Microsoft AI Research Introduces MVoT: A Multimodal Framework for Integrating Visual and Voice Interaction in Complex Tasks

Artificial intelligence research has seen revolutionary advances in thinking about and understanding complex tasks. The most recent developments are model large-scale languages (LLMs) and multi-model large-scale languages (MLLMs). These systems can process text and visual data, allowing them to analyze complex tasks. Unlike traditional methods that support their thinking skills in verbal ways, multimodal systems try to simulate human understanding by combining written thinking and visual thinking, therefore, they can be used effectively to solve various challenges.
The problem so far is that these models cannot link textual and visual thinking together in dynamic environments. Models developed for inference perform well on either text-based or image-based input but cannot run simultaneously on both input. Spatial reasoning tasks such as maze navigation or the interpretation of dynamic structures show weaknesses in these models. Integrated thinking capabilities cannot be accommodated within these models. Therefore, it creates limitations in transforming and interpreting models, especially when the task is to understand and manage visual patterns and instructions given in words.
Several approaches have been proposed to deal with these problems. Chain-of-thought (CoT) information develops thinking by generating a step-by-step textual sequence. It is script-based in nature and does not handle tasks that require local knowledge. Other visual input methods are external tools such as image captions or scene graph generation, which allow models to process visual and textual data. Although efficient to a certain extent, these methods rely heavily on separate visual modules, making them inflexible and error-prone for complex tasks.
Researchers from Microsoft Research, the University of Cambridge, and the Chinese Academy of Sciences introduced the Multimodal Visualization-of-Thought (MVoT) framework to address these limitations. This novel thinking paradigm enables models to generate integrated and verbal thought tracks, providing an integrated approach to multi-modal thinking. MVoT embeds the power of visual reasoning directly into the modeling, thus removing the dependency on external tools and making it a more integrated solution for complex reasoning tasks.

