KGGEN: The Improvement of Graph Extraction translated into the languages of languages and consolidation strategies

Information graphs (KGAs) are the basic of the Intelligence application of artificial requests but are not perfect, affecting their performance. Well-established Kgs such as DBPEPIA and Wikidata do not have important business relationships, reduce their work in the Refunds of Refund (RAG) and other machine learning activities. Traditional release methods may provide sparse graphs with important or noisy connections, unwanted presentations. It is therefore difficult to get the best quality information in the random text. Overcoming these challenges is important to enhance the restoration of advanced knowledge, thinking, and understanding of the help of artificial intelligence.
Kingdom paths to remove KGS in an unripe text for open information and gravity. Openie, a dependency on the dependence of, produces systematic (title, relationships) three times but produces very complex and incessant sites, reducing compliance. Graphrag, including Restoring Models Return DirectEval and Language, enhance the business that links but does not produce highly graphs, which restricts the process. Both of these lists are afflicting the organization to solve the consensus, sparkity in communication, and complete normal, release them without successful KG.
Stanford University investigators, at the University of Toronto, the Ai-Toronto-to-Kg Generator has set up language models and joint algorithms to remove formal information in the organized text. Unlike the front routes, the KGGEN presents the LM-based method of LM developing a graph-related graph by integrating similar businesses and organizational relationships. This improves the sparsity and recycling, provides a corresponding and well-connected KG. KGGEN and introduce Mine (information rate), benchmark of the implementation of the text, enabling standard measures of issuing methods.
KGGEN is working on a dynamic python pack with business modules and the issue of relationships, integration and organization and the merger of the border. Organizational module and relationship discharge uses GPT-4O to get triplies (title, forecast, item) in a random text. Aggregation Module includes triples released from different sources into integrated knowledge of information (kg), which is why it is sure to be a fine for the penalty. The organization's organization and the edge of the edge uses the heatative algorithm to distinguish symonyonystitures ormogos, the same conclusion, and to develop graph's connection. By using strong obstacles to the language model using DSpy, KGGEN enables access to the formal release and high reliability. The outcome graph is divided by its cramped communication, semantic compliance, and the performance of artificial spies.
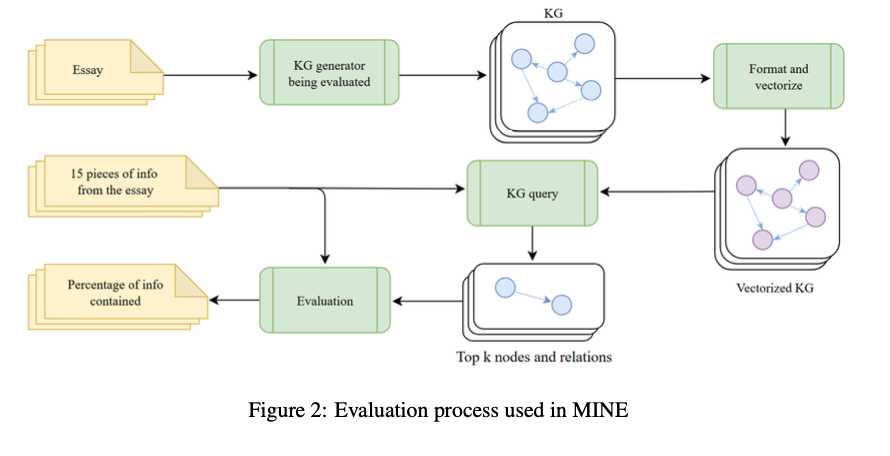
The effects of measuring the icon indicates the success of the way in removing systematic information from text sources. KGGEN receives a rate of 66.07%, more than Graphrag at 47.80% and Openie in 29.84%. The program helps the power to discharge and manufacture information without repeating and improving communication and compliance. Comparing analysis confirms the development of 18% in the reliability of the issuing systems, highlighting its power to produce proper organized information graphs. The exam indicates that the graphs are produced by DENSER and educated more, which makes them particularly prepared in the contexts of the information and thinking based on AI.
