Stanford investigators introduce Medagentbench: The real bench in the world is Healthcare Ai Agents

They have been issued by a team of Stanford University investigators MedagenchThe new Benchmark Suite is designed to examine the largest linguistic agents (llm) in health conditions. Unlike questions to answer previous questions, Medagentbench provides a Virtual Electronic Health Record (EHR) When AI programs should be involved, plan, and do small clinics. This observing significant shifts in static thought assessment to assess Agentic skills in Live, medical flow based on tools.
Why do we need Agentic benches in health care?
The latest llms is gone across the interaction based on the conversation Agentic behaviorDirecting the highest commands, driving the apis, to compare patience data, and change complex procedures. Medicine, this nature can help in address Human shortage, Scriptural responsibility, and administrative malfunction.
While agent agents rent (eg, agentbench, agentboard board, Tau-Bench) is, HealthCare has no ordinary sign That holds the hardness of medical data, FHIR interactions, and patient records. Medagentbench fills this gap by providing a recycling framework, which is appropriate at the clinic.
What does the medagentbench contain?
How are jobs organized?
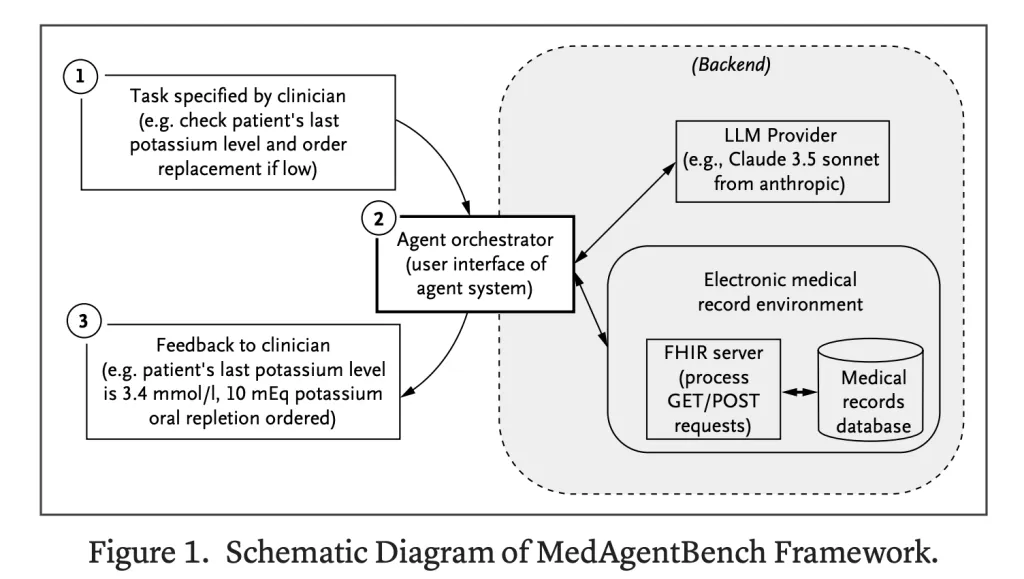
Medagennench contains 300 jobs in all 10 categorieswritten by licensed doctors. These activities include retrieving patient information, following the result of LAB, documents, testing, transfers, and medical management. Jobs between 2-3 measures and the travel of the mirror meeting with inpatient and external care.
What are the patience data supporting benchmark?
Benchmark Thumbnails 100 patient profiles are real issued at Stanford's Starr Data repository, including more 700,000 records Includes Labs, enemies, diagnosis, processes, and medicines. Data was identified by DE-Devid and Jersed with Privacy While Keeping Clinical Truth.
How is nature formed?
Nature is this Fhir-accompaniedsupporting everything (find) the conversion (post) of EHR data. AI programs can imitate the actual interaction of clinics such as writing vitals or to set for medicine orders. The project makes a direct benchmark of live EHR programs.
How are the models checked?
- Metric: The level of work success (SR) is rarely measured Pass @ 1 to indicate the original security needs of the world.
- Models surveyed: 12 leading lead including GPT-4O, Claude 3.5 Sonnet, Gemini 2.0, Deepseek-v3, Q3, XWEN2.5, and LLAMA 3.3.
- Agent Orchestrator: The basic edition of orchesthiparnarnarnization for nine FHIR activities, restricted to Eight communication around each work.
What models do you do well?
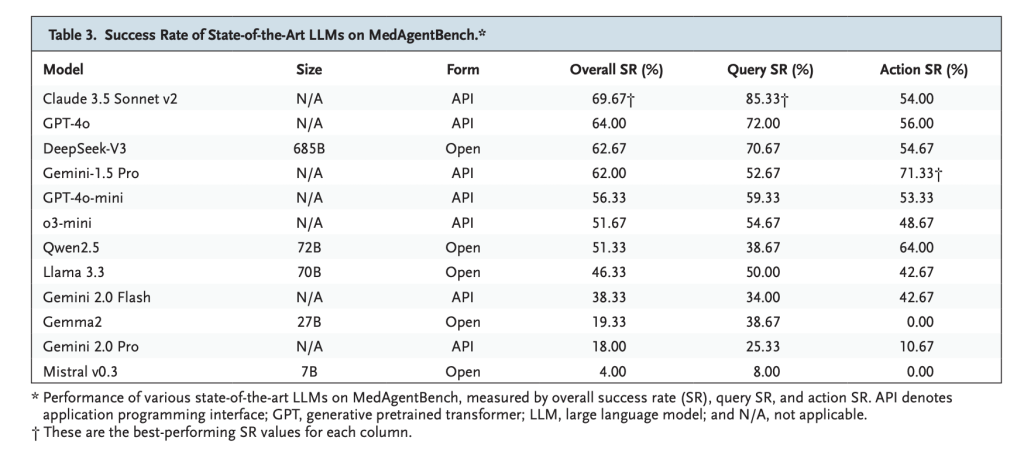
- Claude 3.5 Sonnet V2: It's very nice with Success of 69.67%especially strong in return activities (85.33%).
- GPT-4O: 64.0% success, demonstrating a balanced return and performance of actions.
- Deepseek-V3: 62.67% success, leading between open mass models.
- Vision: Most Beautiful Models at Question Jobs but he fought with the Activated activities in action requiring secure safe kill.
What do models do?
Two outstanding failures appear:
- Failure to hold messages – Invalid API calls or JSON formatting.
- Out of the wrong – Providing comprehensive sentences when prices are required.
These errors highlight spaces in accuracy and trustBoth delicate in clinical pursuits.
Summary
The Medagennench is establishing the first rate of the EHM's first-time tests in Ehres EHR Settings, pairing 300-year-old photography. Results show powerful reliability but limited to limited-claim 3.5 summed v2 leads to 69.67%-Hizighting the gap between successful questions and performing a safe action. While oppressed by one institutional and Ehr-Gorget Scope, Medagentbench provides an open framework, which will be rebuilt by the next AI AGENTCA AID generation
Look Paper including The technical blog. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.

Michal Sutter is a Master of Science for Science in Data Science from the University of Padova. On the basis of a solid mathematical, machine-study, and data engineering, Excerels in transforming complex information from effective access.