Using Chameleon-7B, an automated MLLM fine-tuned for multi-inference tasks, the researchers implemented MVoT. This approach involves lossy tokenization to bridge the representation gap between text and image tokenization processes to extract quality visuals. MVoT processes multimodal input step-by-step by creating verbal and visual thought tracks. For example, in spatial tasks such as maze navigation, the model generates visual cues that complement the cognitive steps, improving both interpretation and performance. This traditional visual thinking ability, integrated into a framework, makes it more similar to human understanding, thus providing an intuitive way to understand and solve complex tasks.
MVoT outperformed state-of-the-art models in extensive tests of several spatial reasoning tasks, including the MAZE, MINI BEHAVIOR, and FROZEN LAKE. The framework achieved a high accuracy of 92.95% in maze navigation tasks, which outperforms the standard CoT methods. In the MINI BEHAVIOR task that requires understanding interactions with local structures, MVoT achieved an accuracy of 95.14%, demonstrating its performance in dynamic environments. In the FROZEN LAKE project, which is well-known for its complexity due to the fine spatial details, the robustness of MVoT reached an accuracy of 85.60%, surpassing CoT and other benchmarks. MVoT consistently improved in challenging situations, especially those involving complex visual patterns and spatial reasoning.
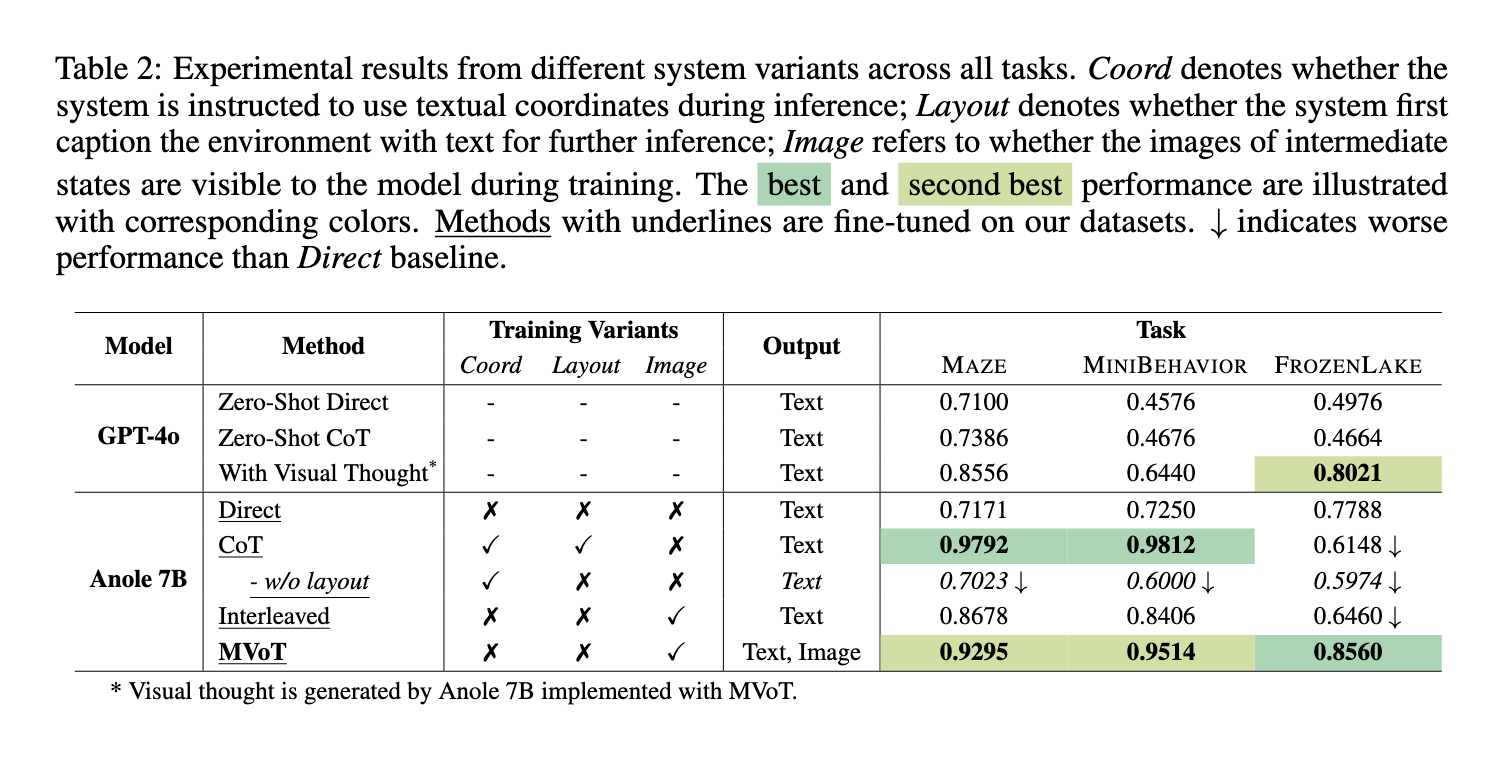
In addition to performance metrics, MVoT has demonstrated improved interpretation by producing visual thought tracks that complement verbal reasoning. This capability allowed users to follow the model's thought process visually, making it easier to understand and verify its conclusions. Unlike CoT, based only on text description, MVoT's multimodal reasoning approach reduced errors caused by incorrect text representation. For example, in the FROZEN LAKE project, the MVoT has maintained a stable performance in the increased complexity of its environment, thus demonstrating robustness and reliability.

This study therefore redefines the scope of the thinking capabilities of artificial intelligence through MVoT by integrating text and vision into thinking tasks. Using token disparity loss ensures that visual reasoning is easily compatible with text processing. This will fill an important gap in current methods. Higher performance and better interpretability will mark MVoT as a landmark step towards multi-modal thinking that can open doors for complex and challenging AI systems in real-world situations.
Check out Paper. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 Recommend an Open Source Platform: Parlant is a framework that changes the way AI agents make decisions in customer-facing situations. (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing a dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is constantly researching applications in fields such as biomaterials and biomedical sciences. With a strong background in Material Science, he explores new developments and creates opportunities to contribute.
📄 Meet 'Height': Independent project management tool (Sponsored)



: I-Sparse MLP Circuit Steering Ngaphandle Kokuqeqeshwa kwe-SAE noma Ukuguqulwa Kwesisindo")