Opelai released 'Cyuit-Sparsity': A collection of open source tools for connecting Weight Sparse models and dense bases through active bridges

The Opelai Team released openai/circuit-sparsity model in kissing face no openai/circuit_sparsity Tool on GitHub. Release packages are models and circuits from the paper 'ight-sparse transistors have switching circuits'.
What is variable weight?
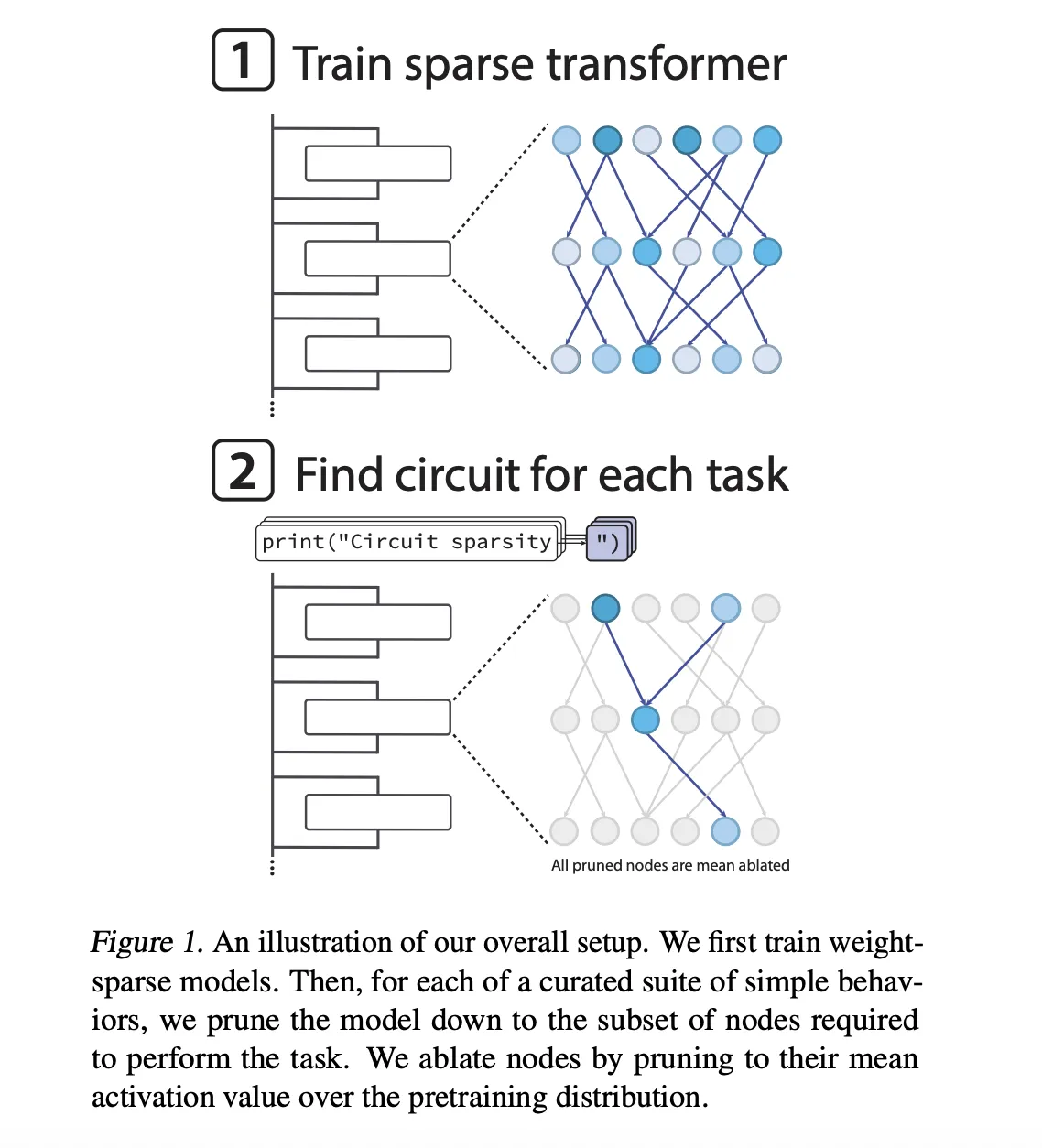
Models are only GPT-2 style decoders that are converted to trained Python code. Sparsity is not added after training, it is enforced during optimization. After each Adamuw step, the training loop keeps only the largest entries in all the weight and bias matrices, including embedding tokens, and zeros at rest. All matrix rules retain the same fraction of nonkero elements.
