This AI paper introduces codesters: Physical models are symbolic language with code / guide

Large models of language (LLMS) fought accurate integration, images, and algorithmic activities, often require systematic systems. While language models show energy in solid understanding and common assumptions, they are not equipped naturally to manage the activities that require high-quality or logical decisions. Traditional methods try to compensate this weakness by combining foreign tools but has a systematic way of finding when they should rely on showing the written text.
Studies point to the basic limit in the largest existing language (llms): their unable to change between text consultation and performing the code effectively. This story is rising because the installation positions are not clearly noticeable that the problem is best resolved using the natural language or symbolic integration. While other models, such as Openai's GPT series, include features such as Code translators to deal with this, they fail to successfully direct the change between text and solutions based on the code. The challenge is not just for making the output code but also know when to produce the code for the first time. The llMS is often frustrated in the mind-based thinking other than this ability, resulting in poor not working and solutions to solving problems.
Some models have enclosed external entities to assist llms in production and production of the code to address this. This includes Openai translator, however, these methods fail to rotate the symbolic integration, as they are not organized in order llms and measures the code of the natural language. Existing methods provide limited situations, often require the intervening of the hands or order relevant to the background. As a result, models continue to perform lower functions in the activities that require a hybrid of text and resolution of the code.
Investigators from Massachusetts Institute of Technology (Mit), Harvard University, University of Illinois Rnyana – Champion The figurative computer. Codesesser models are good to do codes and text consultation. This approach uses a newly established benchmark, which contains 37 figurative activities, which makes researchers possible measuring and analyzed the power of model. The framework consists of a well-registered version of the LLAMA-3-8B with the Multi-Round Glood-Tuning (SFT) and the best performance (dpo).
