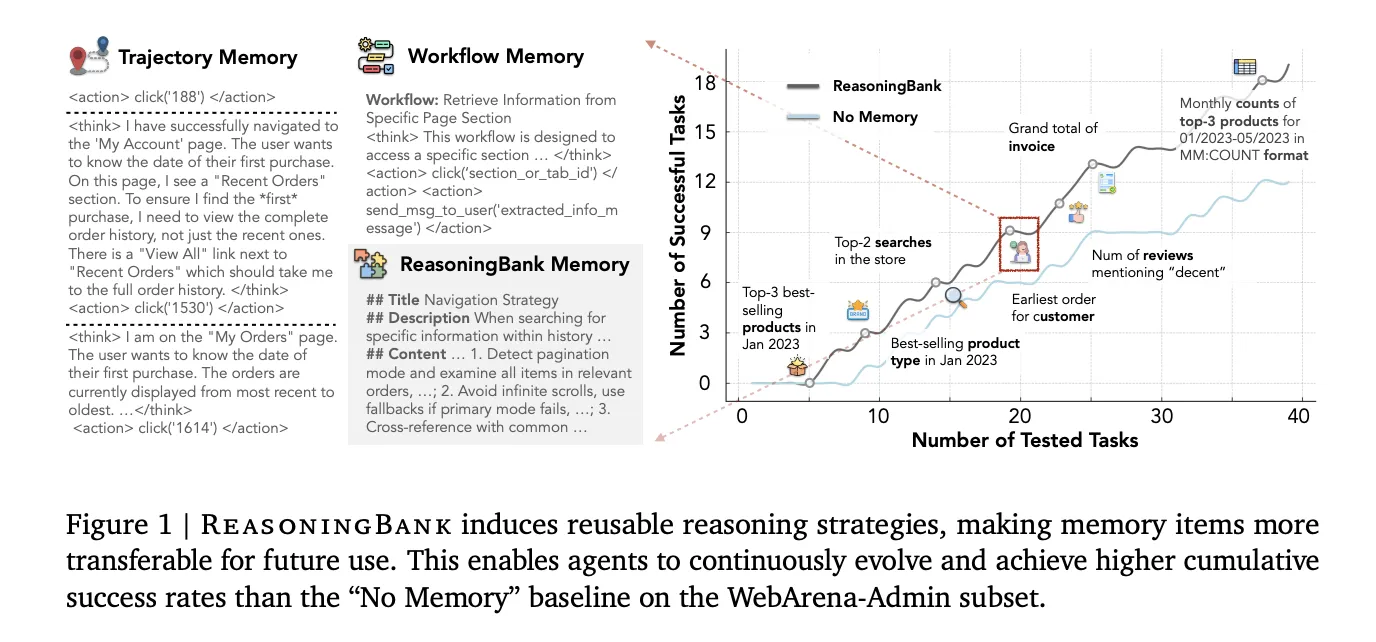
How ReasoningBank works
ReasoningBank works as a closed memory process with three sections running around the completed tasks: memory retrieval, memory retrieval, again to strengthen memory.
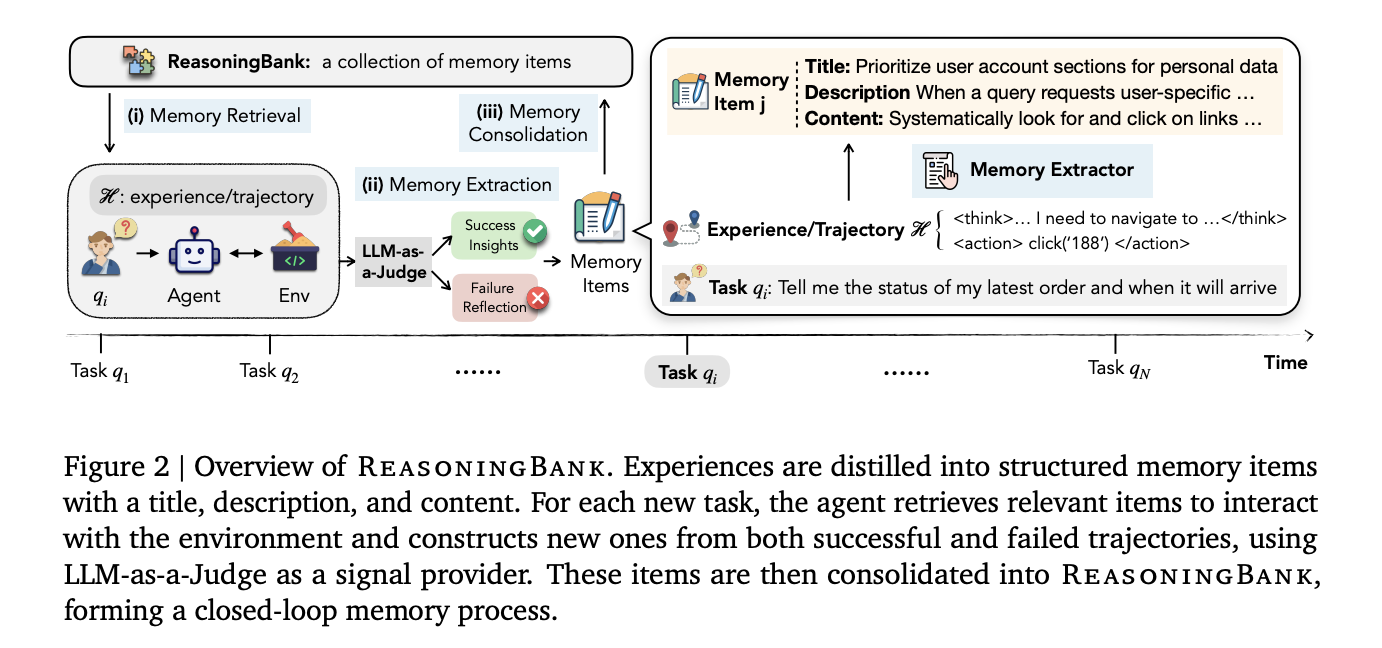
Before the agent starts a new task, it queries the ReasoningBank using an embedded match search to find the top-k the most appropriate memory materials. Those objects are injected directly into the agent system as additional content. Importantly, the default is k=1, one returned memory object per function. Ablation tests show that retrieving more memories actually hurts performance: the success rate drops from 49.7% for k=1 to 44.4% for k=4. The quality and consistency of recovered memory is more important than quantity.
When the job is done, a Memory Extractor – powered by the LLM of the same backbone as the agent – analyzes the trajectory and decomposes it into structure memory objects. Each item has three parts: a the subject (short name for technique), a definition (one sentence summary), and content (1–3 sentences of stripped-down thinking steps or operational details). Unfortunately, the extractor treats successful and failed methods differently: success offers proven strategies, while failure offers false pitfalls and prevention lessons.
To determine whether a trajectory is successful or not – without access to the ground truth labels during testing – the system uses LLM-as a judgewhich outputs a binary decision of “Success” or “Failure” given the user's query, trajectory, and final page status. A judge does not need to be perfect; Exclusion tests show that ReasoningBank remains strong even when the accuracy of judges drops to around 70%.
New memory items are then added directly to the ReasoningBank store, which is stored as JSON with a computer-generated embedding in a fast cosine similarity search, completing the loop.
MaTTS: Matching Memory and Test Time Measurement
The research team goes ahead and presents it memory-aware test-time scaling (MaTTS)linking ReasoningBank to computerized testing time – a process that has already proven powerful in mathematical reasoning and coding tasks.
The understanding is simple but important: measuring during testing creates multiple trajectories for the same task. Instead of simply choosing the best answer and discarding the rest, MaTTS uses the full set of trajectories as rich alternative signals for memory retrieval.
MaTTS enters two ways. Parallel scaling build it k independent trajectories of the same question, then use comparing themselves – comparing correct and incorrect in all trajectories – extracting high-quality, highly reliable memory objects. Sequential scaling iteratively refines a single trajectory using self developmentcaptures intermediate corrections and details such as memory marks.
The result is a positive feedback loop: better memory directs the agent to more promising releases, and richer releases create even stronger memories. The paper notes that for k=5, parallel scaling (55.1% SR) outperforms sequential scaling (54.5% SR) in WebArena-Shopping – the sequential benefits quickly accumulate if the model reaches success or failure, while parallel scaling ends up providing different outputs that the agent can compare and learn from.
