
Introduction
In recent years, Generative Adversarial Networks (GANs) have achieved remarkable results in automatic image fusion. However, objectively assessing the quality of the generated data is still an open challenge. Unlike discriminative models, where established metrics exist, generative models require an evaluation method that can measure both observables. level again diversity of the samples produced.
One of the first metrics used was the Inception Score (IS). Based on the predictions of the pre-trained Inception network, the Inception Score provides a quantitative measure of the generative model's ability to produce realistic and statistically meaningful images.
In this article, we analyze the idea behind this parameter and how to understand its validity, analyzing the limitations that led to the use of other evaluation metrics.
1. What is a Generative Adversial Network (GAN)
A network can be defined as a Deep Learning framework which, given an initial data distribution (Training Set), allows generating new data (synthetic data) with characteristics similar to the initial distribution.
In general, in order to derive the concept of GAN, we can refer to the metaphor of “compositor and art critic”. The fake (Generator) aims to draw images (synthetic data) that are as similar as possible to the real ones (Training set). On the other hand, the art critic (Discriminator) aims to distinguish which pictures are painted by the artist and which are authentic. As you can imagine, the main goal of the artist is to deceive the art critic, or rather, to paint pictures that the art critic will see as true.
In the early stages, the creator does not know how to deceive the critic, so it will be easier for the latter to spot fakes. But step by step, thanks to the critic's feedback, the composer will be able to understand his mistakes and improve, until he reaches his goal.
To translate this metaphor into practical terms, a GAN consists of two agents:
- Generator (G): you are responsible to reproduce synthetic data. Gets the noise vector z as an input, usually drawn from a normal distribution N(0,1) with a value of 0 and a variance of 1. This vector will be passed to the generator, which will return the “Generated Image.” The shape of the generator funnel is random. In fact, G makes a up-sampling procedure: suppose u has size [1,300]; as it passes through the various parts of the generator, its size increases until it becomes a dimensional image [64,64,3].
- Discrimination (D): discrimination or rather it separates which data is part of the original distribution and which is synthetic data. Unlike the Generator, the discriminator does a low sample process: let's say that the input image has dimensions [64,64,3]; the discriminator will extract features such as edges, colors, etc., until it returns a value of 0 (fake image) or 1 (real image)
I z vector plays an important role. In fact, another property of the generator is that it produces images with different characteristics. In other words, we do not want G to produce the same or similar diagram (mode folding).
To make this happen, I need my vector z having different values. These will activate the production weights differently, producing different output characteristics.
2. Initial score (IS)
One of the best “metrics” for evaluating a GAN network is undoubtedly the human eye. But… what parameters do we use to evaluate a productive network? The important parameters are level again diversity of produced images: (i) Quality refers to what a beautiful picture. For example, if we trained our generator to generate images of dogs, the human eye should actually detect the presence of a dog in the generated image. (ii) Diversity refers to the capacity of the network to act produce different images. Continuing with our example, dogs should be represented in different places, in different types and shapes.
Obviously, checking all possible images produced by the generator “by hand” becomes difficult. The initial score (IS) helps us. IS is a metric used to determine the quality of a GAN network in generating images. Its name is derived from the use of the Inception classification network developed by Google and pre-trained on the ImageNet dataset (1000 classes). In particular, IS looks at both the quality and diversity of the aforementioned properties, using two types of possibilities. Two probability distributions are obtained by considering a collection of about 50,000 generated images and the results of the final layer of network classification.
- Conditional Probability (Pc): Conditional probability refers to G's ability to produce images with well-defined subjects, i.e., image quality. Images are classified as belonging to a specific category. Here, the entropy is low (low surprise effect), or rather, the classification distribution is concentrated in one class. Pc size is [batch,1000].
- Marginal Probability (Pm): Marginal probabilities allow us to understand whether the generator is capable of producing images with unique characteristics. If it wasn't, we might have a sign of that mode foldingthat is, the generator always produces the same images. Marginal opportunities are found through reflection PC and we calculate the ratio on the 0 axis (which we calculate its ratio to the mass). In this case, the classification should be a uniform distribution. The size of the Pm there is [1,1000].
An example of what is described is shown in the picture.

The last step is to combine the two possibilities. This classification is done by calculating the KL (Kullback–Leibler) distance between Pc and Pm and measuring it by the number of samples used. In other words, if we consider the i-th vector of Pc, we see how much the conditional probability of the i-th image deviates from the equation.
The desired result is that this grade is high. Basically:
- Assuming that the generator produces fixed images, then, for each image, the conditional probabilities are concentrated in one class.
- If the generator does not show mode folding, then the images are divided into different classes.
And here the question arises: High compared to what?
3. Placement of synthetic data
Let ISᵣₑₐₗ be the First Result calculated from the test dataset and ISₛ be the one calculated from the generated data. A production model can be considered satisfactory if:
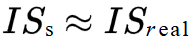
or better if the First Score of the synthetic data is close to that of the real data, suggesting that the model correctly reproduces the label distribution and visual complexity of the original dataset.
3.1. Limitations
The presentation of the synthetic data area aims to provide a benchmark for interpreting the obtained value. This can be very important in situations where the generator G trained to produce images of 1000 classes where the First network was trained.
In fact, since the Inception network used to calculate the Inception Score was trained on ImageNet The dataset, which includes 1000 regular classesit is possible that the distribution of classes learned by the generator G is not directly represented within that semantic space. This feature can limit the interpretation of the First Result to the specific context of the problem under consideration. In particular, the First network can classify both the images in the training dataset and those generated by the model as belonging to the same ImageNet class, generating constant values (mode folding)
In some cases, the Inception Score can still provide a first indication of the quality of the generated data, but it is still necessary to combine the Inception Score with other quantitative metrics to obtain a complete and reliable assessment of the performance of the generating model.



")