Kimi k1.5: A Next-Generation Multi-Modal LLM with Reinforcement Learning in AI Development with Scalable Multimodal Reasoning and Benchmark Excellence

Reinforcement learning (RL) fundamentally changed AI by allowing models to iteratively improve performance through interaction and feedback. When applied to large-scale linguistic models (LLMs), RL opens up new ways to handle tasks that require complex reasoning, such as solving mathematical problems, coding, and interpreting multimodal data. Traditional methods rely heavily on pre-training with large static datasets. However, their limitations have become apparent as the models solve problems that require dynamic evaluation and dynamic decision making.
The biggest challenge in the development of LLMs is in increasing their skills while ensuring computer efficiency. Based on static data sets, conventional training methods struggle to meet the demands of complex tasks involving complex reasoning. Also, the existing implementation of LLM RL has failed to deliver modern results due to inefficiencies in rapid design, policy development, and data management. This shortcoming has left a gap in the development of models that can perform well across various benchmarks, especially those that need to think simultaneously about text and visual input. Solving this problem requires a comprehensive framework that aligns model development with task-specific needs while maintaining token efficiency.
Previous solutions for developing LLMs include well-supervised configuration and advanced thinking methods such as chain-of-thought (CoT) information. CoT thinking allows modelers to break down problems into intermediate steps, improving their ability to tackle complex questions. However, this approach is computationally expensive and often constrained by the limited window size of the LLM context. Similarly, Monte Carlo tree search, a popular method for optimizing inference, introduces computational overhead and complexity. The absence of unregulated RL frameworks for LLMs has limited progress, emphasizing the need for a new approach that measures performance improvement and efficiency.
Researchers from the Kimi Team presented For me k1.5is a next-generation multimodal LLM designed to overcome these challenges by combining RL with context-extended capabilities. This model uses new techniques such as long content scaling, which expands the context window to 128,000 tokens, enabling it to process large problem cases effectively. Unlike previous methods, Kimi k1.5 avoids relying on complex methods such as Monte Carlo tree search or value functions, opting for a simple RL framework. The research team developed a rapid RL setup set to improve the model's flexibility, incorporating a variety of inputs including STEM, coding, and general thinking tasks.
Kimi k1.5 was developed in two versions:
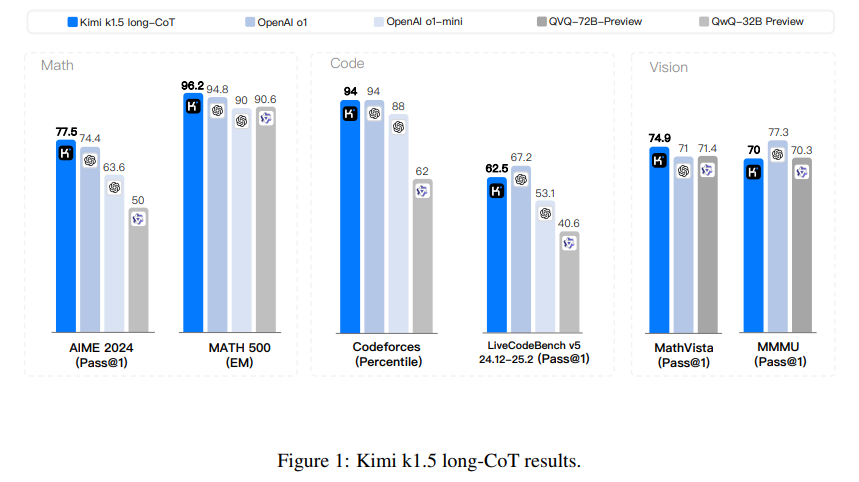
- Long CoT model: It performs very well on extended logic tasks, using its 128k total token window to achieve the best results in all benchmarks. For example, it scored 96.2% on MATH500 and the 94th percentile on Codeforces, demonstrating its ability to handle complex, multi-step problems.
- Short-CoT model: The Short-CoT model is optimized for performance using advanced long-to-short context training methods. This method successfully transferred the logic priority from the long CoT model, allowing the short CoT model to maintain high performance, 60.8% in AIME and 94.6% in MATH500, while significantly reducing token consumption.
