
Beam Search is a powerful decorative algorithm that is widely used in natural language (NLP) and the study of the machine. It is very important for the final service of the text as the production of the text, mechanical translation, and summarizing. Beam Search Balances Between checking the search location and produces higher output. In the blog, we will go deeper in the search of Beam's search, significant importance, and implementation while assessing its real planets and challenges.
Objectives of Learning
- Understand the concept and work of the algorithm to search in Bequam at the time of writing tasks.
- Read the importance of the Beam broader and how they measure the testing and efficiency of search spaces.
- Check the actual implementation of the Beam search using Python with step guide.
- Analyze the actual apps of the world and the challenges associated with Beam search in the NLP activities.
- Find out information from BEAM's search benefits in some algorithms that are decorative as greed.
This article was published as part of Data Science Blogathon.
What is the search Beam?
Beam Search is an search algorithm that is used to disconnect from sequences similar to models, lssms, and other consecutive structures. It produces text by keeping a fixed number (“Beam Finght”) in a row possible for each step. Unlike greedy greed, which only takes the next token next, the Beam search looks at many hypotheses at the same time. This ensures that the last sequence is not careful but it is completely legal in terms that are exemplary confidence.
For example, in the movement of the machine, there may be many aligns of sentence translation. The Beam search allows the model to inspect these opportunities by keeping track of multiple preferred translation at the same time.
How do Bemch work at work?
Bemem Search works with a graph test where nodes represent the tokens and the subhead representing opportunities to convert from another pamphr. Each step:
- Algorithm selects very high quality quality tokens based on modences for issuing models (possible distribution).
- It raises these tokens to simplify the order, including their cold chances, and keeps the highest sequence of the next step.
- This process is continuous until the state of standing together together, such as accessing the special END token – of-sequence or the specified length.
Beam Width's concept
The “Beam Found” determines how many sequences are kept in each step. The thick beaf width allows to view additional sequence but increases computational costs. On the other hand, the small width of the Beam is faster but risky suits better because of limited testing.
Why is Beam's searching important in the test?
The Beam Search is important for a number of reasons:
- Improved sequential quality: By examining many hypotheses, the Beam search guarantees that the production of the world is right rather than encrypted in a beautiful place.
- Managing mysterious conditions: Many NLP tasks are involved in ambiguities, such as valid versions or many explanations. Search Beam helps to explore these opportunities and select the best.
- Working well: Compared with complete search, Beam's search is effective while checking the important part of the search space.
- Flexibility: The Beam search can be changed with various functions and sampling techniques, making it a variable in order in the order.
Practical initialization of the Beam Search
Below is an effective example of Beam search. Algorithm forms a search tree, examining active scores, and selects the best sequence:
Step 1: Enter and submit dependence
# Install transformers and graphviz
!sudo apt-get install graphviz graphviz-dev
!pip install transformers pygraphviz
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
from tqdm import tqdm
import matplotlib.colors as mcolorsSystem Instructions: Installing the required libraries for the generation of the graph (Graphviz) and Python packages (transformers and pygraphviz.
Library libraries:
- Refers: Loading GPT-2 of generation's fullness.
- Torch: By managing the uprising and jogging running in the model.
- Matplotlib.pyplot: Organizing the Beam Search Graph.
- Networkx: Building and managing graphs such as a tree representing Beam search methods.
- Tqdm: Displaying progress bar while processing graph.
- NUMP AND MATPLOTLIB.CICORS: Working with numerical details and colored mappings in seeing.
Which is output:
Step 2: Model and Tokenzer Setup
# Load model and tokenizer
device="cuda" if torch.cuda.is_available() else 'cpu'
model = GPT2LMHeadModel.from_pretrained('gpt2').to(device)
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model.eval()- It finds whether the GPU (Cuda) is available, as it can speed up COMFLATIONS. Default in CPU if no gpus is available.
- Loading a model of GPT-2 language trained before and its Tokenzer from the face transformers's library.
- It moves the model to the correct device (Cuda or CPU).
- It puts the model in the test mode with Model.eval () to disable features such as dropout, which are only required during training.
Which is output:
Step 3: Includes Input text
# Input text
text = "I have a dream"
input_ids = tokenizer.encode(text, return_tensors="pt").to(device)- Describe the installation text “I have a dream”.
- Enter the text to the ID ID using Tokenzer, returning TENSOR (Return_TENSS = 'PT').
- It motivates the installation of the installation device (Cuda or CPU).
Step 4: Describe Humility: The Opportunity of Log
def get_log_prob(logits, token_id):
probabilities = torch.nn.functional.softmax(logits, dim=-1)
log_probabilities = torch.log(probabilities)
return log_probabilities[token_id].item()- Softmax work applies to convert logits to chances (seminar coverage).
- It takes the natural logarithm of these skills to find opportunities to get the log.
- Returns Log opportunities related to a given token.
Step 5: Describe the repeat search for Beam
Tool to repeat the logging tool for searching the text generator using the GPT-2 model.
def beam_search(input_ids, node, bar, length, beams, temperature=1.0):
if length == 0:
return
outputs = model(input_ids)
predictions = outputs.logits
# Get logits for the next token
logits = predictions[0, -1, :]
top_token_ids = torch.topk(logits, beams).indices
for j, token_id in enumerate(top_token_ids):
bar.update(1)
# Compute the score of the predicted token
token_score = get_log_prob(logits, token_id)
cumulative_score = graph.nodes[node]['cumscore'] + token_score
# Add the predicted token to the list of input ids
new_input_ids = torch.cat([input_ids, token_id.unsqueeze(0).unsqueeze(0)], dim=-1)
# Add node and edge to graph
token = tokenizer.decode(token_id, skip_special_tokens=True)
current_node = list(graph.successors(node))[j]
graph.nodes[current_node]['tokenscore'] = np.exp(token_score) * 100
graph.nodes[current_node]['cumscore'] = cumulative_score
graph.nodes[current_node]['sequencescore'] = cumulative_score / len(new_input_ids.squeeze())
graph.nodes[current_node]['token'] = token + f"_{length}_{j}"
# Recursive call
beam_search(new_input_ids, current_node, bar, length - 1, beams, temperature)- Basic Case: Sets repetition where length comes to 0 (no speculative tokens).
- Forecast Model: It passes the inputs_id with GPT-2 to find the following Token logs.
- The top beams: It chooses the strikes that are possible tokens using toll.TOPK ().
- Token Showing: Assessment tokens to determine the best order.
- Expand the Input: Enter the selected loneliness to install_It goes to extra exam.
- Reviving graph: Tracks make up increasing by extending a search tree in new tokens.
- Repeating call: It also is a process of each beam (the Beams branches).
Step 6: Return to the best sequence
It finds the best sequence of the beam of the beam from the joint schools.
def get_best_sequence(G):
# Find all leaf nodes
leaf_nodes = [node for node in G.nodes if G.out_degree(node) == 0]
# Find the best leaf node based on sequence score
max_score_node = max(leaf_nodes, key=lambda n: G.nodes[n]['sequencescore'])
max_score = G.nodes[max_score_node]['sequencescore']
# Retrieve the path from root to this node
path = nx.shortest_path(G, source=0, target=max_score_node)
# Construct the sequence
sequence = "".join([G.nodes[node]['token'].split('_')[0] for node in path])
return sequence, max_score- Identify all leaves leaves (nodes without outgoing edges).
- Finds the best leaf area (highest sequence).
- Returns the way from the root area (start) to the best place.
- Released and joined the tokens in this way to make the final sequence.
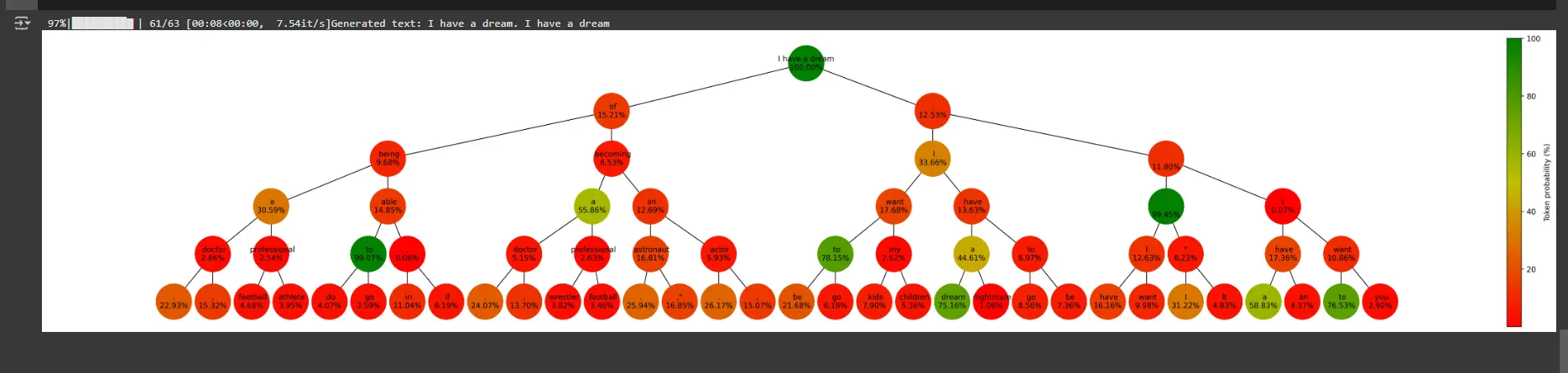
Step 7: Plan the Beam SearchGraph
It sees a tree search graphs – like a tree.
