
Introduction
FALCON-H1 series developed by the Technology Innovation Institute (TII), notes important developments in the repentance of large languages of Language (LLMS). By combining the TRANFORMER-based attention on Mbamba-Based State Space Models (SSMS) configuration associated with Hybrid Parallel, FALCON-H1 achieves different performance, memory performance, and disability. It is released in many size (0.5B to 34B parameters and versions (basis, tuition – Parameter models are re-designated computer models and embo3.3-70b.
New Buildings
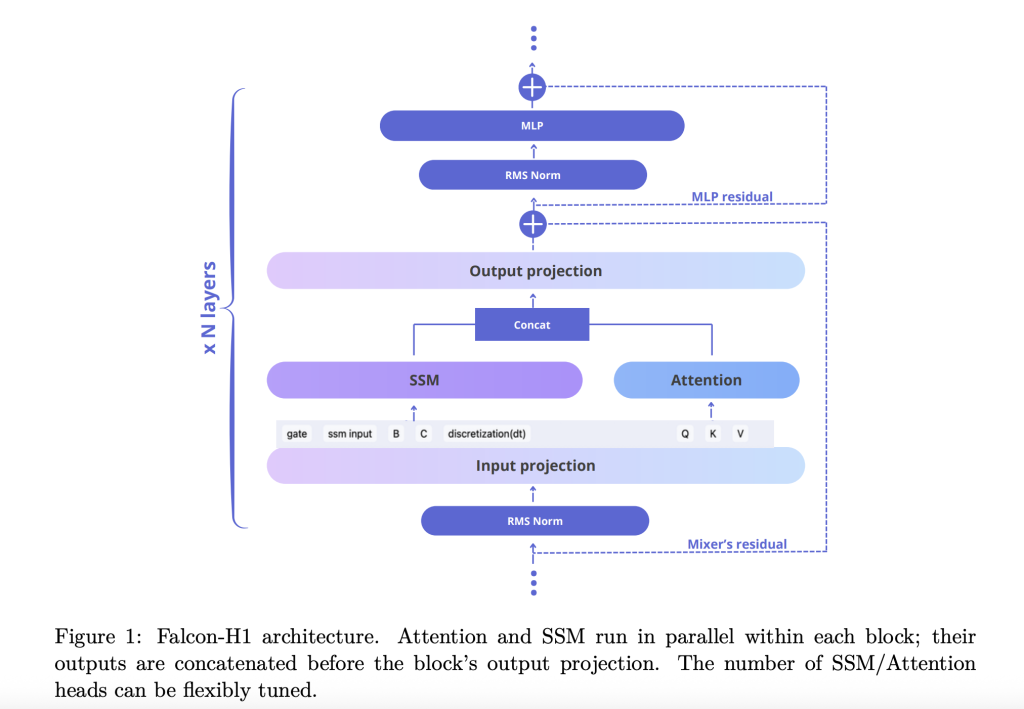
This page Technical report How to FALCON-H1 Accept the novel Construction of buildings such as parallel hybrid When the modules of attention and the SSM works once, and their results are integrated before speculation. This project removes from the order in sequence and provides converting situations to display the number of attention and SSM channels. Default Configuration Using 2: 1: 5 SSM rating, attention, and MLP channels respectively, which makes all good performance and power learning.

To continue the model analyzing, FALCON-H1 is evaluating:
- Channel allocation: Abrations indicate that growing attention stations are deteriorating, and balancing SSM and MLP produces strong benefits.
- Block the configuration: SA _ms configuration (similarity similarities and SSM meets together, followed by the MLP) doing well with the loss of training and computer efficiency.
- Frequency of the base of the rope: Usual Normal of 10 ^ 11 In the Rotary Polesimveral Meddings (rope) impaired the full advancement, promoting general training during a long-centered training.
- Deep depth in depth: Checking indicates that the deepest models are very different from the broader under scheduled parameter budgets. FALCON-H1-1.5B-DEEP (66 assignments) Slide many 3B models and 7b.
Tokenzer strategy
FALCON-H1 uses Tokozer Particed Byte Pair Cour (BPE) Tokenzer Suite with a vocabulary from 32k to 261k. The main project options include:
- Digit and punctuation: Empirury is upgrades to work on a lot of languages and settings.
- Latex Token injection: Improves exemplary accuracy for Matt Benchmarks.
- Most languages Support: 18 languages and sculptures to 100+, using prepared births to reproduce and nten metric.
