Baidu offs Ernie-4.5-21B-A3B-imagine: Compact Moe model of deep consultation

The Baidu Ai research team has already issued Ernie-4.5-21B-A3B-thinkerThe new model of the new language focuses on focusing on efficiency, long-term thinking, and integrated tools. To be part of the Ernie-4.5 family, this model is Mixture-expertsWhy it's a good thing while maintaining competitive thinking. Extracted under the Apache-2.0 Licensefound in the management of research and commercial sales with Kisses face.
What is the design design Ernie-4.5-21B-A3b – an thinking?
Ernie-4.5-21B-A3B-thinking was built in A mixture-experts of backbone. Instead of using all 21B parameters, the router selects professional subset, leading to Active 3B parameters per Token. This structure reduces integration without compromising various experts. Research team is working The loss of a router orthenonization including Losing Loss of Token Encouraging the operation of different scholars and stable training.
The project provides the medium-sidewalk between the tense models and large Ultra-big programs. The consideration of a team of research team includes the idea that active 3B parameters in each token may represent active a pleasant place to think good performance.
How does the model take a long-term thinking?
Ernie-4.5-21B-A3B-thinking 128k the length of the area. This allows the model to process the longest documents, make more expanded thinking, and combined with systematic data sources such as educational papers or multiple file codes.
Research team achieves this Continuous development of rotary rotary positions (wires)By increasing the frequency basis from 10k until 500k during training. Excess start, including The attention of flashmask And planning a practical remembrance, making these contexts a long time ago.
What training strategy supports its thinking?
The model following a multi-class phase recipe described across the Ernie-4.5 Family:
- Stage I – Pred-Only He built a basket of basic language, starting in the 8K context and expanded to 128k.
- Category II – Vision Training Skip this text only different.
- Category – Functional Training Multimodal It is not used here, as a3B thought is completely text.
Training after receiving Functions of consultation. Research team is hiring To direct the beauty of directive (sft) In all math, logical, codes, and science, followed by Continuous Successful Reading (prl). The reinstatives begin with a logic, and extend into mathematics and programs, at the end of the widespread tasks of thinking. This is enhanced by To Simple Simplified (UPO)which includes popular learning about PPO to strengthen align and reduce the reward.
What role in using the use of this model?
Ernie-4.5-21B-A3B-Thinking Thinking A systematic tool and phone callMaking it useful for circumstances in which it is compiled or external returns. Developers can include it vllm, Refers 4.5++beside Freeprotion. This use of tools are especially ready Programing program, symbolic thinking, and the movement of multi-agent work.
The built-in driver allows the model to consider the long conditions while renewing foreign APIs, which is important to consult used in business programs.
Ernie-4.5-21B-A3b – An Impersonally Doing Thinking About Hunder?
Displays strong optimization of operation in all Logical, Mathematics, Quality Spring Activities, and editing activities. In testing, the model shows:
- Advanced accuracy in Datasets with many thoughtswhere long thoughts are needed.
- Competition in maximum dense models Stem consultation activities.
- Stable Generation of generation and educational workBenefiting from the Extension Training.
These results suggest that MOE structure increases the technologyTo make it effective without needing billions of parameters.
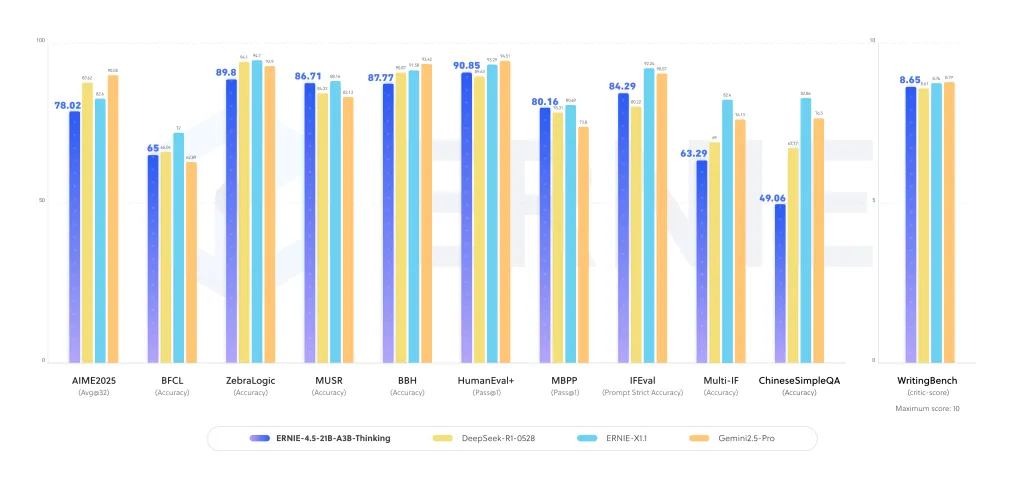
How are you compared to other focused focus of focused?
This release comes into a conchanger involving O3, Anththropic's Claude 4, Deepseek-R1, and QWEN-3. Many of these competitors rely on crowded construction or calculation of large parameters. Baidu Cawvesta The selection of a group of group Compact Moe with active 3B parameters It provides a different balance:
- Scale: Sparse's operation reduces more compute in top of the top while measuring the capacity of the expert.
- Ready for a long context: The 248k context is directly trained, not returned.
- The opening of the sale: Apache-2.0 license reduces business acquisitions.
Summary
Ernie-4.5-21B-A3B-thinking sure about Deep thinking can be found without the calculation of a great parameter. By integrating the relevant MOE route, 128K core training, and the integration of tools, the Baidu research team provides a model with financial reasons for the events.
Look The model in the kisses of face including Paper. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.



