Huntington Bank: Recycles sensitive data from 400M+ documents with AWS

If your document archive contains hundreds of millions of files collected over almost a decade, how do you systematically find and organize sensitive customer data without taking years to complete? This was the challenge facing Huntington National Bank (Huntington), a top ten bank in the United States.
Adjusts sensitive information at scale
As of 2015, Huntington's document management system has securely stored hundreds of millions of documents on-premises. In 2025, as part of a compliance program, Huntington began processing documents in this program and processing sensitive data. These documents come in different formats, so the solution needed to be flexible to handle various file types while delivering the output needed to process millions of documents quickly.
Actual estimates indicated that this effort would take years. However, by designing a scalable workflow using Amazon Textract, Amazon SageMaker, AWS Step Functions, and AWS Lambda, Huntington reduced this timeline to months.
Solution overview
Before examining the implementation of the technology, let's look at the key requirements that Huntington has established for this project. If you are facing a similar document processing challenge, these requirements can serve as a starting point for your solution design:
- Data should be encrypted at rest and in transit.
- Areas where data is stored or accessed must meet strict access requirements.
- The services used must be in the scope of PCI DSS compliance.
- Output must be replicated back to on-premises data stores.
- Reconstruction accuracy must meet or exceed 95% to meet compliance requirements.
The following diagram shows a high-level solution structure.
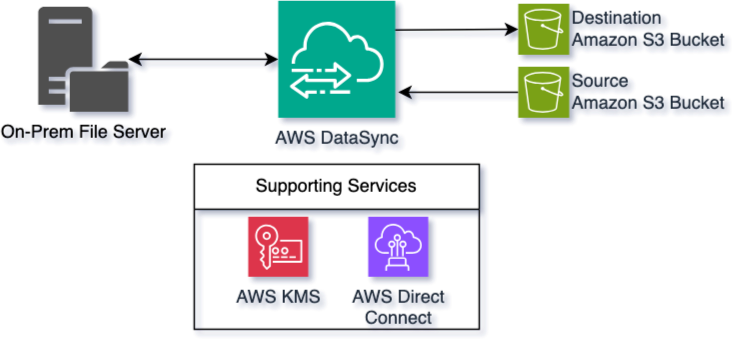
It transmits data securely, with confidence
Huntington's original goal was to move documents from a local file share to an Amazon Simple Storage Service (Amazon S3) bucket. Moving documents is straightforward, but this effort required transferring more than 400 million documents, encrypted on the go and at rest. To achieve this, Huntington used AWS DataSync, AWS Direct Connect, Amazon S3, and AWS Key Management Service (AWS KMS).
AWS DataSync can be installed as an agent in your on-premises data center to monitor a configured resource, such as an SMB file share. While getting documents to AWS was important for processing, AWS DataSync also supports synchronizing data back to the environment, which was another key requirement for this project.
Amazon Textract is an AWS machine learning service that extracts text, tables, and forms from scanned documents. Financial institutions use it to automatically process documents such as account statements or loan applications, and identify sensitive data such as Social Security numbers, account numbers, and personal addresses. The following sample invoice demonstrates this capability.

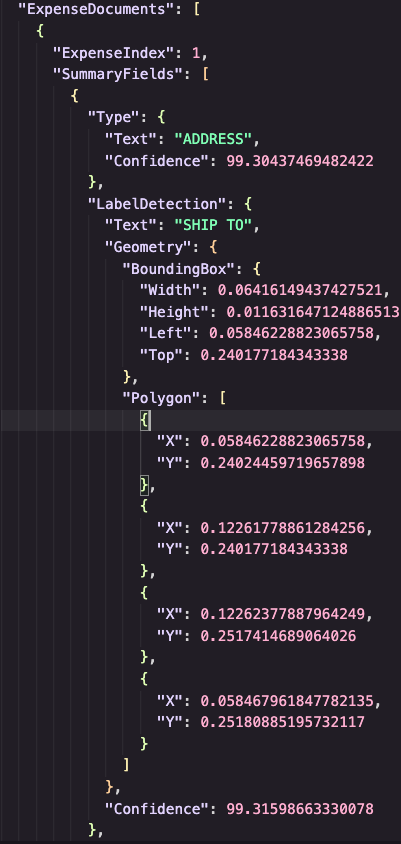
Amazon Textract finds various fields in the document and provides links to the found fields and other metadata within the JSON output.
