NVIDIA AI Releases Orchestrator-8B: Enhanced learning controller for active tool learning and model selection

How can an AI system learn to choose the right model or tool for each task step instead of relying on a single model for everything? Nvidia investigators are released Toolurchestraa novel approach to train a small language model to act as an orchestrator- the 'brain' of a heterogeneous tool implementation agent
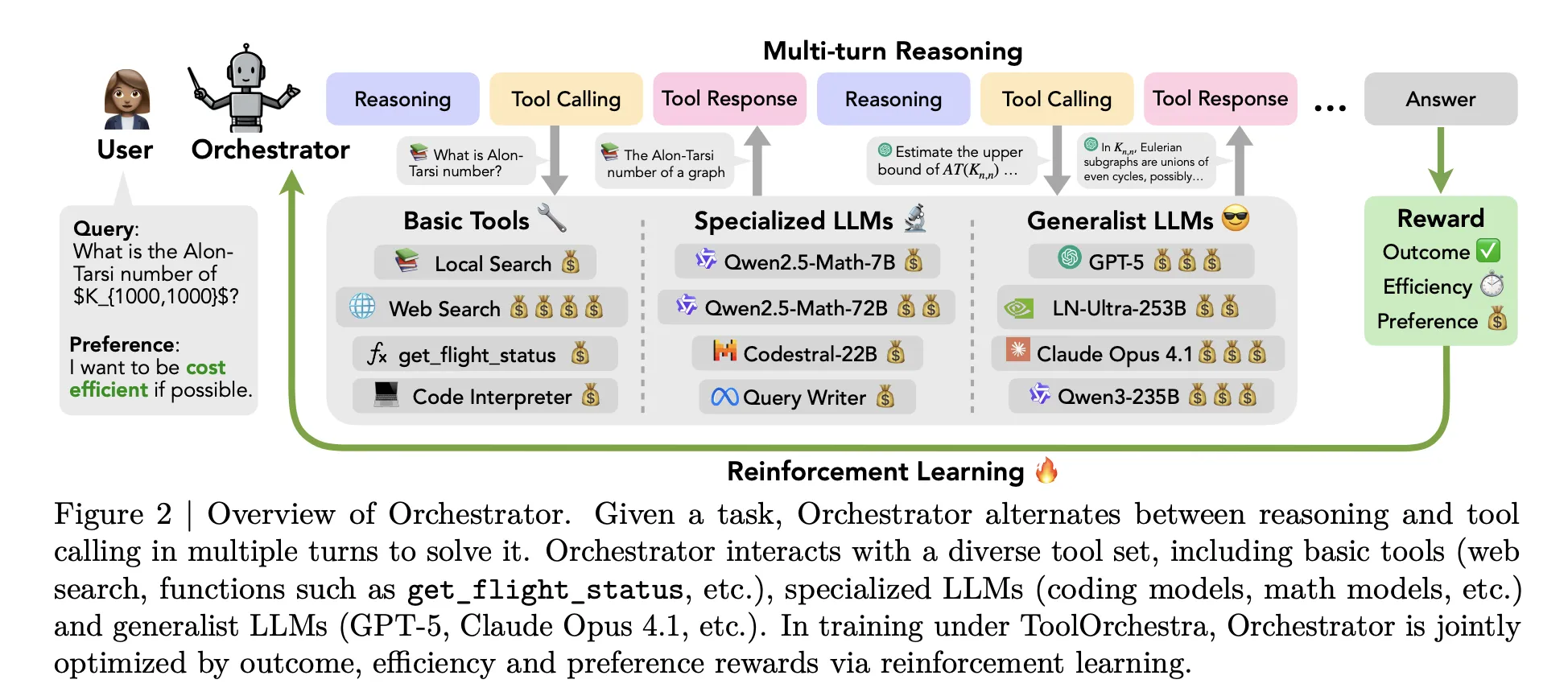
From single agent model to Policy Orchestration
Most agents out there follow a simple pattern. One big model like GPT-5 quickly finds out what defines the available tools, and then decides when to call a web search or a code translator. All higher-level thinking still resides within the same model. Toockerchestra changes this setting. It trains a model of dedicated donors called 'Orchestrator-8b', that treats old tools and other LLMs as interesting elements.
A pilot study in the same study shows why incoming rescue is not enough. When Qwen3-8B is asked to be followed among GPT-5, GPT-5 mini, Qwen3-32b and Qwen2.5-Coder-32B, it submits 73 percent of GPT-5 cases. When the GPT-5 works as its own Orchestrator, it calls the GPT-5 or GPT-5 mini in 98 percent of the cases. The research group calls this development and other developmental discrimination. The download policy uses robust models and ignores cost orders.
ToolOrchestra instead trains a sparse orchestrator for this routing problem, using reinforcement learning for full trajectories.
What is Orchestrator 8B?
Orchestrator-8b is a dynamic only 8b parameter decoder. It was built with a well-restored Qwen3-8B as an orchestration model and removed from the face sink.
During the computation, the program uses a multi-loop that alternates with reference calls and calls. Release than it Three Main Steps. – It's the headOrchestrator 8B reads user commands and description of natural language options, according to the request request to prioritize low latency or avoid web searches. – LekayoIt creates an internal chain of thought style and organizes action. -Threeselects an instrument from the available set and outputs a structured call in unified JONS format. Nature includes that call, interprets the result as a view and feeds it to the next step. The process stops when a termination signal is generated or 50 turns are reached.
