Investigators from the University of Waterloo and CMU imported a good criticism (CFT): Novel Ai How to Improve LLM Reasoning in order to consult with formal learning
: Novel Ai How to Improve LLM Reasoning in order to consult with formal learning")
Traditional methods of training multilingual models rely heavily on good guidance, where models are learning imitating appropriate answers. While working with basic services, this option is automatically controlled to the power of a deeper skills development skills. As the appendit applications continue to appear, there is an increasing need for models that can produce answers and evaluate their results to ensure accuracy and reasonable admission.
The biggest limitations of traditional training methods is to be based on the implications and protect the models in the sensitive analysis of the answers. As a result, the most based strategies failed to present logical depths that are facing complex problems of consultation, and produced effects are often similar to appropriate responses. Most importantly, Datasut sizes do not automatically lead to the enhanced quality of the generated, negative impact trains for large models. These challenges draw attention to the meal of various methods that best improve thinking rather than grow computitions.
Existing solutions are trying to reduce these issues using the validity of the learning and ordering of the instruction. The reinforcement of the people's response has shown promising results but requires major computational resources. One way includes criticism – when models test the results by mistakes, but this is often lacking. Apart from the development, many training methods are still focused on volumes of a larger data rather than improving their basic performance, which restricts their performance in resolving problems.
The research team from the University of Waterloo, Carnegie Mellon University, and Vector institution proposed critical criticism (CFT) as a other way to guide good direction. This method changes focus on imitation based learning in depth, where the models are trained to explore and the analysis of answers rather than repeat them. To achieve this, investigators create a 50,000 critaset dataset using GPT-4O, the models that enable to identify responding errors and raise improvement. This approach works well for domains that require the planned thinking, such as solving mathematical problems.
