Thinking Machines Lab Makes Tinker Commonly Available: Adds Kimi K2 Thinking and Qwen3-VL Vision Input

Thinking Machines Lab has moved its Tinker training API to general availability and added 3 major capabilities, Kimi K2 thinking model support, OpenAI-compatible sampling, and visualization with Qwen3-VL visual language models. For AI developers, this turns Tinker into an efficient way to fine-tune frontier models without building a distributed training infrastructure.
What Does Tinker Really Do?
Tinker is a training API that focuses on fine-tuning the language model and hides the heavy lifting of distributed training. You write a simple Python loop that runs on the machine's CPU only. Defines data or RL space, loss, and training logic. The Tinker service maps into a collection of GPUs and performs the exact computations it specifies.
The API exposes a small set of primitives, such as forward_backward calculating gradients, optim_step weight lifting, sample output generation, and save and load status functions. This keeps the training logic clear for people who want to use supervised learning, reinforced learning, or preference optimization, but don't want to handle GPU failures and scheduling.
Tinker uses low-level adaptation, LoRA, with full fine-tuning for all supported models. LoRA trains small adapter matrices over frozen basis weights, which reduces memory and enables running repeated tests on a large mixture of expert models in the same cluster.
General Availability and Considerations for Kimi K2
The main change in the December 2025 update is that Tinker no longer has a waiting list. Anyone can register, see the current model schedule and prices, and use the cookbook examples directly.
On the model side, users can now fine-tune moonshotai/Kimi-K2-Thinking to Tinker. Kimi K2 Thinking is a thinking model with 1 trillion parameters of a combination of architectural experts. Designed for long chains of thought and heavy tooling, it is currently the largest model in the Tinker catalog.
In the Tinker model system, Kimi K2 Thinking appears as a consulting MoE model, next to the dense Qwen3 and a mix of various experts, Llama-3 generation models, and DeepSeek-V3.1. Conceptual models always generate internal chains of thought before a physical response, while command models focus on grasping and direct response.
OpenAI Parallel Sampling While Training
Tinker already has a native sampling interface for its application SamplingClient. A common pattern of thought forms a ModelInput from token IDs, passes SamplingParamsand calls sample to find the future that settles in the output
The new release adds a second method that shows the OpenAI completion interface. A model checkpoint in Tinker can be referenced by a URI like this:
response = openai_client.completions.create(
model="tinker://0034d8c9-0a88-52a9-b2b7-bce7cb1e6fef:train:0/sampler_weights/000080",
prompt="The capital of France is",
max_tokens=20,
temperature=0.0,
stop=["n"],
)Installation Idea with Qwen3-VL on Tinker
The second major skill is photo editing. Tinker now exposes 2 Qwen3-VL vision language models, Qwen/Qwen3-VL-30B-A3B-Instruct again Qwen/Qwen3-VL-235B-A22B-Instruct. They are listed in Tinker models as Vision MoE models and are available to be trained and downloaded from the same API.
To send the image to the model, you build a ModelInput that enters i ImageChunk with passages of text. The research blog uses the following small example:
model_input = tinker.ModelInput(chunks=[
tinker.types.ImageChunk(data=image_data, format="png"),
tinker.types.EncodedTextChunk(tokens=tokenizer.encode("What is this?")),
])Here image_data raw bytes again format points to an encoding, for example png or jpeg. You can use the same representation for supervised learning and RL fine-tuning, which keeps multimodal pipelines consistent at the API level. Vision input is fully supported in Tinker's LoRA training setup.
