Poolside AI Introduces Laguna XS.2 and M.1: Agentic Code Models Up to 68.2% and 72.5% in SWE-bench Verified

Poolside AI has released the first two models in its Laguna family: Laguna M.1 again Laguna XS.2. Along with this, the company releases lake — a lightweight terminal code agent and dual Agent Client (ACP) server — the same environment Poolside uses internally for RL agent training and testing, now available as a research preview.
What Are These Models, And Why Should You Care?
Both Laguna M.1 and Laguna XS.2 are available MoE models. Instead of turning on all the parameters for every token, MoE models route each token through a small set of specialized sub-networks called 'experts.' This means a large amount of parameter calculation and the power headroom that comes with it while paying only the computational cost of a very small “activated” parameter calculation during the determination.
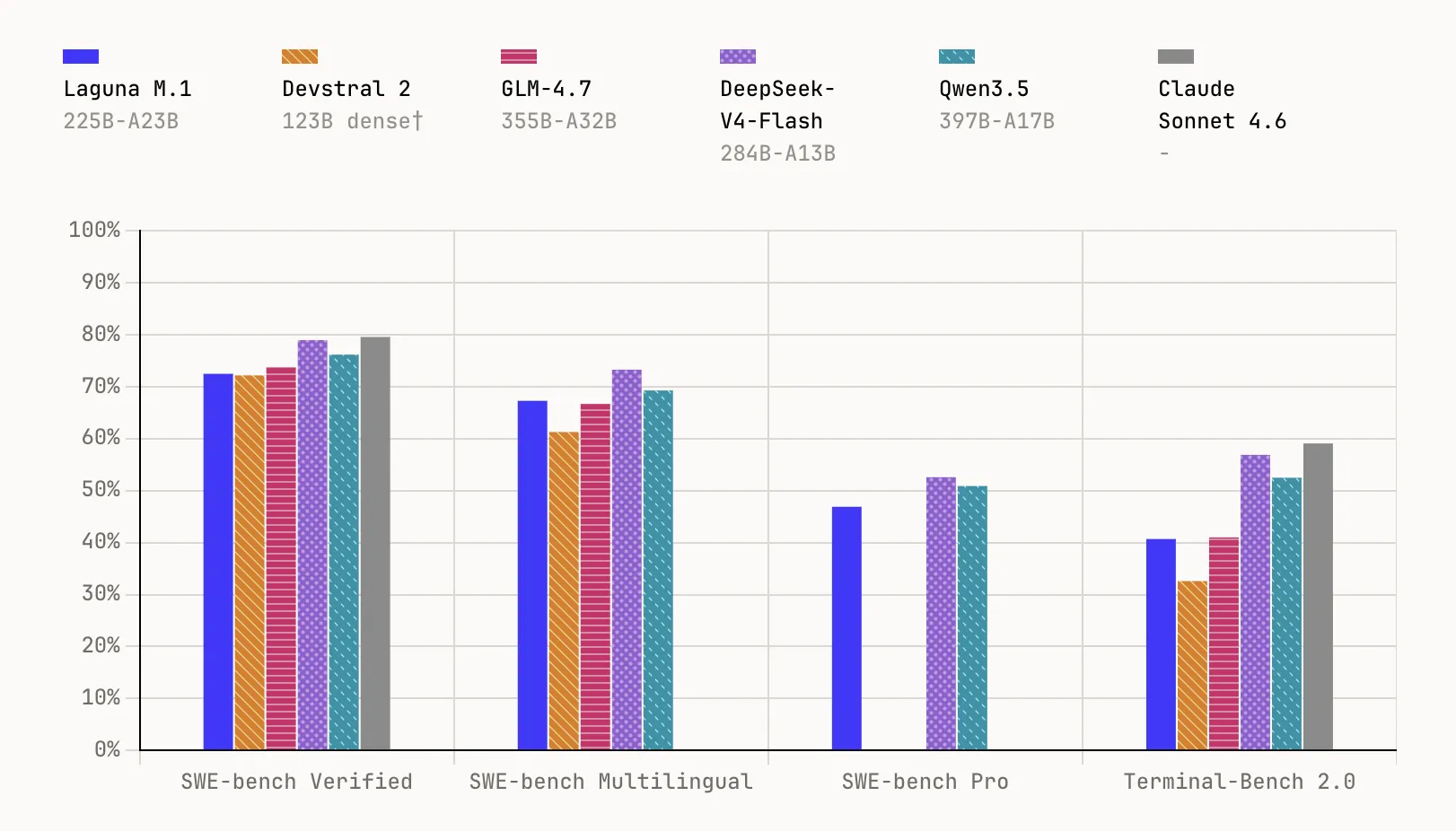
Laguna M.1 is a 225B MoE parameter model with 23B activated parameters, trained from scratch on 30T tokens using 6,144 interconnected NVIDIA Hopper GPUs. It completed pre-training at the end of last year and serves as the base for the entire Laguna family. In benchmarks, it reaches 72.5% in SWE-bench Verified, 67.3% in SWE-bench Multilingual, 46.9% in SWE-bench Proagain 40.7% in Terminal-Bench 2.0.