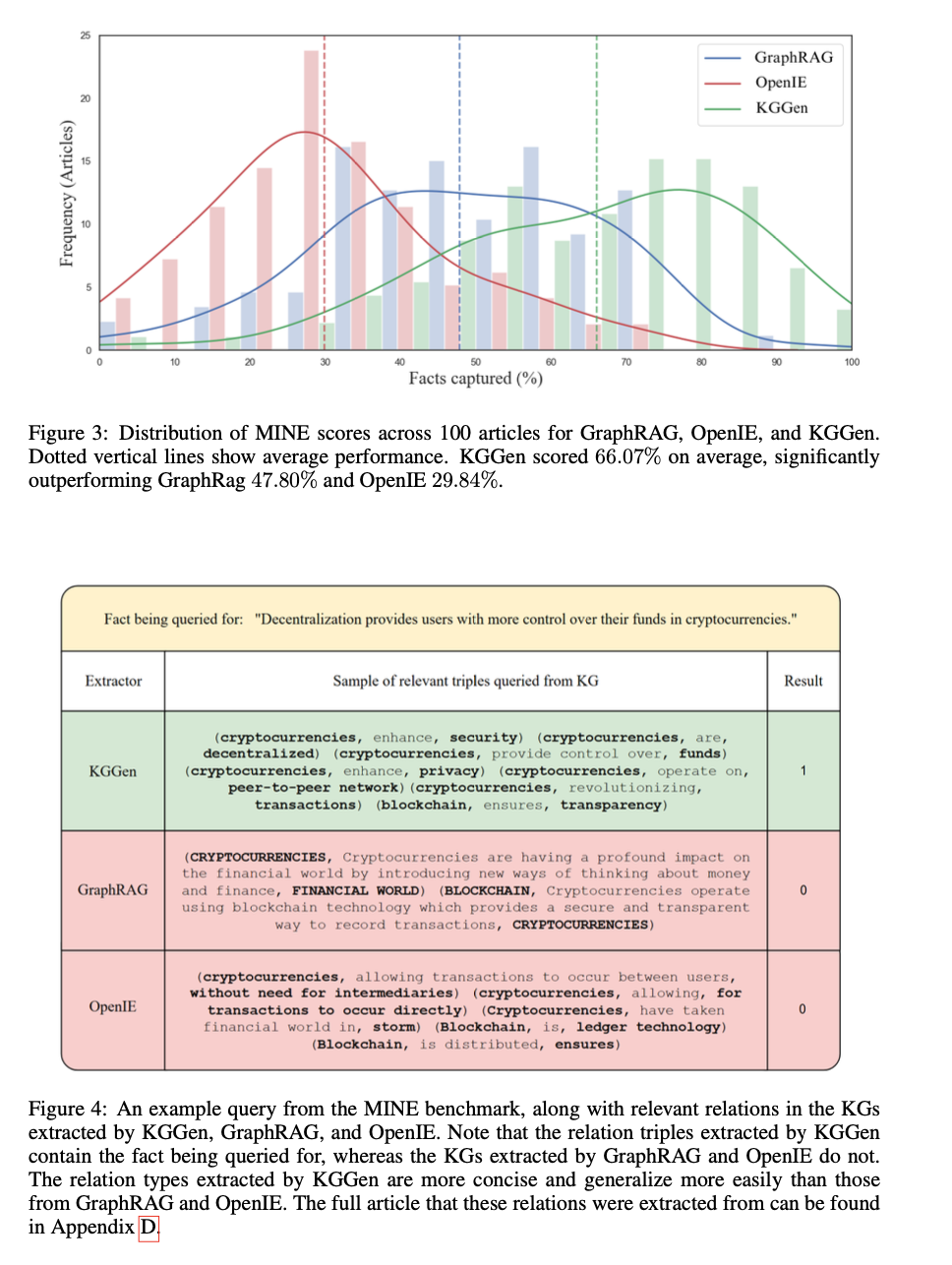
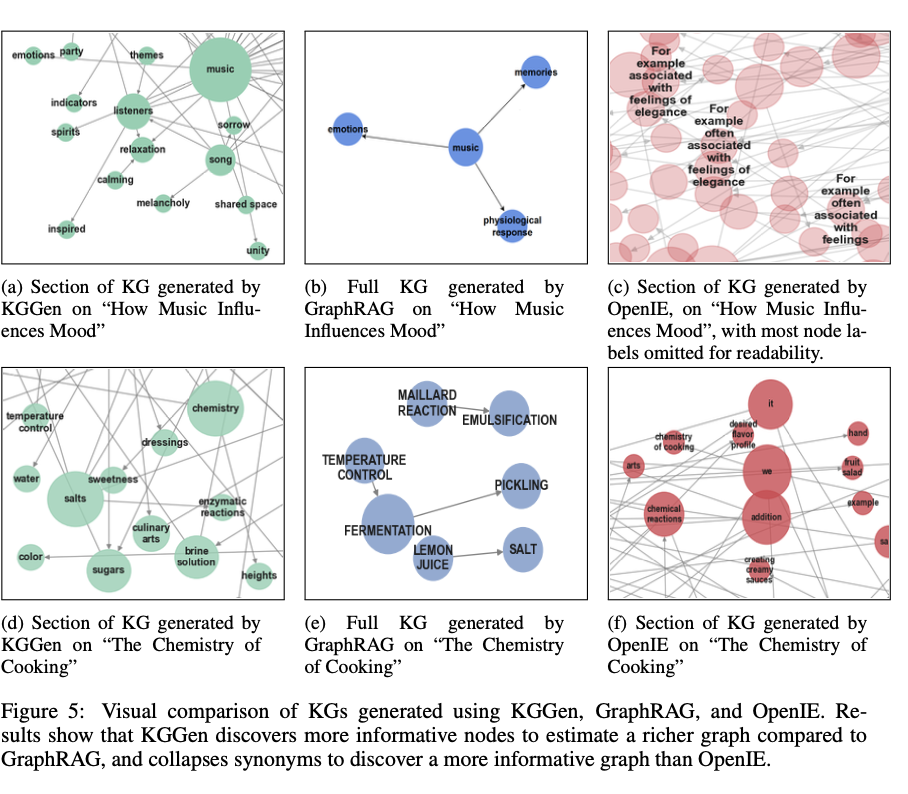
KGGEN is a way of success in the Graphic Graph of Information because IT PAIRS LANGUAGE ROCTURE ASSIGNMENT ASSESSMENT ASSESSMENT TERMS OF ITERACT CLASTERING CLASTERING CLASTER. By getting the most advanced accuracy from a mine boundar, it raises a random text bar for the impact presentations. This is successful than the longest access to artificial information, consultation activities, and learning based on learning, thus producing how to improve graphs for information graphs. The development of the future will focus on improving the integration strategies and exposing the bench tests to cover large information.
Survey the paper. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 75k + ml subreddit.
🚨 Recommended Recommended Research for Nexus
Aswin AK is a consultant in MarktechPost. He pursues his two titles in the Indian Institute of Technology, Kharagpur. You are interested in scientific scientific and machine reading, which brings a strong educational background and experiences to resolve the actual background development challenges.




 -Training written by LLMs for any AI agent")