The sparsest models are approx 1 in 1000 nonkero instruments. In addition, the Opelai group is forced to operate a mild transit actiation to approx 1 in 4 Node an nonzero performance, covering residual reading, residual writing, attention channels and MLP Neurons.
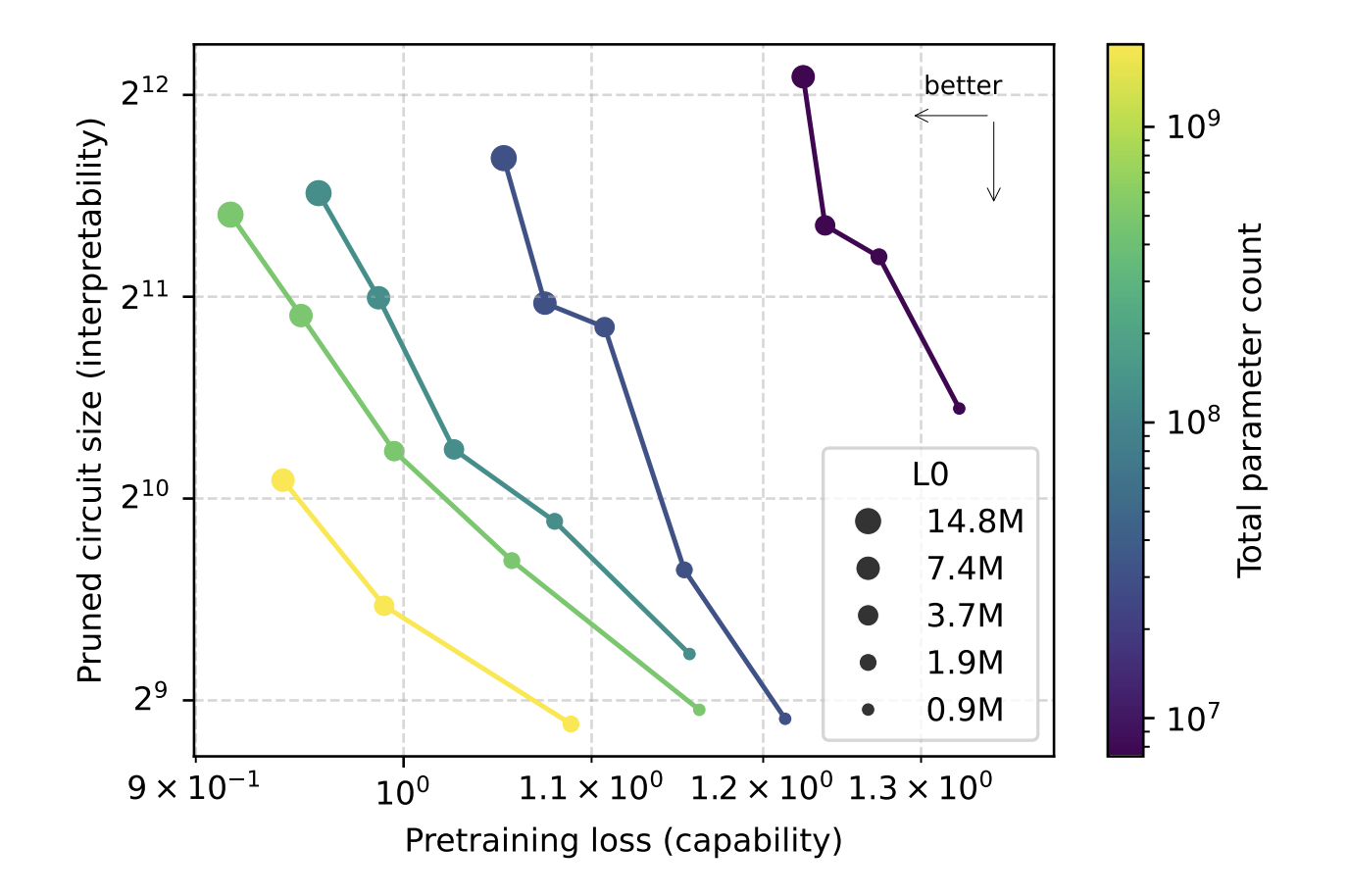
Sparsity is invoked during training. The models start densely, then the nonzero allowed budget gradually moves towards the target value. This design allows the research team to estimate while holding a number of nonzero parameters fixed, and then study the variation of explAbility as they vary with incidence and model size. The research group shows that, with a given loss, the circuits found in the space models are approximately 16 times is smaller than that from dense models.
