Researchers Basist and Deentauto AI suggested unemployment: A game that converts a long-to-Token's long-token detection of one GPU

In large languages of Languages (LLMS), processing an extension of an extension requires key computational and memory resources, which result in a slight estimate and higher hardware costs. How to be ignored, the main component, increases this challenge because of its quadratic difficulties related to the tall length. Also, keeping the previous context using key-value (kV) cache resulting in higher memory porthadds, scales.
The main limit of the llMS is not their ability to handle a long-term order than the Windows trained. Many models are reduced in operation when faced with extended installation due to poor memory management and monitoring of the cost. Existing solutions often rely on good planning, which is very broad and requires high quality information. Apart from the effective way of the expansion of the context, tasks such as summarizing the documentation, the generation of refund, and the Deformed Form General processing.
Several methods are proposed to deal with the problem of context. FlashTattentional2 (FA2) increases memory usage by reducing unwanted performance during the attention of attention, however does not consider the success of the meeting. Some models use selected attention, either statistical or stronger, reduce the processing. Presented by HIP care strategies is another way that attempts to load full-use tokens in Exterior memory; However, there is no effective cache treatment, which results in increased latency. Apart from these progress, there is no way successfully for all three important challenges:
- Measuring a long context
- Memory memory management
- Computer efficiency
The investigators from Kaist, along with Deepauto.ai presented IncinshipAn advanced framework emerges effective monitoring while reducing memory bottles. The model reaches this in Hierarchical Token Truning algorithm, which removes the right tokens content. This consensus structure keeps the tokens that contribute much to attention, reducing the processing more. The framework also includes the Adaptive String (Rotary Active Rotary Using the Novel KV failure. -3 in 48gb GPU, making it a very drop-up-to-infer.
The new Infinisivip establishment is its way to many stacks, which is constantly improving improves the selection of situations in all many stages. Tokens are divided into organized length fragments, and each piece is processed based on your attention. The high-quality selection method ensures that only the most sensitive tokens are stored and some are thrown. The way followed by endlessly, unlike any other models that infection, completely compliant, provide effective performance. The KV Cacea Cacea program promotes memory usage by powering important tokens valuable content during the maintenance of returning. The model also uses a number of strings for unique attention issues, thus the benefit of being smooth.
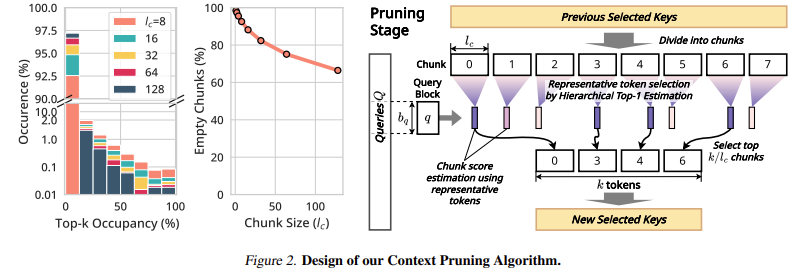
The model indicates 18.95 × speed management of the process of loading reducing the use of GPU memory up to 96%, making it available to activate major apps. In the Benchmark test like Longbench and ∞bench, the decline in the United States-of-The-the-art, getting higher 9.99 points than Infllm. Also, the drop-out of the passage increased by 3.2 × in Consumer GPUS (RTX 4090) and 7.25 × in the Enterprise-grade GPUS (L40s).
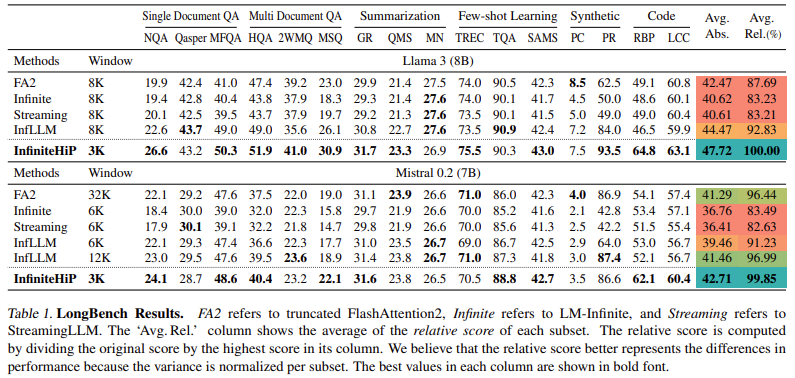
In conclusion, the research team has successfully referred to the major bottles that accompany the deviation of interruption. The framework improves the llM skills by combining Hierarchical Token, and uploading the ropes. This success enables the professional trained models to process extended sequences without losing the context or increase in the cost of integration. The way is disabled, working well, and it is effective in various AI programs that require long memory storage.
Survey Page, Source code and live demo. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 75k + ml subreddit.
🚨 Recommended for an open source of AI' (Updated)
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
✅ [Recommended] Join Our Telegraph Channel



