Singapore University of Technology and Design (SUTD) Checks the development and challenges in multimorder thinking AI models for puzzle and algorithmic problems
 Checks the development and challenges in multimorder thinking AI models for puzzle and algorithmic problems")
After the success of large languages (LLMS), the current study exceeds the text based on multimodal consultation activities. These activities include a vision and language, which is important to normal artificial articulation (AGI). Symptoms of the Qunchmarks such as Puzzlevqa and Algoupuzzlevzqqa Exploring AI Calculative for Impact and AlgorithMic consultation. Even after development, llms are fought against multimorder thinking, especially the recognition of the pattern and solving local problems. The highest cost of competition includes these challenges.
Previous study depends on symbolic benchmarks such as Arc-Agi and the visual assessment such as the ongoing matriculation of Raven. However, this does not pay the ability to AI the ability to process multimoral input. Recently, the datasets are like a puzzlevqa and Algozzleve presented to check the incomprehensible thinking and solving algorithmic problems. This sale requires models including visual, logical decreases, and formal consultation. While past models, such as GPT-4-turbo and GPT-4O, showing improvement, they are still under the mysterious display and multimodal demonstration.
Investigators from Singapore University of Technology and Design (SUTD) presented the formal assessment of Opelaa's GPTA-[n] besides[n] A series of model in resolving a multimodal puzzle. Their study assessed how thoughtful skills came from different models of the model. A study that intends to identify spaces in AWI seeing, mysterious thinking, and problem solving skills. The team compared the performance of the Models such as GPT-4-Turbo, GPT-4O, and O1 in Puzzlevqa and Algouxzzleve datasets, including visible algorithmic challenges.
The investigators run a formal assessment using two main datasets:
- PuzzLeva: Puzzlevqa focuses on the immoral view and requires models to see patterns with numbers, shapes, colors and sizes.
- I-AlgopuzzzzQA: I-algopuzzzzqa ye-algopuzzzzka iveza imisebenzi yokuxazulula inkinga ye-algorithmic edinga ukuncishiswa okunengqondo nokucabanga kwe-computational.
The test is done using selected and unlovable formats. The study used Zero-Shot Chain of thought (cot) issuing in consultation and analyzing the performance decrease when changing many options. The models are tested and under conditions when viewing visual and specific consultation was separately provided to obtain certain weaknesses.
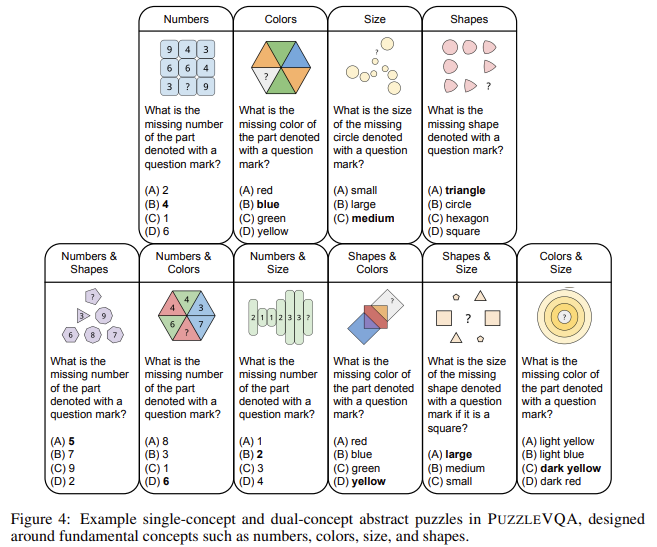
The lesson saw strong progress in the power of consultation in different model generations. GPT-4O has a better performance than GPT-4-turbo, while O1 receives a significant significance, especially in algorithmic consultation. However, these benefits arrived the sharp increase in the cost of integration. Without complete development, AI models are still meeting jobs that require direct interpretation, such as seeing the absence or to specify unusual patterns. While O1 was done well for numerical reasons, it was difficult to lift the puzzle based on the screen. The difference between a lot of selection and opening activities revealed a solid response to answers. Also, the Perction remains a major challenge for all models, with the accuracy that promotes clear clear information.
With a quick repetition, the work can summarize a few detailed points:
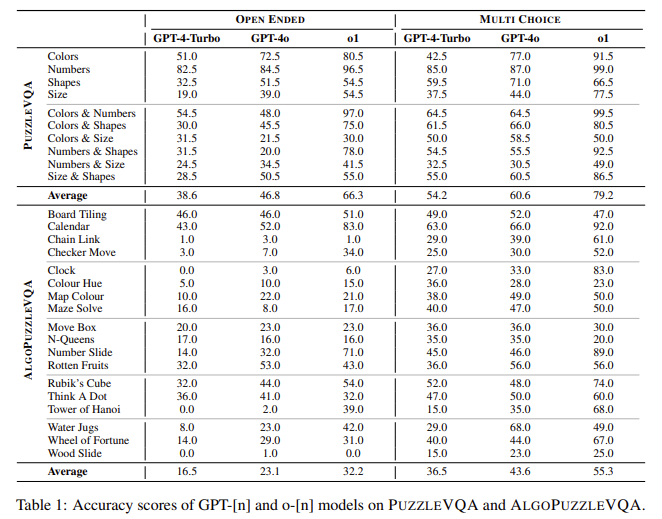
- The lesson recognized the higher habit in consultation skills from GPT-4-Turbo on GPT-4O and O1. While GPT-4O shows moderate benefits, the O1 transformation has led to significant development but came to the 750x cost of Computational costs compared to GPT-4O.
- On the other side of the Puzzlevqa, O1 received between 79.2% accurate in many selection settings, exceeding 60.6% and GPT-4-turbo's 54.2%. However, in opening activities, all models have shown operations, 66.3% points, GPT-4O in 46.8%, and GPT-Turbo on 38.6%.
- In Algouzzzqzqqqqqa, O1 very better than previous models, especially the puzzles need numerical and spotial reduction. O1 has received 55.3% points, compared to 43.6% and 43.6% and GPT-Turbo's 36.5% in selected selection activities. However, its accuracy is reduced by 23.1% in opening activities.
- The research has identified the view as the main limit for all models. To enter information clear information developed the accuracy of 22% -30%, which indicates relying on external understanding objectives. The amazing consult guide also strengthened working at 6% -19%, especially the recognition of numbers and location pattern.
- The O1 is exposed in mathematical lines but is struggled with fluctuations based on a mutelation, showing 4.5% compared to GPT-4O in recognition services. Also, do well to resolve formal problems but faced challenges in open conditions that require independent reduction.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 Record Open-Source Ai Platform: 'Interstagent open source system with many sources to test the difficult program' (Updated)
Sana Hassan, a contact in MarktechPost with a student of the Dual-degree student in the IIit Madras, loves to use technology and ai to deal with the real challenges of the world. I'm very interested in solving practical problems, brings a new view of ai solution to AI and real solutions.
✅ [Recommended] Join Our Telegraph Channel
 Method That Reduces Doom Loops in Consulting Models")

 Open Model with 21B Functional Parameters and 256K Content")
