Deepseek-V3 Define 1: Higher Attachment of Head | by Shirley Li | Jan, 2025

To better understand MLA and make this article itself, we will also visit several concepts related to this section before accessing the MLA details.
Mhawa from only trawverrers
Note that MLA was developed with shaving speeds of the Autorerrive generation, so the mahle talks about this contester with decoder-only transformer.
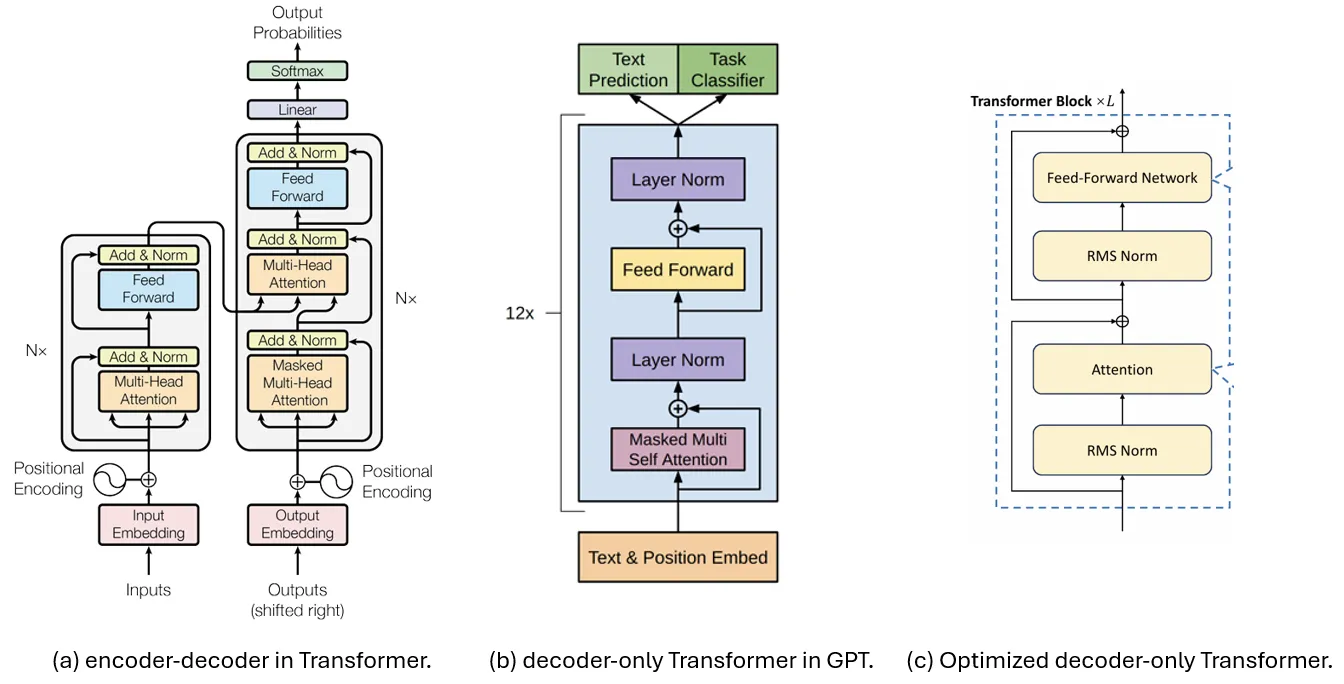
The figure below compares three transformer buildings used for reductions, where (a) are proposed Encoder and Decodes for receiving “the attention of everything you need” your paper. Part of the decoder is simpler. [6]leading to a decoder-only transformer model shown in (b), used later in multiple-generation models such as GPT [8].
Nowadays, llms are used to select the formation shown in (c) in stable training, usually used in the application where the issuance, and warnorm developed in normal RMS. This will serve as a foundation for the foundation we will discuss this article.
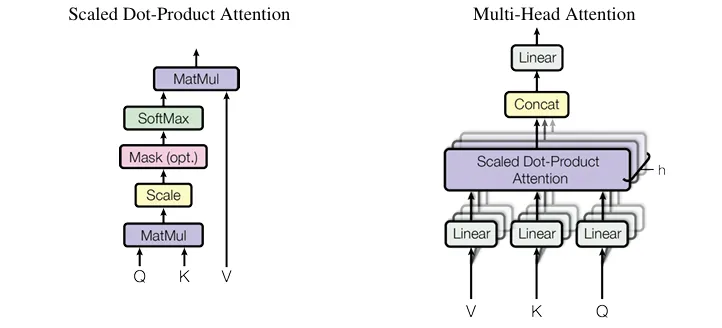
Inside this scenario, MHA calculation mainly follows the process in [6]As shown in the calculation below:
Take that we have n_h Attention to heads, and the size of the headache each is represented as d_hFor the combined size will be (h_n · d_h).
Given a model with l layers, if we mean t-th team in that layer as H_T Superiority dWe need to smoke the size of H_T from the d to (h_n · d_h) Specific map matrics are used.
Officially, we have (Equations from [3]):