Huntington used Amazon Text in a structured process with AWS Step Functions. This approach reduces manual review time while improving accuracy in finding sensitive information across large volumes of documents.
Discovery of scale derivatives
Automated pipelines for document processing are important, but processing documents sequentially would have stretched the project timeline into years. To accomplish their goal, Huntington had to process millions of documents each day.
Upscaling to this level required addressing two key issues: increasing Amazon Textract operations concurrently between service assignments, and controlling the number of requests to avoid bottlenecks.
AWS services have quotas that can be configured with soft and hard limits. The Amazon Textract jobs-per-second quota can be increased by submitting a request through the AWS Service Quotas console.
In order to increase the output against the service quota, Huntington used the built-in map state of AWS Actions Step, which processes input collections in JSON, CSV, or other formats. The team organized the documents in Amazon S3 into JSON arrays and ran the map state in distributed mode for maximum consistency. To track pipeline progress, they used AWS Step Functions mapping snapshots alongside Amazon CloudWatch dashboards to monitor response times, throttle counts, success, and error rates.
To address potential conflicts, Huntington monitored their CloudWatch dashboard to verify the statistics of successful Amazon Textract requests and reduced computations. As needed, they adjusted the adaptive fee limits for child workflow usage to ensure they stayed under the Amazon Textract service quota while maintaining high performance. When tasks were successfully completed, the received fields and metadata were written to a bucket for later review. The following diagram shows this method:
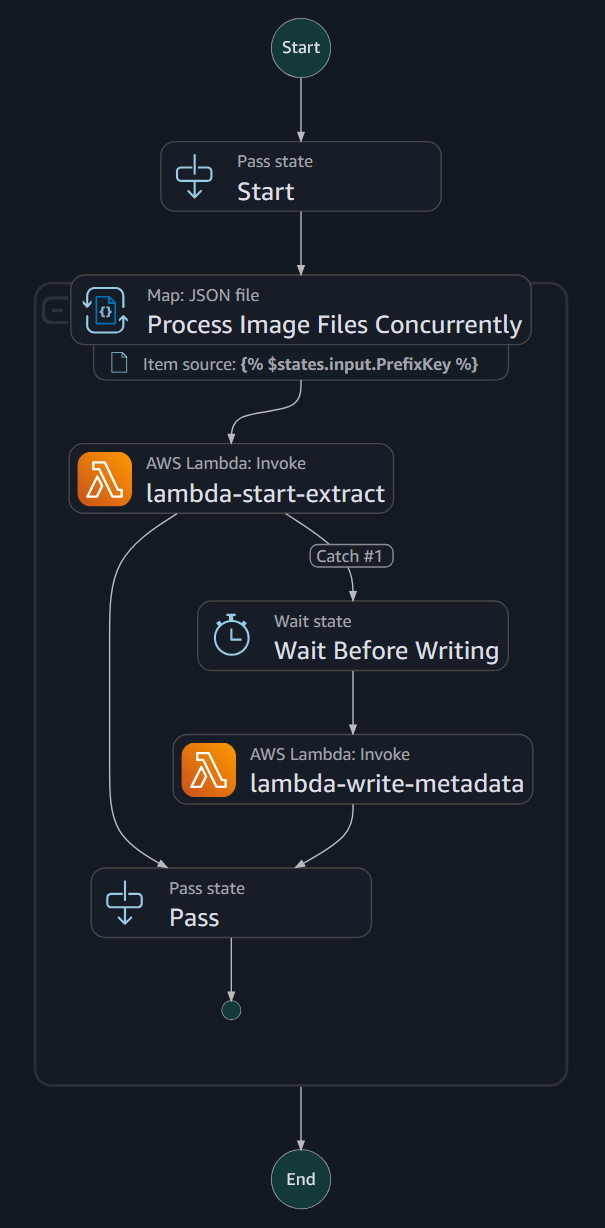
The wait block inside the step function ensures that the process is ready to continue writing the task's metadata and continue with the next Amazon Textract request. If there is no failure, the state machine terminates with a pass state. If a failure occurs, AWS Step Functions writes to a log for human review and reprocessing.
Redacts sensitive information received
Up to this point, the process has focused on finding sensitive data and writing it inside metadata files written to Amazon S3. The final steps are to recreate the documents and transfer them to the internal storage.