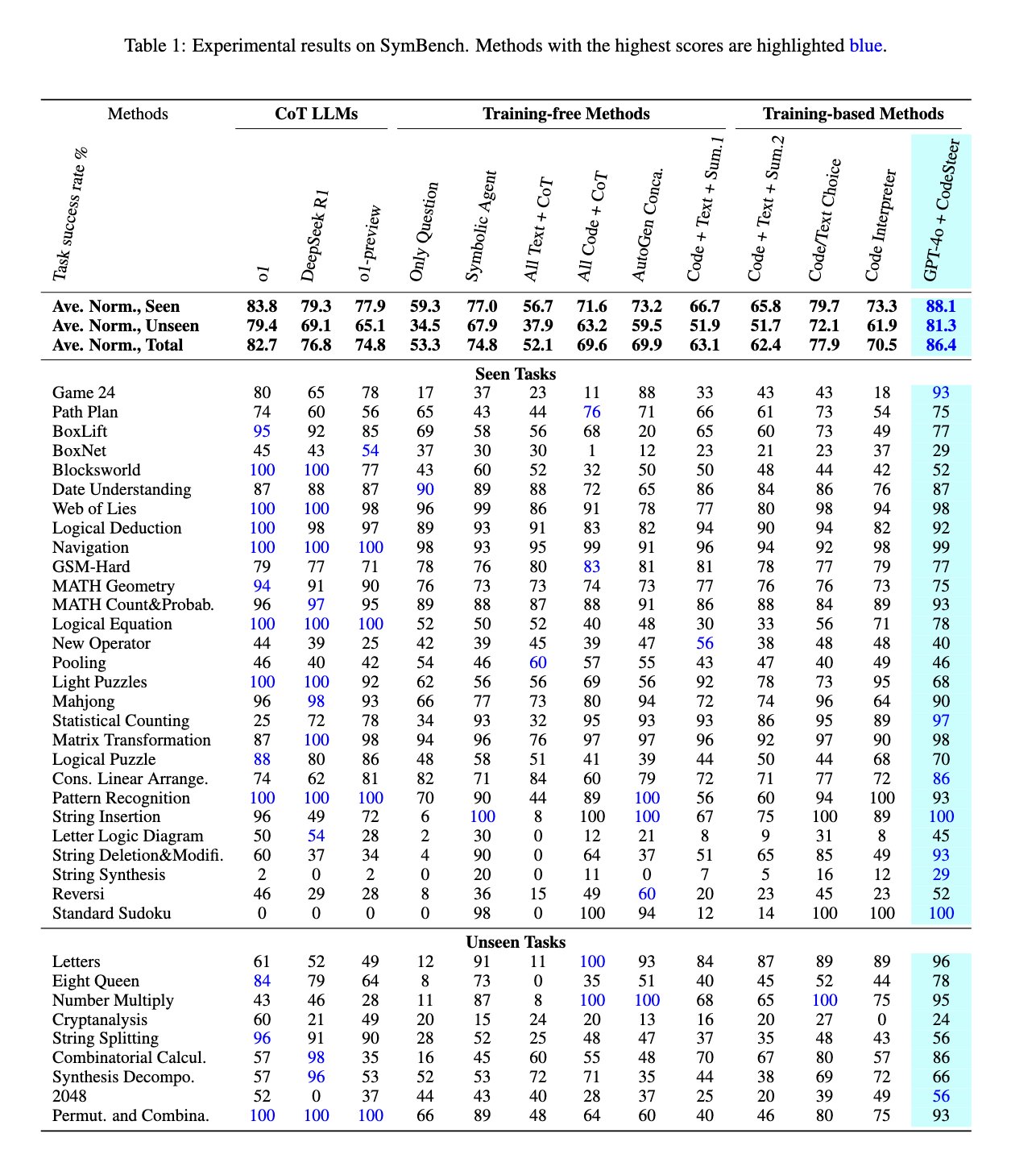
The Codeserer's framework introduces a variety of measures to improve llms consultation skills. The first step involves Sinberch, a benchmark of symbolic thinking, such as solving mathematical problems, logical decreases, and well-performance. Codesesser uses this data to produce 12,000 12,000-generation Guidelines and pairs of comparing 5,500 symptoms. changed its way to make decisions as hard. The framework is also developed by adding a symbolic check and evaluation, which ensures the accuracy and functionality of the solutions produced. These processes ensures that models do not only depend on the text-based thoughts where Code Presing is a more efficient way.
Codester's performance testing is a major development of existing llms. When combined with GPT-4O, the framework has increased the average model marks from 53.3 to 86.4 in 37 figurative activities. O1 O1 OpePperforest Open's Open summer, hit 82.7 points, and Revesiek R1, receiving 78.8 points. Codestrums indicate 41.8% of the development involving unseen activities over the Claude-3-5-Sonnet, large models, GPT-3.5. By installing a figurative computing, codeser empowering llms to maintain higher performance even in complex activities to solve problems. Benchmark results indicate that the framework indicates the accuracy and reduce the misuse of the Scriptural consultation.

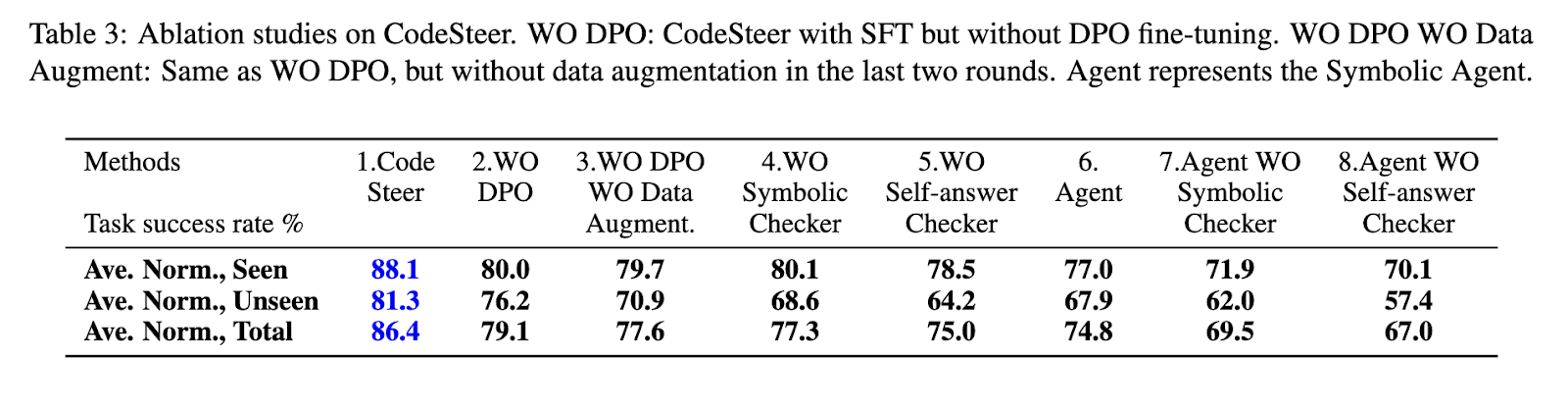
Studies highlight the importance of leading llms in determining when using a figurative Computing compare to consulting language. The proposed framework has been successfully defeated the limitations of the models in favor of formal, deciding holication. In codes, researchers develop a highly improving system of large language models, which makes them more reliable in managing problems. By successful in a figurative computer, the study notes the best step in developing and planning by AWI.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 Recommended for an open source of AI' (Updated)
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel



