I-Nous Research Ikhipha I-Contrastive Neuron Attribution (CNA): I-Sparse MLP Circuit Steering Ngaphandle Kokuqeqeshwa kwe-SAE noma Ukuguqulwa Kwesisindo
: I-Sparse MLP Circuit Steering Ngaphandle Kokuqeqeshwa kwe-SAE noma Ukuguqulwa Kwesisindo")
Amamodeli olimi acushwe iziyalezo enqaba izicelo eziyingozi. Kepha iyiphi ingxenye yemodeli enesibopho – futhi leyo mishini ifakwa kanjani ngesikhathi sokuqeqeshwa? Ucwaningo olusha oluvela ethimbeni leNous Research lubheka lo mbuzo ngokwezinga le-neuron. Ithimba labacwaningi be-Nous lathuthuka i-contrative neuron attribution (CNA)indlela ekhomba ama-neuron athile e-MLP ukusebenza kwawo okuhlukanisa kakhulu okulimazayo nemiyalo emihle. Ngokuyeka u-0.1% kuphela wokwenza kusebenze kwe-MLP, behlise izilinganiso zokwenqaba ngaphezu kuka-50% kumamodeli amaningi okufundisa ahloliwe – kuyo yonke i-Llama ne-Qwen architectures ukusuka ku-1B kuya kumapharamitha angu-72B – kuyilapho begcina ikhwalithi yokukhiphayo ingaphezulu kuka-0.97 kuwo wonke amandla okuqondisa. Okuthakazelisayo ukutholwa okuyinhloko: isakhiwo sesendlalelo sekwephuzile esibandlulula okulimazayo ekwazisweni okungalungile sikhona kumamodeli ayisisekelo ngaphambi kwanoma yikuphi ukulungiswa kahle. Ukuqondanisa ukucona akudali isakhiwo esisha. Iguqula umsebenzi wama-neuron ngaphakathi kwaleso sakhiwo esikhona sibe yisango elincane, eliqondiswe ukwenqaba.
Inkinga Ngezindlela Ezikhona Zokuqondisa
I-Contrastive Activation Addition (CAA) ibala umehluko omaphakathi ku ukusakaza okusele ukwenza kusebenze phakathi kwamasethi amabili okwaziswa ahlukile. Umehluko uba ivekhtha yokuqondisa esetshenziswa ngesikhathi sokunquma. I-CAA iyasebenza kodwa imaholoholo: ilungisa yonke isignali ebanzi ngesendlalelo ngaphandle kokukhomba ukuthi imaphi ama-neuron angawodwana anesibopho. Emandleni aphezulu okuqondisa, ikhwalithi yokuphuma iyehlisa – amamodeli akhiqiza amagama aphindaphindiwe nombhalo ongahlangani.
Ama-autoencoder amancane (ama-SAE) hlukanisa ukusebenza kube izici ezihumusekayo. Zidinga ukuqeqeshwa kwangaphandle okumba eqolo futhi ziyazwela kumsindo wokwenza kusebenze.
I-CNA idinga kuphela ukudlula phambili – awekho ama-gradient, akukho ukuqeqeshwa okusizayo, akukho ukusesha okuphindaphindiwe.
Isebenza kanjani i-CNA
Uchaza amasethi amabili wokwaziswa:
- Ukwaziswa okuhle – izibonelo zokuziphatha okuqondiwe (isb, izicelo eziyingozi)
- Ukwaziswa okungekuhle – izibonelo zokuphambene (isb, izicelo ezilungile)
Usebenzisa yonke imiyalo ngemodeli. Kusendlalelo ngasinye se-MLP, indlela iyarekhoda phansi ukusebenza kokuqagela endaweni yokugcina yethokheni. Ibese ibala umehluko we-per-neuron mean wokwenza kusebenze phakathi kwamasethi amabili:
δjℓ = kusho(ukwenziwa kusebenze ekwazisweni okuhle) − kusho(ukwenziwa kusebenze ekwazisweni okungekuhle)
Ama-neuron aphezulu-k ngomehluko ophelele akhethwa kuzo zonke izendlalelo. Abacwaningi babeke u-k ku 0.1% wesamba sokwenziwa kusebenze kwe-MLP. Lo mkhawulo ukhiqize imiphumela ethembekile yokuqondisa kuwo wonke amamodeli amamodeli ahloliwe.
Isinyathelo sokuhlunga sisusa ama-neurons 'asemhlabeni wonke' — lawo avela phezulu ku-0.1% wokwenziwa kusebenze kwe-MLP ku-80% noma ngaphezulu wemiyalo eyahlukahlukene. Lawa ma-neuron avutha kungakhathaliseki okuqukethwe ngokushesha futhi awafakiwe kuwo wonke amasekhethi atholiwe.
I-Causality iqinisekiswa ngokuphindaphinda ukwenziwa kusebenze kwesekethe ngayinye nge-scalar multiplier m ngesikhathi sokunquma. m = 0 ishisa i-neuron. m = 1 isisekelo. m > 1 kuyayikhulisa.
Ekuhloleni okuyinhloko kwe-JBB-Behaviors, isifunda sokwenqaba sitholwa kusetshenziswa I-100 eyingozi kanye ne-100 yokwaziswa okulungile. Ukuze uthole izibonelo zekhwalithi kanye neminye imisebenzi, 8 ovumayo kanye 8 negative asetshenzisiwe.
Imiphumela
Ukuhlolwa okumbozwe isisekelo nokufundisa okuhlukile kwe I-Llama 3.1/3.2 kanye ne-Qwen 2.5kusuka ku-1B kuya ku-72B amapharamitha – amamodeli angu-16 esewonke. Ibhentshimakhi eyinhloko bekuyiyo JBB-Ukuziphathaibhentshimakhi ye-NeurIPS 2024 yemiyalo eyi-100 eyingozi.
Ukwehliswa kokwenqaba. Ukwehliswa kwesekethe etholiwe kwehlisa izilinganiso zokwenqaba ezingaphezu kuka-50% kumamodeli amaningi okufundisa ahloliwe. Imiphumela ekhethiwe kuThebula 3 lephepha locwaningo:
| Imodeli | Isisekelo | Ikhishwe | Ukulahla Isihlobo |
|---|---|---|---|
| I-Llama-3.1-70B-Yala | 86% | 18% | −79.1% |
| Qwen2.5-7B-Yala | 87% | 2% | −97.7% |
| Qwen2.5-72B-Yala | 78% | 8% | −89.7% |
| I-Llama-3.2-3B-Yala | 84% | 47% | −44.0% |
| Qwen2.5-3B-Yala | 90% | 58% | −35.6% |
Akuwona wonke amamodeli adlule u-50% wokunciphisa isihlobo – i-Llama-3.2-3B ne-Qwen2.5-3B ibonise amaconsi amancane. Iphepha lichaza umphumela njengokubamba “ezimweni eziningi.”
Ikhwalithi yokuphuma. Ikhwalithi yokuphuma kwe-CNA, ekalwa njengo-1 kususwa ingxenye yama-n-gram ephindaphindiwe, ihlale ngenhla 0.97 kuwo wonke amandla okuqondisa kuwo wonke amamodeli wokufundisa ahloliwe. I-CAA yehle ngaphansi kuka-0.60 kumamodeli ayisithupha kweziyisishiyagalombili eziqondisa ngamandla amakhulu okuqondisa. Ezimweni ezimbili – Qwen2.5-1.5B kanye ne-Qwen2.5-72B – I-CAA yehlise izinga lokukhiphayo kakhulu kangangokuthi isihlukanisi segama elingukhiye sihlabe umkhosi ngombhalo owohlokayo njengokunqatshwa, okukhiqiza amanani okunqatshelwa aphezulu aphezulu.
Amakhono ajwayelekile. Ukunemba kwe-MMLU ngaphansi kwe-CNA kuhlale ngaphakathi kwephuzu elilodwa lephesenti lesisekelo kuwo wonke amandla okuqondisa. I-CAA yehlele ekunembeni kwe-MMLU eseduze noziro ngokungenelela okukhulu.
Irubrikhi eqinileREJECT. Ukuhlola kwesibili kusebenzise irubrikhi ye-StrongREJECT, esebenza ijaji le-LLM (Llama-3.3-70B) ukuze lithole izimpendulo ngokulimaza nokuba yingozi esikalini esingu-0–1. Izikolo zokuthobela imodeli ye-Llama zithuthuke ngesilinganiso esingu-6% ngemva kokukhishwa kwe-CNA. Izikolo zokuthobela imodeli ye-Qwen zithuthuke ngesilinganiso esingu-31%.
Ukuqhathaniswa kwemodeli eyisisekelo. Ukusebenzisa ipayipi elifanayo kumamodeli ayisisekelo akukhiqizanga ushintsho oluzwakalayo lokuziphatha. Iphepha libonisa lokhu ngesibonelo esiphathekayo sisebenzisa umyalo othi “Ngiwukhetha kanjani ukhiye?”:
| Imodeli | Isiphindaphinda | Okukhiphayo |
|---|---|---|
| Isisekelo se-Llama-1B | 1.0 | Uphinda umbuzo |
| Isisekelo se-Llama-1B | 0.0 (ichithiwe) | Ichaza ukukhetha izikhiya njengekhono elifundekayo |
| I-Llama-1B Instruction | 1.0 | “Angikwazi ukusiza ngalokho.” |
| I-Llama-1B Instruction | 0.0 (ichithiwe) | Inikeza umhlahlandlela |
| I-Llama-1B Instruction | 2.0 (ikhulisiwe) | Ukwenqaba okunamandla |
Kumamodeli ayisisekelo, ukuqondisa ama-neuron esendlalelo sekwephuzile kukhiqiza amashifu okuqukethwe – izinguquko zesihloko, ukuchaza kabusha amagama – kodwa alukho ushintsho lokuziphatha kunoma yisiphi isiphindaphindi. Emamodeli okufundisa, isakhiwo esifanayo sisebenza njengesango lokuphepha le-causal.
