
Editor's note: This article, originally published on November 15, 2023, was renewed.
Understanding the latest developments produced AI, consider in court.
The judges hear and decide on charges based on the general understanding of the Law. Sometimes the case – such as the Malpractice suit or staff dispute – requires special technology, so judges send court clerks to the Legal library, seeking charges and charges against some cases.
As a good judge, the biggest language models (llms) can answer a variety of people's questions. But delivering authorized answers – arranged in the trial of a court or the same – the model needs to be offered in that information.
Ai Court clerk is a procedure called the retrieved by the retreeval-Augmented Generagnet Generagned Generagnet, or the RAG is short.
The Way was called 'rag'
Patrick Lewis, a leading paper writer, apologizing with a growing family, which describes hundreds of papers and many commercial services that are represented by the presence of the presence of adverative ADVERATIVE AI.
Lewis said: “It would certainly think of it in the name where we did not know that our work was going to be very great,” where he shared the conference of the Database Development Conference.
“We have always organized a beautiful name, but when the time comes for paper, no one was a better idea,” says Lewis, now leading AI in Ai Start Core.
So, which of the Retrieval-Augmented Generagneted (Rag)?
The Retrieval General – Augmented Generation is a way to improve accuracy and rely on the productive AI models with information obtained in certain and appropriate resources.
In other words, it fills the gap for how to work. Under the Hood, the LLMS with neural networks, usually measured by parasites. The LLM parameters actually represent the common patterns of how people are using words to form sentences.
That deeper understanding, sometimes called high-quality information, makes LLMS useful in answering normal encouragement. However, it does not use the users who want the deep entry into some form of information.
To compute internal, external resources
Lewis and their colleagues are developed by the generation of the retrieved generation of the evelopection coordination to coordinate the Development AI services, especially the rich in the latest technical information.
The paper, with coauts from the former Facebook research (now Meta Ai), University College London, General-Purpose Recipe “because it can be used for any foreign source.
Creating a User Tram
The refund generation provides sources of models that they can receive, such as footnotes on the research paper, so users can check any claims. Who makes trust.
In addition, the process can help models remove Ambiguity to the user question. It is also reduced it may be that the model will provide a visible but incorrect answer, the item called HALLUCINATION.
Another great benefit of RAG is very easy. Lewis's Blog and three paper coauthors say developers can use a few wires of code.
That makes the way early and is more expensive than retiring model with additional dataset. And it allows users to switch to new sources on aircraft.
How people use rag
With Retrieval-Augmented Generagneted Generalization, users may have discussions with data negotiations, open new varieties of experience. This means that RAG apps can be repeatedly the number of available datasets.
For example, the producing AI model included with a medical indicator can be a major helper to the doctor or nurse. Financial commentators will benefit from an assistant linked to market data.
In fact, a business may change its technical or policy booklings, videos, or logs into resources called basic information. These sources may allow for the use of cases such as the customer or support of the field, labor training and engineering production.
Makers are why companies are involved in AWS, IBM, Golle, Google, Microsoft, Nvidi, Oracle and Pinecone accepted RAG.
Starting with a generation of receiving refunds
The Rag Nvidia Ai Provide is helping developers to connect their AIs to business information using leading technology. This reference architecture provides enhancements on limited construction basis and customized recovering pipes that bring high accuracy and use.
Blueprint can be used as is, or combined with other nvidi documents for advanced use including digital people and AI assistants. For example, the Blowprint of AI assists empowering organizations to build upgents AI who can quickly measure their customer activities with their AI and the RAG.
In addition, enhancements and IT teams can try free, Hands-on Nvidia Launchpap Lab for RA Chatbots, enabling immediate and accurate answers to business information.
All these resources are invidia and Momo Retriever, providing a leading, higher recovery and NVIlia Nim Microservices to facilitate Ai's secure, AI higher, data centers and worksheets. This is offered as part of the Nvida Ai Enterprise software platform for accelerating AI and submission.
Finding the best performance of RAG travel areas requires large memory rates and computing to move and process data. NVIDIA Gre Krace Hopper Superchip, and 288GB of its fastest memory and 8 PetaFLOPS, ready – can move 150x schedule over using CPU.
When companies become familiar with the RAG, they can include the various types of off-the-shelf or custom for customized internal or external information to create a list of assistant assistants and customers.
RAG does not require a data center. The LLMS removes Windows PCs, due to the NVIrier software that gives all kinds of applicants to access their laptops.
