Meta Ai introduces MR.Q: Reprofed algorithm of model with model with model-based protrification for Generation

Learning Strengthening (RL) agents that train agents to make consecutive decisions by increasing integrated rewards. It contains a variety of requests, including robotic, gaming, and automation, where agents are in contact with places to learn appropriate conditions. RL traditional ways fall into two stages: Model-free methods and Modence. The free model strategies advance the simplest but require broader internet data, while supporting models are presenting formal learning but they want to be more demanding. The growing study area aims to close these methods and improve some of the most effective RL structures that apply well to all domains.
The persistent challenge in RL absence of universal algorithm can do consistently in many places without parameter parameter tuning parameter tuning. Most of the RL algorithms are RL algorithms designed for specific programs, which need to be adjusted to effectively apply to new settings. RL-based RL methods often indicate high production but at the cost of serious difficulties and slight slaughter. On the other hand, models of models are simple to use but often in weakness when used in unknown activities. Improving a framework of RL that includes the skills of both methods without compromising the deception remains a significant research goal.
Several RL methods appeared, each containing traders-offs between work and efficiency. The solution based solutions such as Douksving3 and TD-MPC2 have been detected by the major effects on different activities but are highly dependent on complex planning plans and greater energy. Other free techniques, including TD3 and PPO, Preference for computational requirements but requires domain planning. This pollution emphasizes the need for RL algorithm that includes adaptation and efficiency, which enables the use of seams to all the various activities and places.
The research team from Meta Fair delegates Mr.q, model-free RL algorithm including model to improve learning and common performance. Unlike traditional model model methods, MR.Q puts the Premitation reading phase inspired by model, making algorithm work properly in all different RL benches. This approach allows Mr.
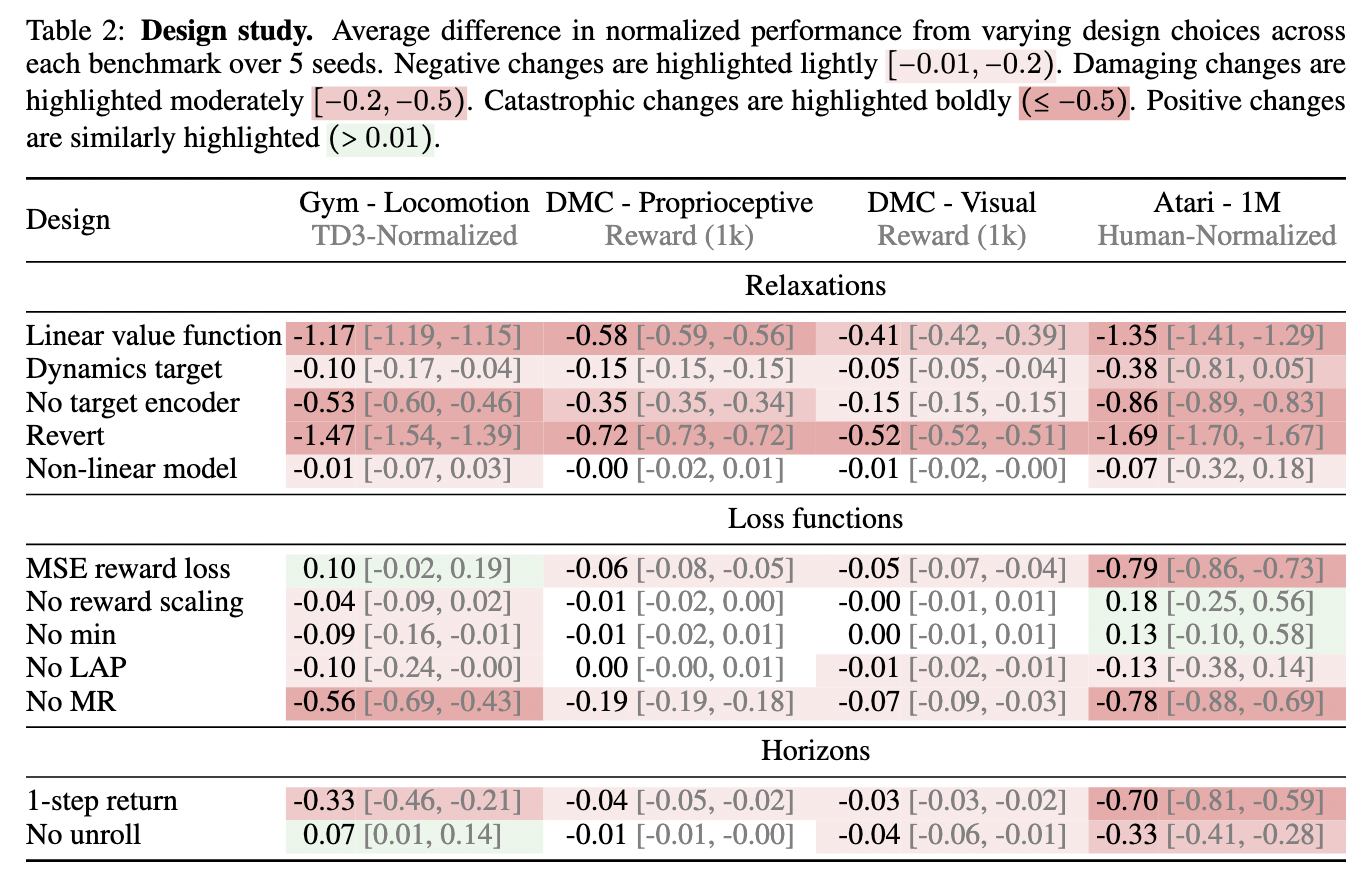
Mr.q Framework spaces two two lungs to enter the protest that maintains various relationships and value work. This embedded and processed by a limited line of accordance in different locations. The program includes the Encomer issuing the appropriate features from state-of-state installation and performing, developing learning stability. In addition, Mr.q Uses a priorit system and a rehabilitation process to improve training performance. Algorithm reaches solid functionality to all many RL benches while maintaining computer efficiency by focusing on a fixed learning plan.
Four RL Benchmarks-Gym Locomotional services, Deepmind Control Suite, as well as atari-show that Mr.q reaches strong results with one collection of hyperparemeter. Algorithm Acpenducforms ordinary common bases such as PPO and DQN while they keep working compared to Dooudrver3 NetD-MPC2. MR.Q achieves competitive results while using the most computer resources, which makes it a valid decision of the actual land applications. At Atari Benchmark, Mr.q is especially doing in the spaces of the discrete's actions, which exceeds existing methods. Mr.q shows strong performance in the ongoing control facilities, the model bases with no model and dqn while storing competition results compared to Douperv3 NetD-MPC2. Algorithm reaches the best development of good workouts in all benches without requiring a broadenance of various functions. The assessment highlights Mr.q's ability to reduce successfully without needing a broader innovation of new services.
Studies emphasize the benefits of filing the model based on algorithms without RL algoriths. Mr.q is putting action to get the construction of the RL framework more variables by improving efficiency and flexibility. Future advancement can compromise its approach to deal with challenges such as hard testing problems and non-Markovian areas. The findings can contribute to the broad vaccine of the RLs more accessible and successful in many applications, Mr.q position as the promising tool for researchers and the claimants who want RL.
Survey the paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 70k + ml subreddit.
🚨 Meet the Work: an open source opened with multiple sources to check the difficult program AI (Updated)
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