So, what is the intense cycle?
What is included in this research project is a sparse cycle. The Research Team defines the nodes of great granularity, each node is a single neuron, an attention channel, a residual learning channel or a residual writing channel. A single nonzero entry edge in the weight matrix connecting two points. The size of the circuit is measured by the number of geometric shapes in all operations.
To investigate the models, the group is composed of 20 Simple Python Token binary functions. Each function forces the model to choose between 2 different terminations for one Symbol. Examples include:
single_double_quotesuggest that you close the thread with a single or double measurebracket_countingcut in half]and]]Based on roster depthset_or_stringtrack whether the variable was initialized as a set or a string
For each task, they trust the model to find the smallest cycle that still reaches the target loss 0.15 in that work distribution. Trees work at the local level. Nodes have been removed It means to appeartheir performance is frozen in what means the spread of distrust. The learned mask learned node by node is done vertically in a surrogate style so that the objective can trade off the loss of function and the size of the circuit.
For example, circuits, rate closures and parentheses
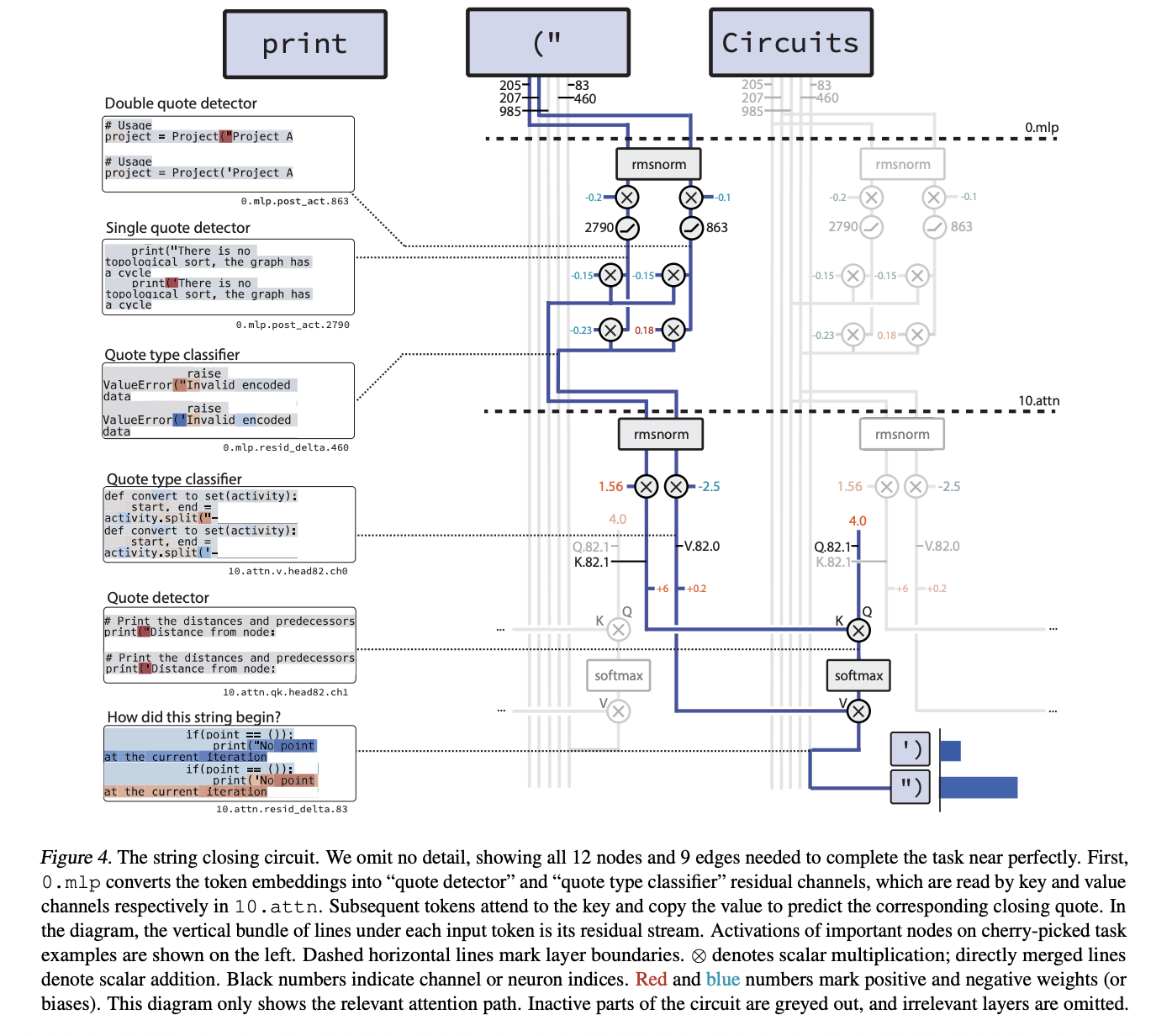
The most perfect example is the cycle of single_double_quote. Here the model should generate the appropriate closing rate given the opening rate. The cycle you buy has 12 nodes and 9 edges.
A two-step machine. Layer 0.mlp2 Specialized Neurons:
- a Quote detector A neuron that works in both
"and' - a Type of Quote Classifier The Good Neuron
"and bad'
Head of attention later in the layer 10.attn It uses the Quote Detector channel as the key and the Rate Classifier channel as the value. The last token has a constant affirmative question, so it takes attention away from corrupting the right kind of measure in the last state and the model closes the thread properly.
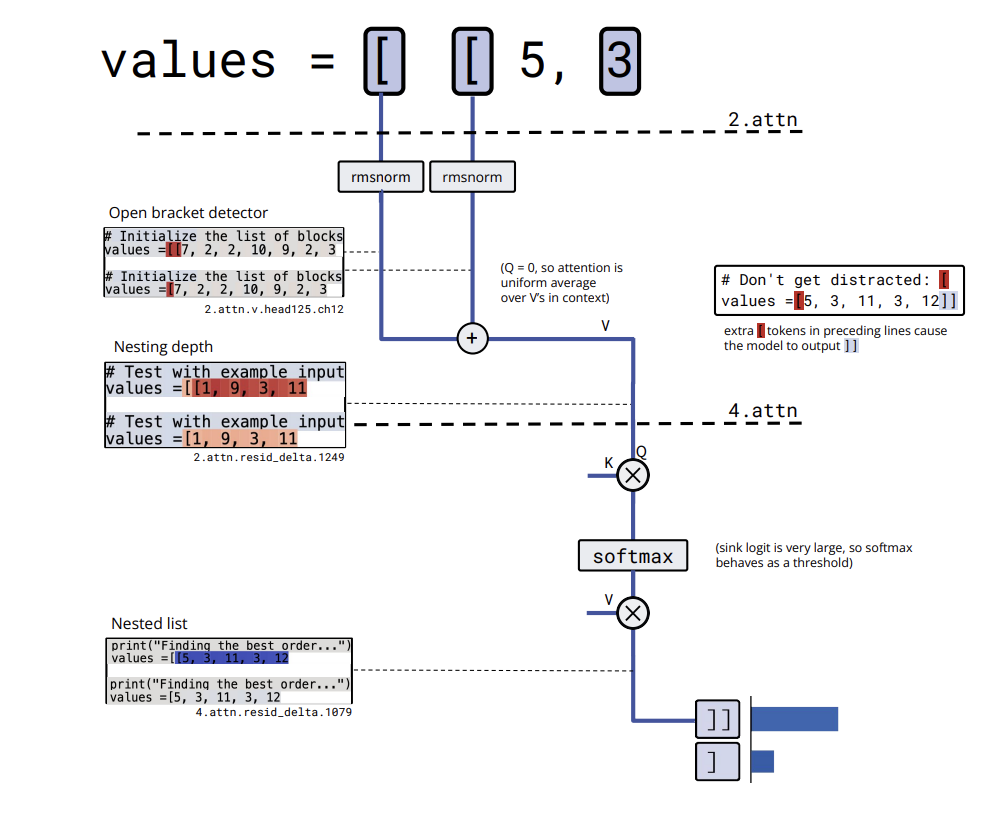
bracket_counting It presents a slightly bigger cycle but with a clear algorithm. Embedding of [ writes into several residual channels that act as bracket detectors. A value channel in a layer 2 attention head averages this detector activation over the context, effectively computing nesting depth and storing it in a residual channel. A later attention head thresholds this depth and activates a nested list close channel only when the list is nested, which leads the model to output ][Zosokhu.