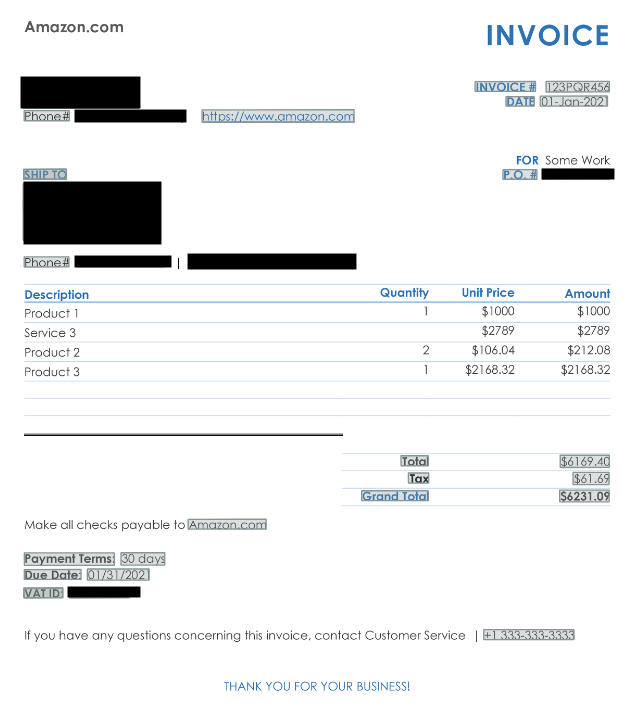
Image and PDF editing is supported by several open source and proprietary tools. Open source Python libraries include PyMuPDF or graphics libraries such as PIL. The following figure shows a sample re-invoicing shown earlier. Amazon Text supports finding various fields, and you can even create custom fields using regex patterns. Combined with the reordering software, you can confidently reorder the received fields. If you want to create a threshold for human intervention, Amazon Text provides confidence scores that can trigger validation workflows.
Once again, Huntington faced the same architectural challenge: what would this scale be? AWS Step Functions provided a solution to process millions of documents while providing hooks to handle errors and try logical reasoning. As the document processing pipeline catalogs items that need to be redone, Huntington runs a simple flow against them:
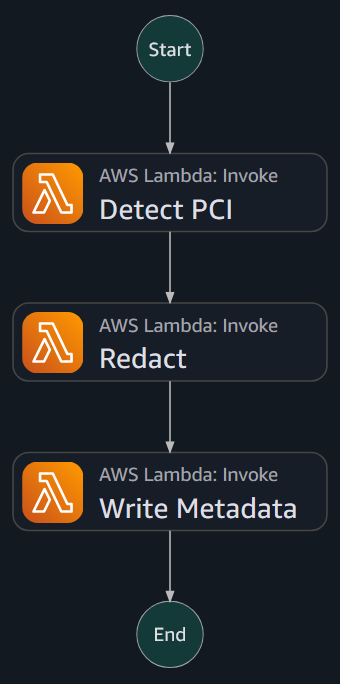
To ensure accuracy and precision, Huntington double-checked that the detected fields match expected patterns before recoding, followed by a metadata review of each file. The processed files are placed in an Amazon S3 location monitored by AWS DataSync for transfer back to the file storage.
The conclusion
Using AWS, Huntington processed approximately 10 million documents per day, reducing the average processing time from years to a few months. The cost of processing the entire archive was about 5% of the original estimate. Reconfiguration accuracy exceeded 95%, meeting compliance requirements and supporting data security objectives.
This project shows how AWS services can support big data processing and compliance measures. Huntington plans to continue using this framework for high-volume restructuring needs such as mergers and acquisitions.
To learn more about the services used in this solution, visit the Amazon Text details page or check out the AWS Step Functions documentation.
Thank you
Special thanks to the following individuals and groups for their contributions: Xuelei Yuan, Robert Carnell, Jeanne Keith, Debbie Montgomery, Bill Gross, Jodi Pettiford, Jon Glazer, Marshall Doss, Bob Wojasinski, Tami Wolf, Marijane Eldridge, Pradeep Kumar Tata, Michael Burkhardt, Nirmal Gringus Antony, Bryan Trengus Antony (AWS) Randy Patrick (AWS), Stephanie Brenneman (AWS), Art Steele, Kevin Owen.
About the writers