Results on Three Benchmarks
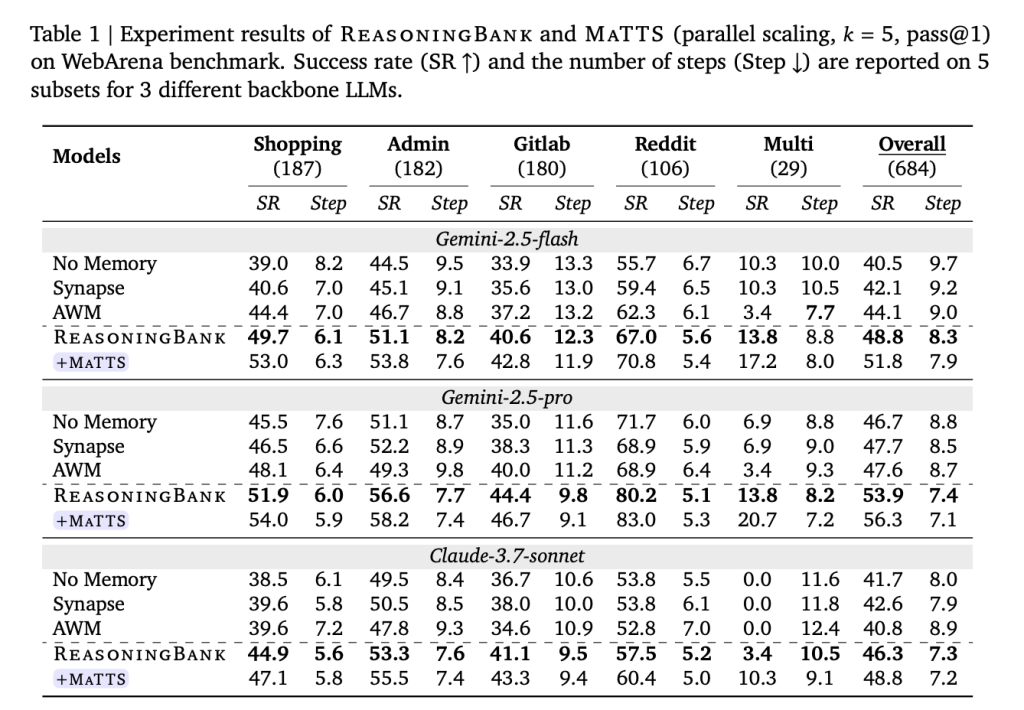
Tested on WebArena (a web navigation benchmark that includes shopping, management, GitLab, and Reddit functions), Mind2Web (which tests overall functionality, cross-website, and domain settings), and SWE-Bench-Verified (a software engineering benchmark with 500 verified from all three categories), datasets and all basic tested models.
In WebArena with Gemini-2.5-Flash, ReasoningBank improved the overall success rate by +8.3 percentage points over the memoryless base (40.5% → 48.8%), while reducing interaction steps by up to 1.4 compared to memoryless and up to 1.6 compared to other memory bases. The benefits of efficiency are very sharp effectively trajectories — for a subset of purchases, for example, ReasoningBank cuts 2.1 steps to successful transaction completion (26.9% reduction). The agent reaches solutions quickly because it knows the right way, not just because it quickly abandons failed attempts.
In Mind2Web, ReasoningBank brings consistent benefits to all cross-task, website, and cross-domain testing, with the most prominent improvements in the cross-domain setting – where the highest level of transfer of strategies is required and where competing methods such as AWM are in fact. degrade relative to the memoryless base.
In SWE-Bench-Verified, the results vary depending on the backbone model. With Gemini-2.5-Pro, ReasoningBank achieves a 57.4% resolution rate compared to 54.0% of the memoryless baseline, saving 1.3 steps per task. With Gemini-2.5-Flash, the step savings are quite impressive — 2.8 steps per task (30.3 → 27.5) corresponding to the improvement of the resolution rate from 34.2% to 38.8%.
Adding MaTTS (parallel rate, k=5) pushes the results further. ReasoningBank with MaTTS is accessible 56.3% overall SR on WebArena with Gemini-2.5-Pro - compared to 46.7% of the base without memory – while also reducing the average steps from 8.8 to 7.1 per task.
Emergent Strategy Evolution
One of the most striking findings is that ReasoningBank's memory is not static – it changes. In a written study, the first items in the agent's memory for the “User-Directed Information Navigation” strategy resemble simple process checklists: “actively look and click on the 'Next Page,' 'Page X,' or 'Load More' links.” As the agent accumulates information, those same memory objects mature into dynamic reflection, then systematic pre-task evaluation, and finally integration strategies such as “always cross-reference the current view with the task's requirements; if the current data does not match expectations, it re-examines available options such as search filters and other categories.” The research team describes this as an emergent behavior similar to reinforcement learning – which occurs entirely during the test, without weight updates of the model.
Key Takeaways
- Failure is ultimately a sign of learning: Unlike existing agent memory systems (Synapse, AWM) that only learn from successful trajectories, ReasoningBank integrates general reasoning techniques from both success and failure – turning mistakes into protective instruments for future careers.
- Memory objects are built, not raw: ReasoningBank does not keep dirty action logs. It compresses experience into pure three-part memory objects (title, description, content) that can be interpreted by a human and injected directly into the agent system by searching for embedding-based similarities.
- Quality exceeds return value: Total return is k=1, one memory item per function. Retrieving more memories gradually hurts performance (49.7% SR for k=1 drops to 44.4% for k=4), making the consistency of retrieved memory more important than volume.
- Memory and test timing create a virtuous cycle. MaTTS (aware memory testing time) uses various test methods as countersigns to build stronger memories, which in turn lead to better testing – a feedback loop that pushes WebArena's success rates to 56.3% with Gemini-2.5-Pro, from 46.7% with no memory.
Check it out Paper, Repo again Technical details. Also, feel free to follow us Twitter and don't forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