CFT Methodes around training models use organized coltiques fixed instead of both respondents. During training, models presented for the first question and response, followed by criticism testing the accuracy of responding and logical cohesion. By increasing the model to express criticism, researchers promote a deep analysis process that develops consultation skills. Unlike traditional traditional, where the models are rewarded simply by generating the correct answers, the CFT prioritizes to cover the errors and lift improvements, leading to more expansion and descriptions.
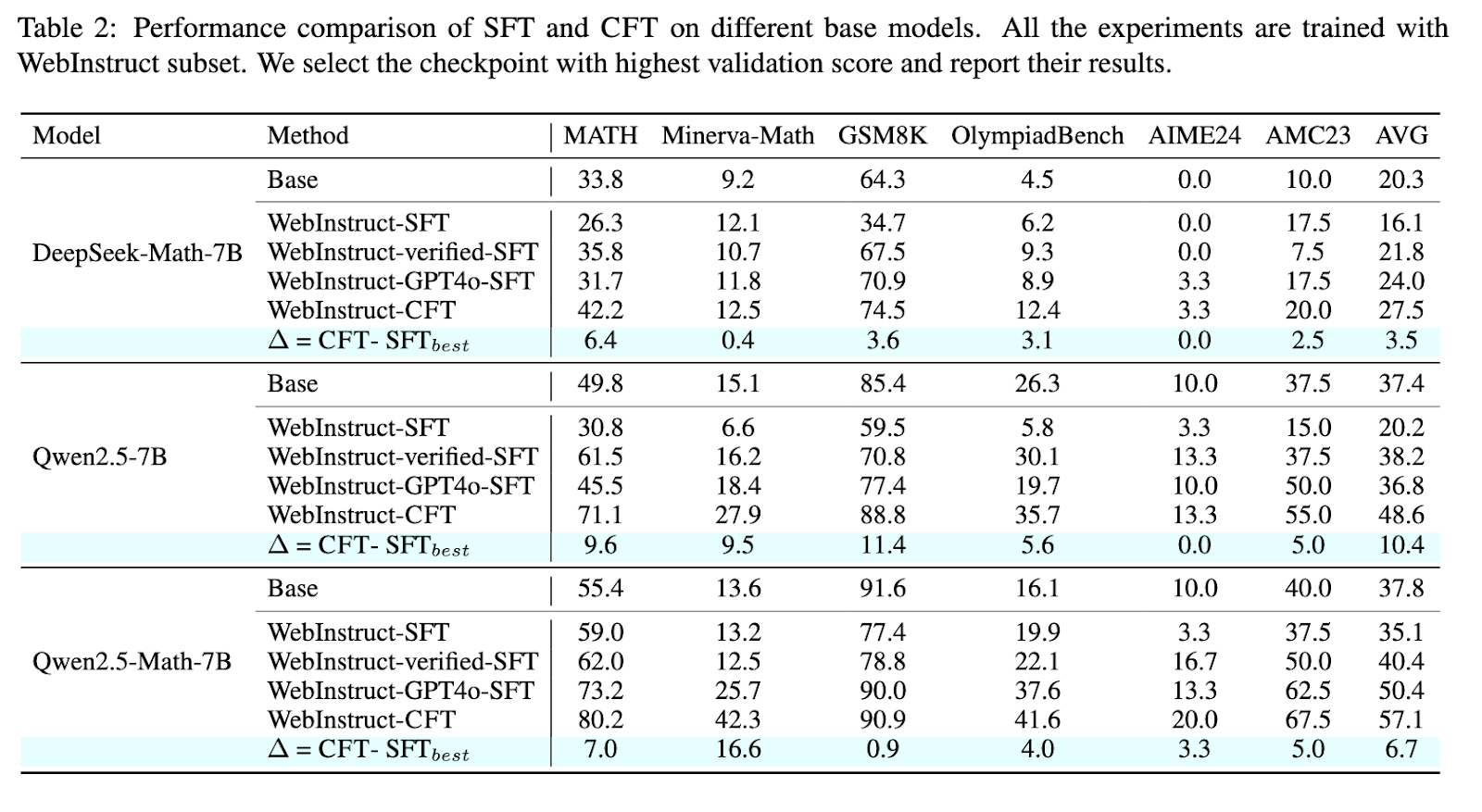
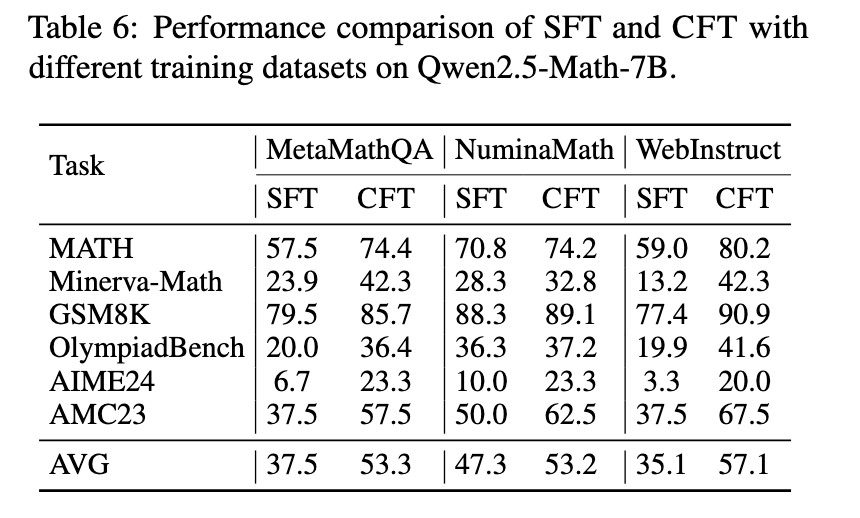
The test results indicate that cycles are changing consistently those trained using normal methods. Investigators check their way across numerical statistics, including statistics, Minersava-Math, and Olympikidbench. Models are trained to use CFT to indicate the development of 4-10% significant performance over its designated prices. Specially, qwen2.5-Math-CFT, trained for a few 50,000 examples, which are commonly higher than competitive models with more than two million training samples. In addition, the framework allowed to be improved by 7.0% in accuracy of MATH Benchmark and 16.6% at the Minva centers compared to normal conversion strategies. This important development shows the efficiency of critiquesuesuent, which often promote good results with a few training samples and computational resources.
The acquisition from this study emphasizes Bible-based learning benefits in language training languages. By changing the urge to ask for the help of criticism, researchers have brought the way that promotes model and promoting deep thinking skills. The ability to explore the most and the analysis of the answers rather than pretend to use the model management models. This study provides promising guidance to improve genetic training while reducing the cost of integration. Future work can analyze the way through other critical measures to enhance model and common trust in the other beyond different problems to solve problems.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 MarktechPost is shouting for companies / initializing / groups to cooperate with the coming magazines of AI the following 'Source Ai in production' and 'and' Agentic Ai '.
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


