Priceton University investigators introduce suicide and self-SEQ: WLM efficiency in one single leserer

Large Models of Language (LINMS) such as GPT, Gemini, and Claude have used large training information and complex structures to produce high quality responses. However, doing well the combination of their telephone period is always challenging, as the growing size of the model leads to high cost of integration. Students continue to evaluate the strategies that increase efficiency while maintaining or improving model.
One way that has been widely achieved the development of the LLM development, where many models are being included to produce last exit. The mixture-of-off-agents (moa) is a famous method that includes a path that includes the answers from different llms to compile a higher quality reply. However, this method introduces basic trading between diversity and quality. While it includes various models can provide benefits, it may also lead to less temporary performance due to the submission of low-quality responses. Investigators aim to measure these items to ensure efficiency without compromising the quality of response.
The MOA Traditional Framework works with the start of the Multiple Pusar Models to produce the answers. Aggregator model and includes these answers to the last response. The operation of this method depends on the imagination that the differences between the proaser models lead to better performance. However, the thought is not turning over the degeneration of a possible quality caused by weakest models in mixing. Previous study focuses on increasing the diversity rather than repairing the quality of the model model, which results in poor performance.
A group of researchers from the introductory university, the novel of how to combine the need for multiple models by combining various effective effects. Unlike traditional MOA, which includes different llms, benefits of independent service in-model with a repetitive SAMPLING. This method ensures that only high quality responses give final outputs, to address the quality of quality quality – managed mixed configuration.
Self-MOA works by producing many answers from one active model and includes to work at the last check. Doing so eliminates the need to put low-quality models, thus improving the quality of extensive reactions. Promote advancing, researchers presented to moa-seq, the consecutive variations processing many answers with Iteratively. This allows effective integration of results even in crimes where the processal of the processes are forced. Self-SEQ processes use window fluid processes, to ensure that the short content problems are still able to achieve without compromising operation without compromising performance.
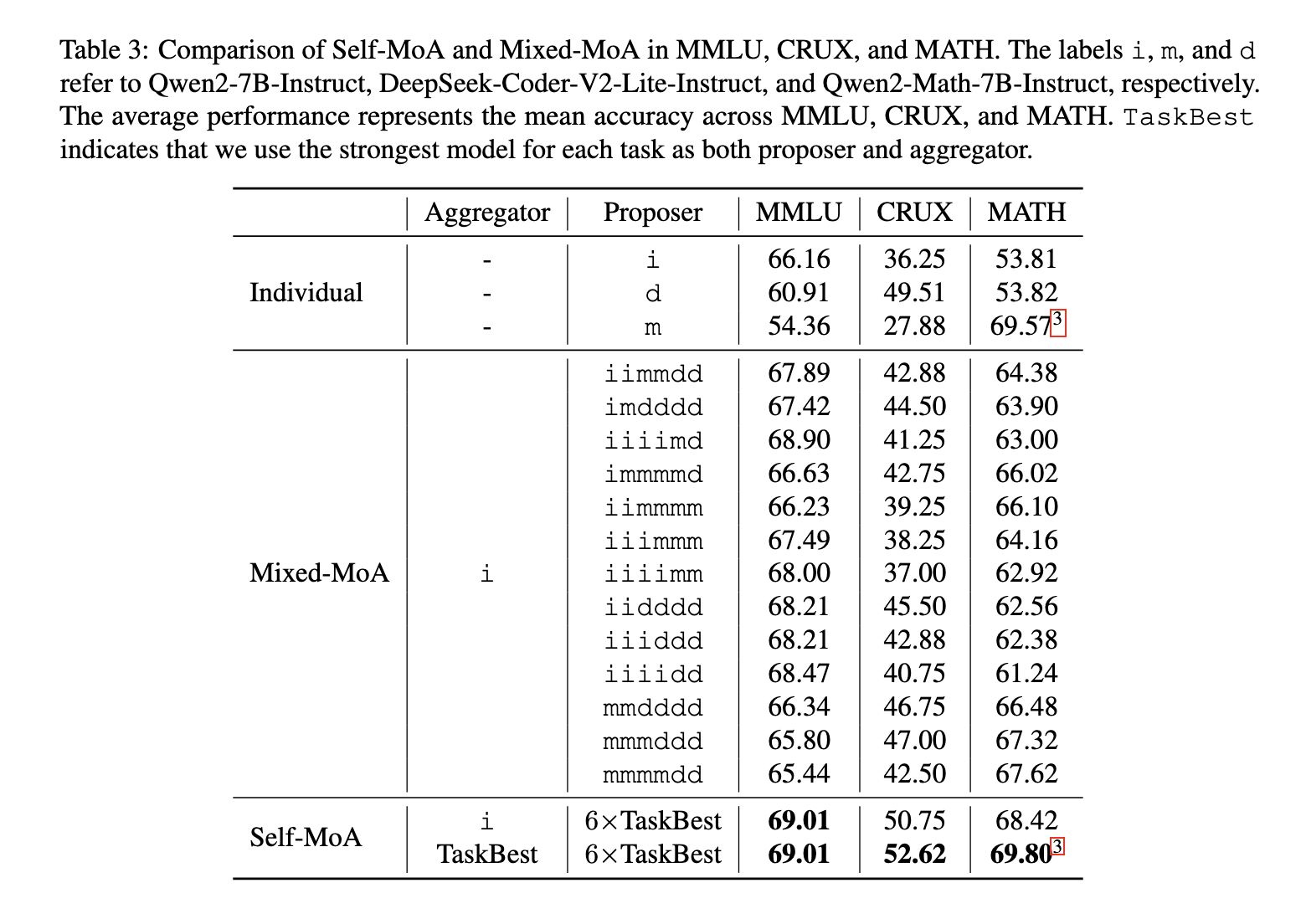
The test showed that self-control – MOA is very different mixing at all different benches. In the Alpacaeval 2.0 Benchmark, training received 6.6% of the developments over the traditional moa. When tested across many information, including MMLU, crux, and statistics, self-ma has indicated the development between 3.8% over mixed methods. When used in one of the highest quality models in Alpacaeval 2.0, training in order to set the new world new record, guaranteeing its functionality. In addition, the MOA-SEQ exercises were as a success as integrated all right out at the same time while considering the limitations set by the problems of model length.