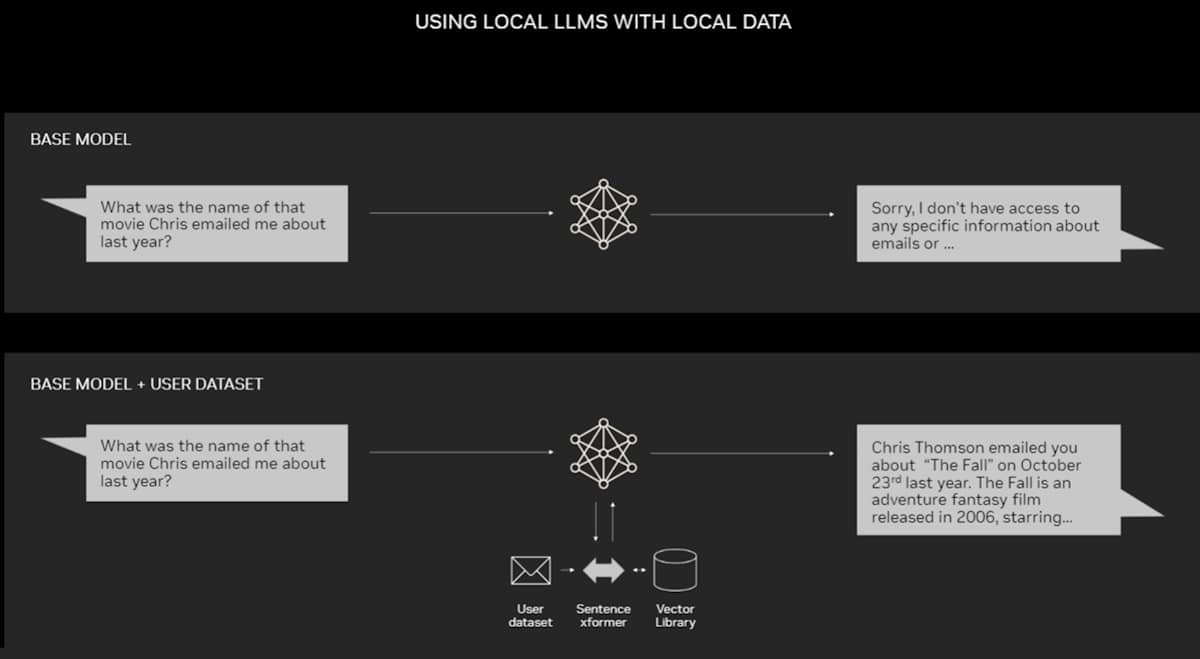
PCs equipped with nvidia RTX GPUS can now run certain AI models in the area. Using the RAG on the PC, users can connect to the secret source of information – whether they are email, notes or articles – to improve the answers. The user can still feel confident that their data source, encouragement and response is always confidential and protected.
The latest blog offers the rag model that is accelerated by Tensert-LLM through windows to find better results immediately.
RAG History
The system's roots have returned at least in the early 1970s. This is when researchers found that they are called what it costs to answer questions, NLP) to access text, starting the tiny articles such as baseball.
The concepts after this type of text mines have always been lasting years. But the driving machine engines are very growing, increasing their usefulness and preference.
In the mid-1990s, Ask Jeeves service, now asks – a popular question responds with its well-dressed valet. IBM's Watson was a celebrity of TV in 2011 when they hit two people in the Jeopardy! Game show.
Today, the LLMs take plans to respond to the whole new level.
Understanding from London Lab
Seminal 2020 arrived as Lewis Leave a doctor at NLP at the University College London and worked for Meta in London Ai Lab. The group was looking for ways to pack additional information in the LLM pangal and use the benchm sign developed to measure its progress.
Build in previous ways and inspired by paper from Google investigators, group “had a professional vision of the Return Reference program, so it can produce any text you want,” Remembrated by Lewis.

When Lewis connected to work continued to continue with a promising program from one meta group, the first results were suddenly impressed.
“I showed my boss and said, 'Who, take victories. This type of thing is not many times,' because the workouts can be difficult to set the first time,” he said.
Lewis also includes major donations from team members Ethan Perez and Douwe Kiele, and New York University and Facebook Ai Chevecheration, respectively.
When finished, the work, who ran with Nvidia GPU's piece, showed a way of doing authorized and honest AI models. Since hundreds of papers increases and expand concepts on what continue to be a valid research environment.
Retrieval-Augmented generation works
At high level, here is the generation of the retrieved generation.
When users ask for a question llm, AI model sends a question to another model that converts the number format to read it. The type of question number is sometimes called embrying or vector.