Umjikelezo wesithathu, ngoba set_or_string_fixedvarnameikhombisa ukuthi imodeli ilandelela kanjani uhlobo lokuguquguquka olubizayo current. Inhloko eyodwa ikopisha ukushunyeka current ku set() noma "" Ithokheni. Inhloko yakamuva isebenzisa lokho kushumeka njengombuzo kanye nokhiye ukukopisha imininingwane efanele emuva lapho imodeli kufanele ikhethe phakathi .add na- +=.

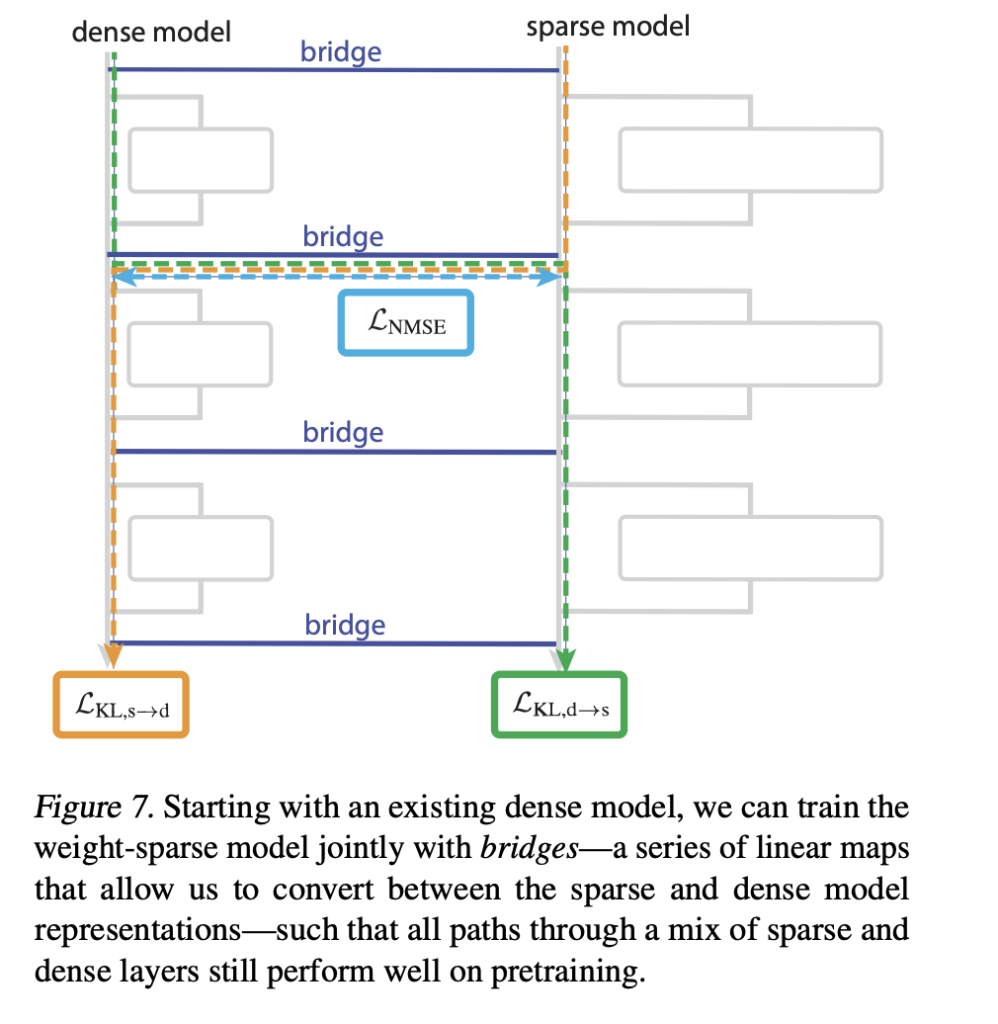
Amabhuloho, ukuxhuma amamodeli ahlekisayo kumamodeli aminyene
Iqembu lokucwaninga libuye sethula amabhuloho Lokho kuxhuma imodeli ye-sparse kumodeli ebule eqeqeshiwe esevele eqeqeshiwe. Ibhuloho ngalinye liyi-encoder decoder pair e-amamephu asebenza ngokusebenza ngokusebenza kwe-spase kanye ne-wack kanye nge-sublayer ngayinye. I-Encoder isebenzisa imephu eqondile enokwenza kusebenze i-Abtopk, i-decoder iqondile.