Laguna XS.2 is the second generation MoE model and Poolside's first open weight, built on everything learned from training the M.1. At a total of 33B parameters with 3B enabled per token, it is designed for agent coding and long-running work on a local machine — compact enough to run on a Mac with 36 GB of RAM with Ollama. It scores 68.2% in SWE-bench Verified, 62.4% in SWE-bench Multilingual, 44.5% in SWE-bench Proagain 30.1% in Terminal-Bench 2.0. Poolside will also let loose Laguna XS.2-base soon for employees who want to fine tune.
Architecture: The Efficiency Decisions in XS.2
XS.2 uses sigmoid gating with rotational scales for each layerwhich allows for a hybrid sliding window attention (SWA) and global attention structure at a ratio of 3:1 across a total of 40 layers — 30 SWA layers and 10 global attention. Sliding Window Attention limits the attention of each token to a local window of 512 tokens rather than the full sequence, dramatically cutting KV cache memory. Layers of global attention at a ratio of 1-in-4 maintain long-range dependence without paying the full cost of coverage. The model also measures the KV buffer FP8it further reduces the memory with each token.
Under the hood, the XS.2 uses 256 experts and one shared expertsupports a 131,072 token content windowand includes support for logic — centralized logic between tool calls with per-application control over enabling or disabling logic.
Training: Three Poolside Areas Pushed Hard
The Poolside team trains all of its models from scratch using its own data pipeline, its own training codebase (Titan), and its own agent RL infrastructure. Three areas saw special investment in Laguna.
AutoMixer: Configuring Data Mixing Automatically. Data selection and pooling for training has a significant impact on the performance of the final model. Rather than relying on manual heuristics, Poolside developed an automated hybridization framework that trains a set of up to 60 proxy models, each hybridized with different data, and measures performance across key groups—coding, math, STEM, and common sense. Subsequent regressors are then fit to estimate how changes in the dataset's measurements affect the downward calibration, providing a map of the learning from data mixing to performance that can be directly improved. The method is inspired by previous work involving Olmix, MDE, and RegMixconverted to a Poolside setting with rich data sets.
On the data side, both models of Laguna were trained on more than 30T tokens. Poolside's approach to maintaining diversity in data storage – which stores moderate and low-quality buckets next to high-quality data to avoid STEM bias – produces approx. 2× more unique tokens compared to precision oriented pipes, a continuous advantage in long training areas. A different analysis of the deductions also confirmed that global subtraction uniformly removes high-quality datato inform how the team adjusts its pipeline. Synthetic data provides about 13% of the final training mix in the Laguna XS.2, with the Laguna series using approx 4.4T+ artificial tokens in total.
The Muon Optimizer. Rather than AdamW – the most common optimizer for large model training – Poolside used a distributed implementation of Muon optimizer in all training phases of both models. In the first release of pre-training, the research team achieved the same training loss as the AdamW baseline 15% few stepswith a large increase in overall assessment in the final model, and a transfer of learning rate to all model scales was achieved. An additional benefit: Muon requires only one state per parameter rather than two, reducing memory requirements for both training and indexing. During previous training of Laguna M.1, the overhead from the optimizer was less than 1% of the training step.
The poolside also runs periodic hash tests on model weights in all training simulations to catch silent data corruption (SDC) on idle GPUs – especially errors in arithmetic logic and pipe registers, unlike DRAM and SRAM that are not covered by ECC protection.
Async On-Policy Agent RL. This is arguably the most complex piece of Laguna's training stack. Poolside has built a fully asynchronous online RL system where the actor process pulls tasks from a dataset, wraps sandboxed containers, and executes a production agent binary against each task using a newly installed model. The resulting trajectories are scored, sorted, and written Iceberg tableswhile the trainer continues to use those records and produce the next test site — the consideration and training work in parallel, improved tuning to measure the intensity of the policy.
Key Takeaways
- Poolside releases its first open weight model: Laguna XS.2 is a 33B MoE parameter model with only 3B open parameters per token, available under the Apache 2.0 license — compact enough to run locally on a Mac with 36 GB of RAM with Ollama.
- Robust benchmark performance at small scale: The Laguna XS.2 achieves 68.2% in SWE-bench Verified and 44.5% in SWE-bench Pro, while the larger Laguna M.1 (225B total, 23B activated) achieves 72.5% in SWE-bench Verified and 46.9% in SWE-bench Pro – both trained from 3
- Muon optimizer beats AdamW by 15% in training efficiency: Poolside replaced AdamW with a distributed implementation of the Muon optimizer, achieving the same training loss with about 15% fewer steps, with lower memory requirements – only one condition per parameter instead of two.
- AutoMixer replaces manual data mixing and learning: Instead of manual data recipes, Poolside trains a bunch of ~60 proxy models on different data mixes and fits regressors to increase the fit of the dataset – with synthetic data making up ~13% of Laguna XS.2's final training mix from a total of 4.4T+ synthetic tokens.
- A fully asynchronous RL agent with GPUDirect RDMA load transfer: Poolside's RL system uses indexing and training in parallel, transferring hundreds of gigabytes of BF16 weights between nodes in less than 5 seconds with GPUDirect RDMA, using token access, token actor design and the CISPO algorithm for policy-free training stability.
Check it out Model weights again Technical details. Also, feel free to follow us Twitter and don't forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.?contact us
The post Poolside AI Launches Laguna XS.2 and M.1: Agentic Coding Models Up to 68.2% and 72.5% on SWE-bench Verified appeared first on MarkTechPost.


")