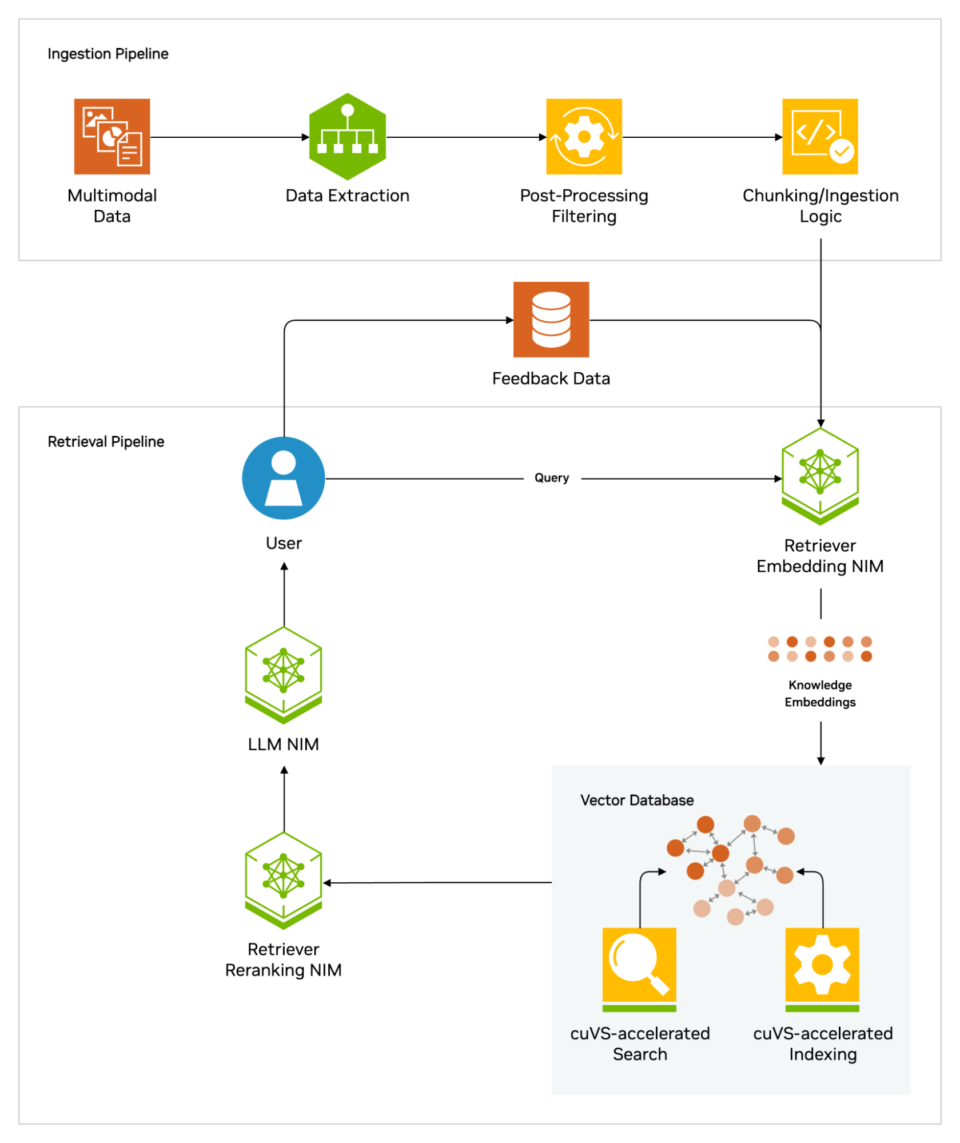
The embodding model made comparisons in the number of numbers in the vevectors in the available domain vevectors. When it gets many sports or games, returns related information, changing you with people-readable words and passs back to the LLM.
Finally, the LLM includes restored words and reaction to the query to the last response to produce a user, possible sources found.
Keeping current sources
After, continuous monitoring model creates machine and renewed electronic indices, sometimes called vector databases, of the foundations of new and renewal information as available.
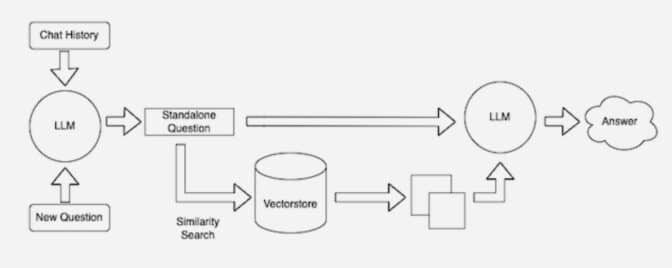
Many developers found Langchain, open library, especially help in catching together llms, embedding information models. Invidia uses Langchain in the construction of its accounting reference.
The Langchain community provides its significance of the RAG process.
The future of Generative AI lies in Agentic AI – where the llms and basic information of information are hard to create independent helpers. These agents are conducted by AI can improve decisions, to comply with complex functions and bring approved authority, certified by users.