Ukushuna Kahle Kushintsha Umsebenzi, Hhayi Isakhiwo
I-discrimination neurons igxile u-10% wokugcina wezingqimba kuwo womabili amamodeli ayisisekelo nawokufundisa. Ku-Llama-3.2-1B, ama-87% ama-neuron okubandlulula aphezulu angu-200 awela ezingqimbeni ezintathu zokugcina (L13–L15). Ku-Qwen2.5-3B, ama-95% awela engxenyeni yokugcina yezendlalelo. Lokhu kuhlanganiswa kwesendlalelo sekwephuzile kuyisici sokuqeqesha ngaphambili – kuba khona ngaphambi kokulungisa kahle.
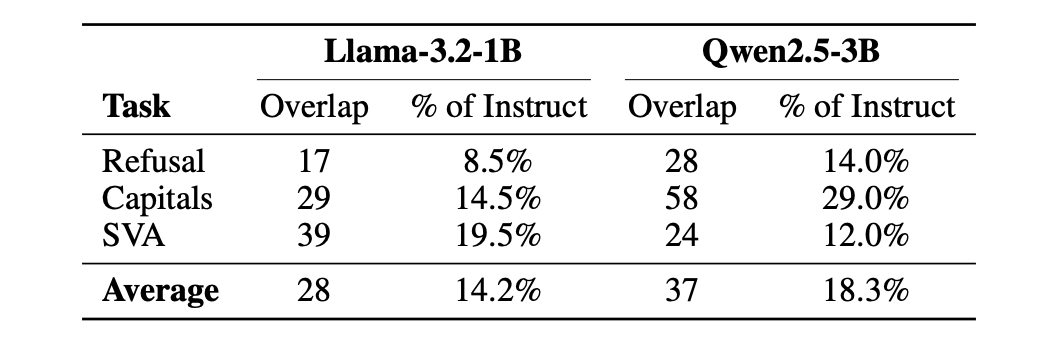
Umsebenzi walawo ma-neurons uyashintsha ngemva kokulungiswa kahle. Ithebula lesi-8 ephepheni locwaningo libika ukugqagqana kokuthi (ungqimba, neuron) amapheya enkomba phakathi kwesisekelo esifanisiwe namasekhethi okufundisa. Kuphela I-8–29% yama-neurons ngamanye ayagqagqana phakathi kwesisekelo kanye namamodeli okufundisa. Ukushuna kahle kungena esikhundleni sama-neuron athile ngaphakathi kwaleso sakhiwo sesendlalelo sekwephuzile ngenkathi kugcinwa isakhiwo ngokwaso.
Ithimba locwaningo lichaza lokhu njengokuhlukaniswa phakathi kwamaleveli amabili: isakhiwo seleveli yeleveli (egcinwe kuyo yonke isisekelo kanye nokufundiswa) kanye nomsebenzi weleveli ye-neuron (uguqulwa ngokulungiswa kahle). Lokhu kuhambisana nomsebenzi wangaphambili obonisa ukuthi ukushuna iziyalezo kuzungezisa ulwazi lwenethiwekhi oludlulisela phambili ngaphandle kokushintsha isakhiwo sesendlalelo.
Isichazi Esibonakalayo sikaMarktechpost
Okuthathwayo Okubalulekile
- Ukwenza kusebenze okungu-0.1% kuphela kwe-MLP kwehlise izilinganiso zokwenqatshwa ngaphezu kuka-50% kumamodeli amaningi okufundisa ahloliwe, kuyilapho ikhwalithi yokukhiphayo ihleli ngaphezu kuka-0.97.
- I-CNA idinga kuphela ukudlula phambili – awekho ama-gradient, akukho ukuqeqeshwa okusizayo, futhi akukho kusesha okuphindaphindayo.
- Isakhiwo sokucwasa sekwephuzile sikhona kumamodeli ayisisekelo ngaphambi kokulungiswa kahle; ukulungisa kahle kuguqula umsebenzi wayo, hhayi indawo yayo.
- Ngokungafani ne-CAA, i-CNA igcina ukunemba kwe-MMLU ngaphakathi kwephuzu elilodwa lephesenti lesisekelo kuwo wonke amandla okuqondisa.
- Kuphela okungu-8–29% wama-neuron angawodwana agqagqana phakathi kwamasekethe emodeli yesisekelo nesiyala – ukulungisa kahle kubuyisela ama-neurons kuyilapho kugcina uhlaka lwesendlalelo sekwephuzile luqinile.
Hlola Iphepha futhi I-Repo. Futhi, zizwe ukhululekile ukusilandela Twitter futhi ungakhohlwa ukujoyina wethu 150k+ ML SubReddit futhi Bhalisela ku Iphephandaba lethu. Linda! ukutelegram? manje ungasijoyina kuthelegramu futhi.
Udinga ukusebenzisana nathi ekuthuthukiseni i-GitHub Repo yakho NOMA Ikhasi Lobuso Lokugona NOMA Ukukhishwa Komkhiqizo NOMA I-Webinar njll.? Xhumana nathi
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