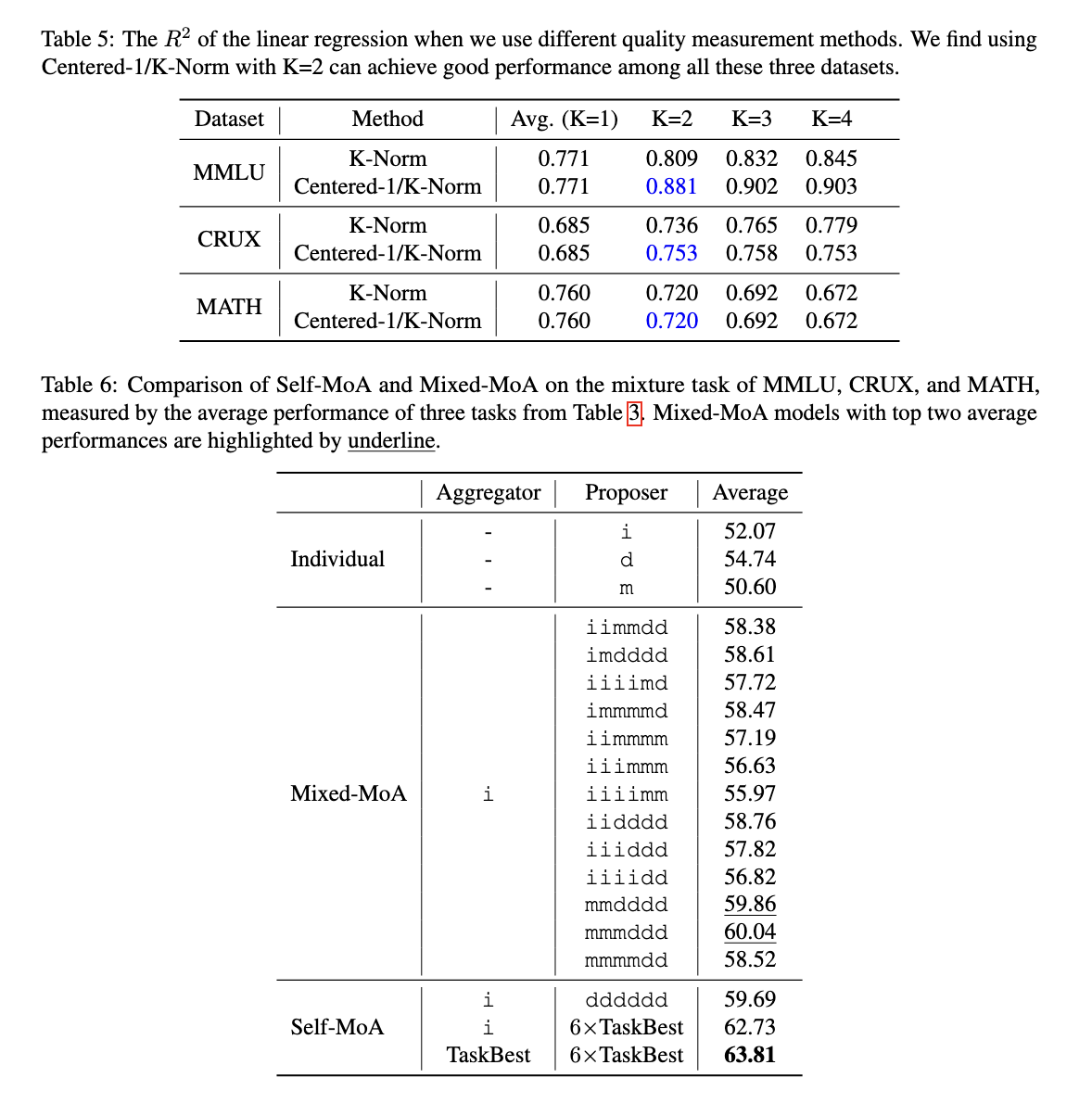
The discovery of research emphasizes the important understanding of the MAA planning arrangement is very sensitive to the quality of proposal. The results ensure that including various models are not always leading to high performance. Instead, Serial responses from one high-quality model produces better results. Investigators are held over 200 trials to analyze trading between quality and diversity, concluded that the MAA exercises differently unique to the model.
This study challenges the thinking that mixed with different llms leads to better results. By showing the height of independence, it produces a new idea by preparing for the consolidation of the LLM. The findings indicate that focus on higher higher models rather than the increased variables can improve complete performance. As the LLM study continues to appear, the MOA training provides a promising way of traditional ways, provides effective and economic development technology.
Survey the paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 Record Open-Source Ai Platform: 'Interstagent open source system with many sources to test the difficult program' (Updated)
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel
 Open Model with 21B Functional Parameters and 256K Content")