def plot_graph(graph, length, beams, score):
fig, ax = plt.subplots(figsize=(3 + 1.2 * beams**length, max(5, 2 + length)), dpi=300, facecolor="white")
# Create positions for each node
pos = nx.nx_agraph.graphviz_layout(graph, prog="dot")
# Normalize the colors along the range of token scores
scores = [data['tokenscore'] for _, data in graph.nodes(data=True) if data['token'] is not None]
vmin, vmax = min(scores), max(scores)
norm = mcolors.Normalize(vmin=vmin, vmax=vmax)
cmap = LinearSegmentedColormap.from_list('rg', ["r", "y", "g"], N=256)
# Draw the nodes
nx.draw_networkx_nodes(graph, pos, node_size=2000, node_shape="o", alpha=1, linewidths=4,
node_color=scores, cmap=cmap)
# Draw the edges
nx.draw_networkx_edges(graph, pos)
# Draw the labels
labels = {node: data['token'].split('_')[0] + f"n{data['tokenscore']:.2f}%"
for node, data in graph.nodes(data=True) if data['token'] is not None}
nx.draw_networkx_labels(graph, pos, labels=labels, font_size=10)
plt.box(False)
# Add a colorbar
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, orientation='vertical', pad=0, label="Token probability (%)")
plt.show()- NONEs represent tokens are produced in each stage, colored in their opportunities.
- The edges are connecting to nodes based on the tokels to extend the sequence.
- The color bar represents a list of token opportunities
Step 8: Moral Happen
# Parameters
length = 5
beams = 2
# Create a balanced tree graph
graph = nx.balanced_tree(beams, length, create_using=nx.DiGraph())
bar = tqdm(total=len(graph.nodes))
# Initialize graph attributes
for node in graph.nodes:
graph.nodes[node]['tokenscore'] = 100
graph.nodes[node]['cumscore'] = 0
graph.nodes[node]['sequencescore'] = 0
graph.nodes[node]['token'] = text
# Perform beam search
beam_search(input_ids, 0, bar, length, beams)
# Get the best sequence
sequence, max_score = get_best_sequence(graph)
print(f"Generated text: {sequence}")
# Plot the graph
plot_graph(graph, length, beams, 'token')Meaning
Parameters:
- Length: Number of tokens to generate (tree depth).
- beams: The number of branches (beams) per step.
The implementation of the graph:
- It creates a balanced tree graph (each place with blowing children, deepening = duration).
- Starts each local attributes: (eg Tokenscore, ConmScore, Token)
- Beam Search: Starts Beam Search from the root node (0)
- The best sequence: Release the highest sequence from the graph
- Graph structure: Visualizes the search process in Beam as a tree.
Which is output:
You can enter the Colab Notebook here
Challenges in Beam Search
Despite its benefits, Beam searcher than some limitations:
- Beam size size
- Repeated sequence
- Involving to a short sequence
Despite its benefits, Beam searcher than some limitations:
- Beam Size Trading Size: Choosing the width of the appropriate punctuation is a challenge. Beam minimum size can miss the best sequence, while the size of the Beam increases the computational hardship.
- Recycling Support: Without additional problems, the Beam search can produce repeated or unrealistic sequences.
- Involving short-order: Algorithm may receive a short sequeline due to how opportunities are collected.
Store
Beam Search is a modern NLP stone and chronological order. By maintaining a balance between the assessment and operating system, it enables the highest decoration capacity to the functions of the machines in the processing of the creative machine. Despite its challenges, Beam's search is always preferred because of its variations and ability to produce reasonable and purposeful results.
Understanding and using the Beam search to equip you with a powerful tool to improve your NLP models and apps. Whether you work language models, Chatboots, or translation systems, performing the Beam Search will enable the performance of your solutions.
Healed Key
- Beam Search is an algorithm to decorate that Balance Exclances Effession and Qualig
- The selection of the BEAM range is important; The thick beaf width improves quality but increasing the computational costs.
- Variations such as various Beam Search allows for specific performance for specific charges.
- Integrating the Beam Search for the SAMPLING strategies improves its flexibility and operation.
- Despite challenges such as a short chronology, Bemem Search lives in the NLP stone.
Frequently Asked Questions
A. Bemem Search keeps the sequence of receivables in each step, while the greed is only chooses token. This makes the search Bet Fitness and accuracy.
A. Beam Rifestation Right depends on that function and the computational resources. Beam Snow Width Quickly But It Is At the Risk of Better Loss, When Great Beam Width Checks a lot of opportunities for speed cost.
A. Yes, Beam Search is especially effective in tasks with many valid output, such as the interpretation of the machine. Checking many hypotheses and selects one possible one.
Ua. Bem Search can produce repeated sequence, allowing a short exit, and requires a careful planning of parameters such as Beam.
The media shown in this article is no Analytics Vidhya owner and used in the authorship.
![]()
I am NEHA Dewivei, Pata Science for lovers of lovers, graduates from the Mit World Peace University, Pune. I have love with data science and rising styles of it. I am happy to share understanding and learn from this community!