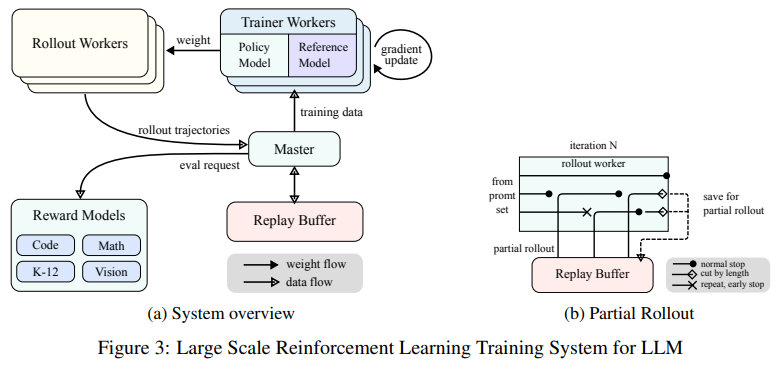
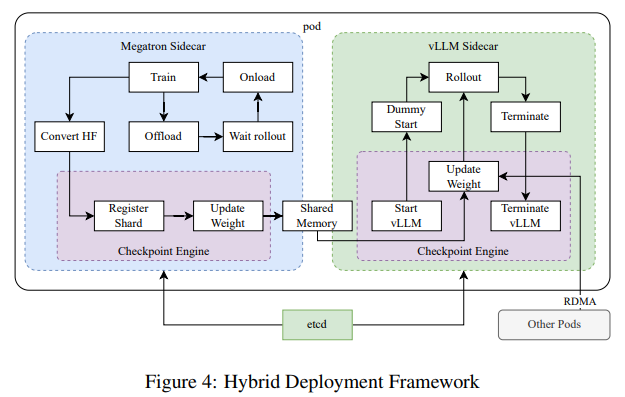
The training process combined supervised fine-tuning, long chain thinking, and RL to create a strong framework for problem solving. A key innovation included partial abstraction, a method that reuses previously calculated methods to improve computing efficiency during long content processing. Using multimodal data sources, such as real-world and synthetic virtual data datasets, further strengthened the model's ability to interpret and reason across text and images. Advanced sampling techniques, including curriculum and prioritized sampling, ensure training is focused on areas where the model has shown poor performance.
Kimi k1.5 showed a significant improvement in token efficiency by using its long-to-short context training method, which allows the transfer of cognitive priorities from long-form models to short-form models while maintaining high performance and reducing token consumption. The model achieved impressive results across multiple benchmarks, including a match accuracy of 96.2% on MATH500, 94 percent on Codeforces, and a 77.5% pass rate on AIME, high-level models such as GPT-4o and Claude. Sonnet 3.5 by large margins. Its short CoT performance outperformed GPT-4o and Claude Sonnet 3.5 in benchmarks such as AIME and LiveCodeBench by up to 550%, while its long CoT performance matched o1 in most benchmarks, including -MathVista and Codeforces. Key features include scaling long content with RL using context windows of up to 128k tokens, efficient training with partial extraction, improved policy optimization with online mirroring, improved sampling techniques, and length penalties. Also, Kimi k1.5 excels in collaborative thinking over text and vision, highlighting its multi-modal capabilities.
The study revealed several key takeaways:
- By allowing models to dynamically test with rewards, RL removes the constraints of static data sets, expanding the scope of thinking and problem solving.
- Using a total token window of 128,000 allowed the model to effectively perform off-chain reasoning, a key factor in its high-level results.
- Partial release and prioritized sampling techniques improved the training process, ensuring that resources were allocated to areas of greatest impact.
- Incorporating a variety of visual and textual data made the model successful in all benchmarks that require simultaneous consideration of multiple input types.
- The optimized RL framework used in Kimi k1.5 avoids the pitfalls of computationally intensive techniques, achieving high performance without excessive resource consumption.
In conclusion, Kimi k1.5 addresses the limitations of traditional pre-training methods and uses new techniques to measure context and token performance; research sets a new performance benchmark for all cognitive and multimodal tasks. The long-CoT and short-CoT models together demonstrate the versatility of Kimi k1.5, from handling complex, extended thinking tasks to achieving efficient token solutions for short scenarios.
Check out Paper and GitHub page. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio extends with vision models, new language models, embeddings and LoRA (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among viewers.
📄 Meet 'Height': The only standalone project management tool (Sponsored)
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