where W ^ q, ^ P including W ^ v There is a direct map marker:
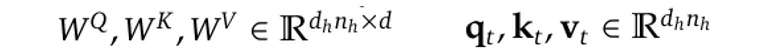
After finding such map, Q_u, k_t including v_t will be classified n_h heads to calculate the attention of a moderate product of DOT
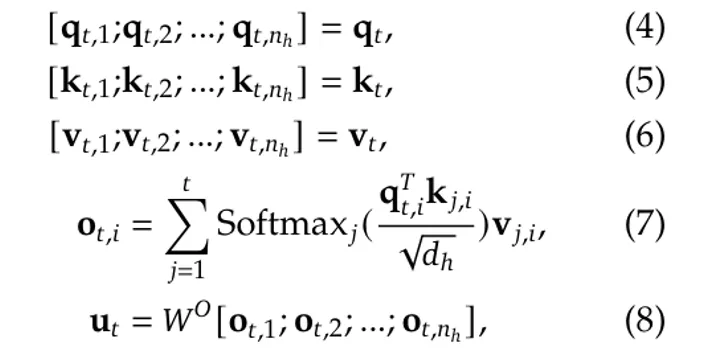
where W ^ o is another mata matrix project to map between middle range from (h_n · d_h) to d:

Note that the process described by EQN. (1) to (8) above one neighbor. During humility, we need to repeat this process in each sign produced, including many repeated calculation. This leads to a process called key-value cache.
Key Value Coverage
As is recommended by its name, key key cache is a way to speed up the efficient process of bending and using previous keys and prices, instead of reorganization at each decorative stage.
Note that KV Cache is only used during employment, as the training we need to consider the entire sequence.
KV Cace is often used as buffer in rolling. In each decorative stage, only new question q is compiled, while UK is kept in the cache will be used, so that the attention is used with the latest usage cache.
However, the speed that is found by the KV Cache comes at the cost of memory, because KV cache is usually measured with Batch size × sequences in succession × Number of headsresulted in memory floor where we have a large batch size or long order.
That leads to the fact that two strategies aim to address this limit: The attention of many questions and attention are collected.
The attention of many questions (MQA) vs to consider questions (snip
The figure below shows the comparison between the original Mhaa, dense attention (snug) [10] as well as the attention of many questions (MQA) [9].
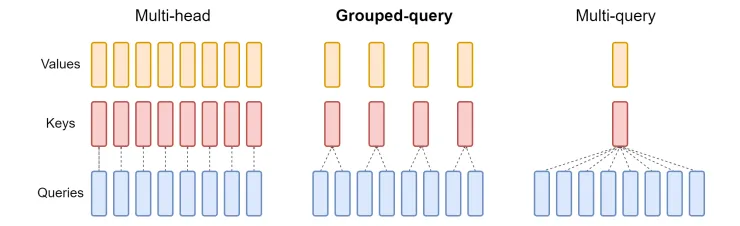
The baseline concept of MQA to share one key and one head for all the head of the question, can significantly reduce memory use but also affect the accuracy of attention.
The Gqa can be seen as a form of tying between MRHA and MQA, where certain whole heads will be allocated only by the head of the questions, not all questions. But anyway this will lead to low results in comparison with the MHA.
In the latest parts, we will see how you are in control of balance between memory and accuracy.
Cords (rotating rotation
One piece of the domain we need to call a string [11]Includes two details directly to the chair of paying the question and the key effects of creating multiple heads using SinouSoidal operations.
Directly, wires apply to a Matrix to rotate the position we rely on Question and key effects in each token, and uses wee and cosine activities because of its own but it uses it in a different way to get around.
To see what makes the position, think about the toy of the toy in 4, ie, (x_1, x_2, x_3).
To use the ropes, first we include real size:
- (x_1, x_2) -> position 1
- (x_3, x_4) -> position 2
Then, we use the rotation matrix to raise each couple:
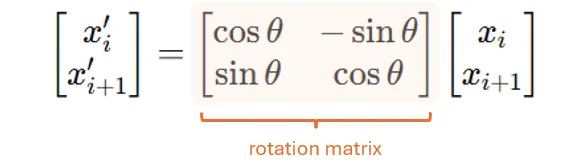
when θ = θ (P (P) = P ⋅ θ θ_0, and θ_0 a frequency of base. Example of our Toy 4-D means that (x_1, x_2) will be circulated by θ_0, and (x_4) will be changed at 2 ⋅_0.
That's why we call this rotation matrix as Responsibility Relatement: Instead of office (or individual couple), we will use a different matrix of the rotation where it is determined to rotate.
The string is widely used in today's llms because of its well-efficiency in the default failure, but as we can see from the above formula, it sounds a position in Q and K, which makes it impossible to Mla in some ways.