Pretricaneng Corpus and data plan
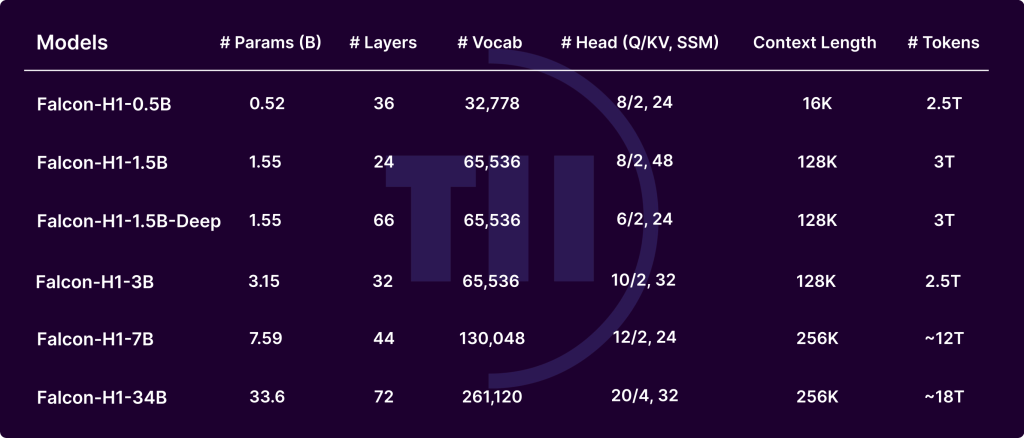
Falcon-H1 models are trained to Khelees up to 18T token Corpus carefully, including:
- Top web data (Fixowed Fineweb)
- Multilingual Datasets: Regular Crawl, Wikipedia, Arciv, Openubtitles, and selected resources in 17 languages
- Code corpus: 67 languages, surveyed with Minhash Decuplication, Codebert Quality Filters, and PII kick
- Math Datasets: Matt, GSM8K, and advanced in-house trawls
- Data for execution: Raw corpora using different llms, and Textbook-studi qqa from 30k Wikipedia
- Sequence of long conditions: Fill in the Complete-in-middle, Reddleing, and service-based consultation activities up to 256k tokens
Training Infrastructure and Way
Training used for the Maximal update is customized (μP), to support smooth clarity in all model sizes. Models use advanced strategies similar to:
- Mixer Palalistism (MP) including Parallels with context (CP): Improving Fall Coat-Certificate Demanding
- Bar: Bloata16 and 4-bit variations to facilitate power supply
Exploring and Working
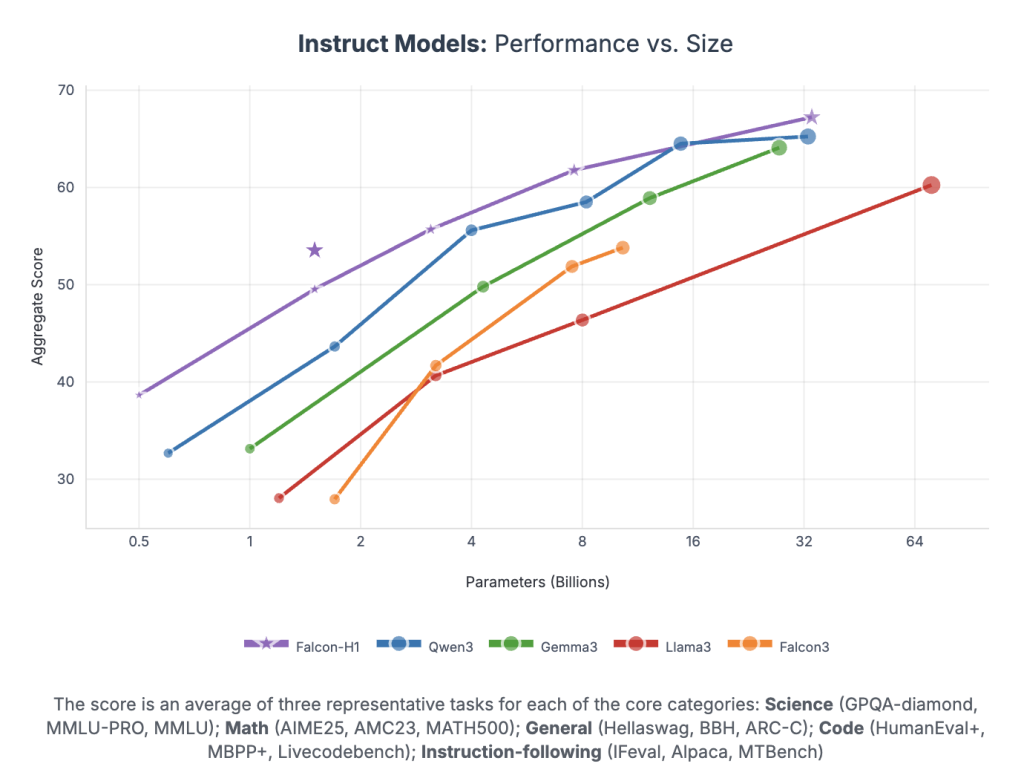
FALCON-H1 reaches unprecedented functionality:
- FALCON-H1-34B-commanding passes or accompanied with 70b-scale models such as accumulations.
- FALCON-H1-1.5B-DEEP Rivals 7B-10B rivals
- FALCON-H1-0.5B It moves 2024-ERA 7B
Benchmarks Span Mmlu, GSM8K, Humetueval, and long-term jobs. Models show strong alignment with SFT and Direct Deference Optimization (DPO).
Store
The Falcon-H1 sets a new level of llms by integrating parallel hybrid properties, the multitaculative capacity, the power of multilingual training, the capacity of the SSM strategies and memory budget, which makes it good for the other of various areas.
Look Paper and models in kissing face. Feel free View our teaching page in agent at agent and Agentic AI of different applications. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.

Michal Sutter is a Master of Science for Science in Data Science from the University of Padova. On the basis of a solid mathematical, machine-study, and data engineering, Excerels in transforming complex information from effective access.
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