Ukuqeqeshwa kunezela ukulahleka okukhuthaza ukudluliswa kwesikhashana okuqhubekayo kudlula ukufanisa imodeli yobukhulu yasekuqaleni. Lokhu kuvumela ithimba lokucwaninga le-perturture ehunyushwa ngezinto eziguqukayo ezifana nesiteshi se-Quote yohlobo lwe-Quote bese imephu lelo hlazo kwimodeli emine, iguqula indlela yayo ngendlela elawulwayo.
Ngabe ikhishwe yithimba le-OpenAI?
Iqembu le-Opelai njengoba likhishwe openai/circuit-sparsity imodeli ku- Ukubopha ubuso. Lokhu yi Ipharamitha engu-0.4b Model Tagged nge custom_codeehambelana nayo csp_yolo2 ephepheni locwaningo. Imodeli isetshenziselwa imiphumela efanelekile ekubaleni kwe-bracket nokubopha okuguquguqukayo. Inamalayisense ngaphansi kwe-Apache 2.0.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
if __name__ == "__main__":
PROMPT = "def square_sum(xs):n return sum(x * x for x in xs)nnsquare_sum([1, 2, 3])n" tok = AutoTokenizer.from_pretrained("openai/circuit-sparsity", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( "openai/circuit-sparsity", trust_remote_code=True, torch_dtype="auto", ) model.to("cuda" if torch.cuda.is_available() else "cpu") inputs = tok(PROMPT, return_tensors="pt", add_special_tokens=False)["input_ids"].to( model.device ) with torch.no_grad(): out = model.generate( inputs, max_new_tokens=64, do_sample=True, temperature=0.8, top_p=0.95, return_dict_in_generate=False, ) print(tok.decode(out[0]skip_special_tokens=True)) ``` :contentReference[oaicite:14]{index=14}
Key taken
- Weight training is sparse, not posted: Circuit Sparsity models train GPT-2 style decoder models with an over-complexity bounded by optimal execution time, most parameters are zero so each neuron has few connections.
- Small Small Circles with Clear Areas and Edges: The research group describes the holes at the level of individual neurons, attention channels and residual channels, and finds patches that often have edges for several areas of 20 token activities.
- The closing rate and following typing have fast circles: For jobs like
single_double_quote,bracket_countingandset_or_string_fixedvarnameThe research group divides the circuits using concrete algorithms to obtain the measurement, the depth of the bracket and the tracking of the type, with the circuit of closing the wires using 12 nodes and 9 edges. - Models and tools for kiss face and github: Opelai released parameter 0.4b
openai/circuit-sparsityThe model is full-faced and full-facedopenai/circuit_sparsityCodebase on GitHub under Apache 2.0, including view models, function definitions and cycle view UI. - Bridge Mechanism Accounting for sparse and dimensional models: The work presents the encoder-decoder bridges that map between several operations and dense operations, allowing researchers to transfer the intervention of the characteristic to change the general objects and to learn how the circles interpret the goals.
Look Paper weight and model. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.

 Method That Reduces Doom Loops in Consulting Models")

 Open Model with 21B Functional Parameters and 256K Content")