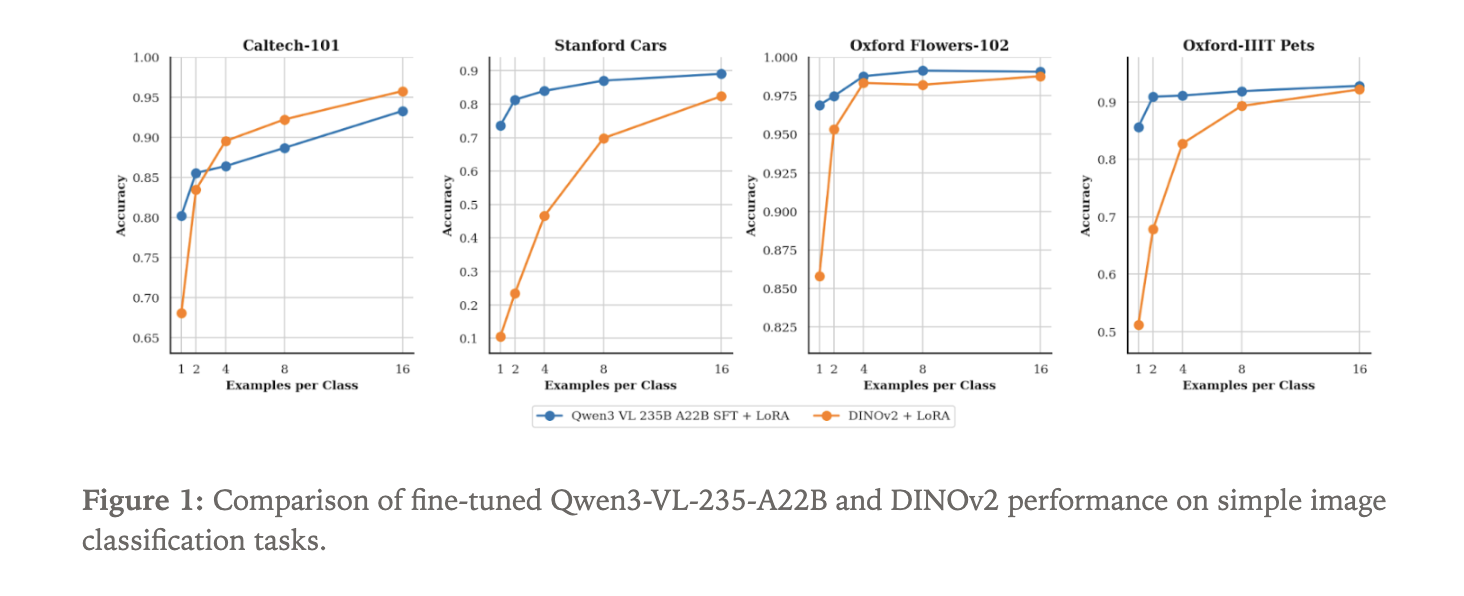
Qwen3-VL Versus DINOv2 in Image Segmentation
To show what a new way of thinking can do, the Tinker team performed well Qwen3-VL-235B-A22B-Instruct as an image separator. They used 4 common datasets:
- Caltech 101
- Stanford Cars
- Flowers of Oxford
- Pets of Oxford
Because Qwen3-VL is a language model with visual input, segmentation is framed as text generation. The model receives the image and generates the class name as a text sequence.
As a base, they fine tune the DINOv2 base model. DINOv2 is a self-supervised vision converter that converts images into embedded objects and is often used as the backbone of vision tasks. In this experiment, the classification head is superimposed on DINOv2 to predict the distribution of N labels in each dataset.
Both the base Qwen3-VL-235B-A22B-Instruct and DINOv2 are trained using LoRA adapters within Tinker. The focus is on data efficiency. The test sweeps a number of labeled samples per class, starting with only 1 sample per class and increasing. For each setting, the team measures the classification accuracy.
Key Takeaways
- Tinker is now generally available, so anyone can register and fine-tune open weight LLMs using a Python training loop while Tinker handles the distributed training backend.
- The platform supports Kimi K2 Thinking, a 1 trillion parameter combination of an expert thinking model from Moonshot AI, and exposes it as a readable thinking model in the Tinker program.
- Tinker adds an OpenAI-compatible interface, allowing you to sample training test points using
tinker://…URI model by using standard OpenAI style clients and tools. - Vision input is enabled on the Qwen3-VL, Qwen3-VL 30B and Qwen3-VL 235B models, so developers can build versatile training pipelines.
ImageChunktext input using the same LoRA-based API. - Machine Thinking shows that Qwen3-VL 235B, properly configured in Tinker, achieves stronger image classification performance than the DINOv2 baseline on datasets such as Caltech 101, Stanford Cars, Oxford Flowers, and Oxford Pets, highlighting the performance of large data models of visual language.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among viewers.