Tool cover The top three teams. Basic tools include tavily web search, sandthon code interpreter for Python and local faiss index built with Qwen3-8B. Special LLMS includes Qwen2.5-Math-72B, Qwen2.5-Math-7b and Qwen2.5-Coder-32B. Generalist LLM tools include GPT-5, GPT-5 MINI, LLama 3.3-70B-I teach and Qwen3-32b. All tools share the same schema and names, natural language definitions and parameter settings.
End the end of the reinforcement of the reinforcement of the rewards of the objective
Toolurchestra construct the entire workflow as a Markov decision process. The state contains chat history, TO DRAY TORY calls and views, and user preferences. Actions are the next script step, including the communication tokens and the call schema of the tools. After up to 50 steps, the environment includes a scalar reward for the complete trajectory.
You have a reward three parts. Binary Results Reward and depends on the trajectory that solves the task. For open-ended responses, GPT-5 is used as a judge to compare the model output with the reference. Reward efficiency penalizes both capital costs and wall Cwoll latency. Token usage of open source tools is obtained from the cost of money using public API and AI pricing. The reward methods you like How Bad Tool Use is Corresponds to the User Choice Vector that can increase or decrease the weight for cost, specific tools or specific tools. These components are combined into a single scartar using a preference vector.
This policy is well implemented A policy-related group GRPO, a learning variant of a policy that adapts rewards to groups of trajectories of the same task. The training process includes a filter that casts trajectories with invalid call format or weak reward differences to reinforce efficiency.
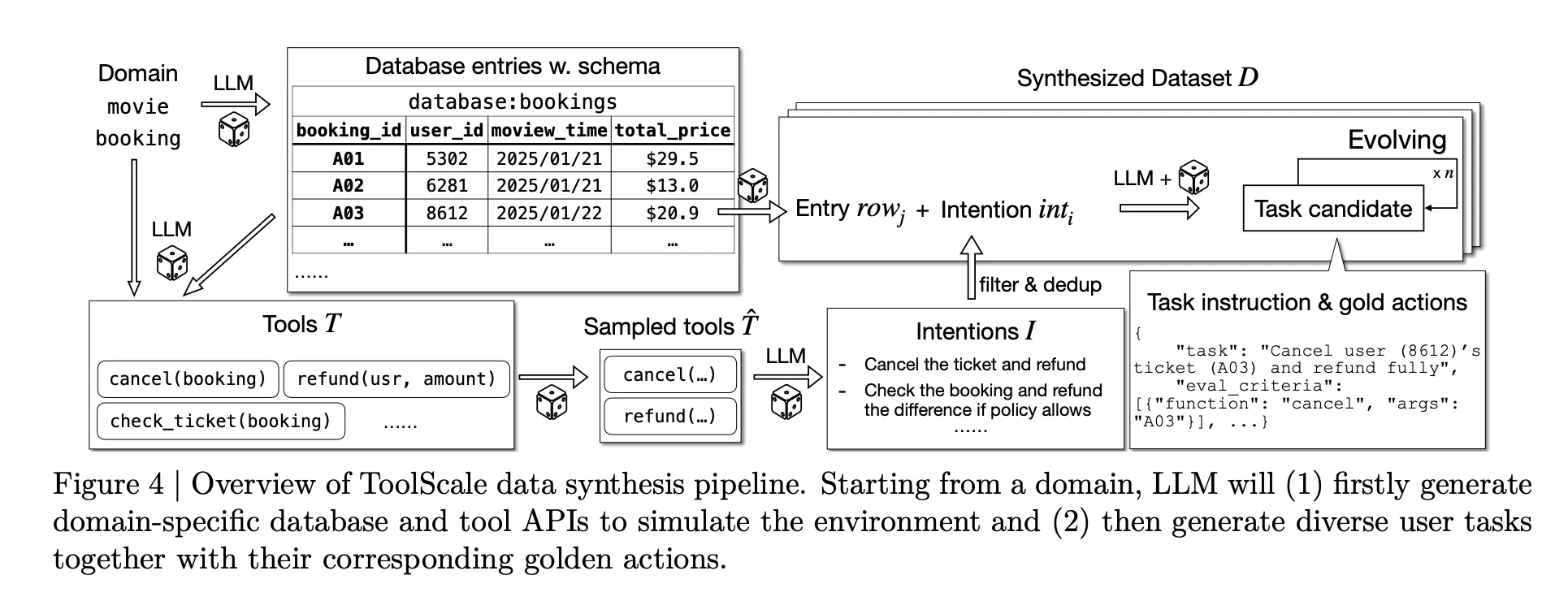
To make this training possible at scale, The The research group plans to introduce the toolssynthetic dataset for many driving tools. For each domain, LLM creates a data schema, data entries, domain-specific apis and various user functions with a realistic sequence of function calls and intermediate details.
Benchmark results and cost profile
Nvidia's Research Team is investigating Orchestrator-8b In three challenging benches, the final test is human, freestanding and bench. These benchmarks aim at long-term exposure, real-time under-recovery and dual-controlled performance.
In the final human text-only query, Orchestrator-8B achieves an accuracy of 37.1 percent. GPT-5 with basic tools reaches 35.1 percent in the same situation. In frames, Orchestrator-8b achieves 76.3 percent compared to 74.0 percent of GPT-5 with instruments. In venc on the bench, orchestrator-8b scores 80.2 percent compared to 77.7 percent of GPT-5 with basic tools.

The practical gap is huge. In the configuration using basic tools and LLM special tools, Orchestrator-8B has a cost of 9.2 cents and latex 8.2 meters In the same configuration, GPT-5 costs 30,2 cents and takes 19,8 minutes on average. The model card summarizes this with about 30 percent of the financial cost and 2,5 times faster Orchestrator-8b compared to GPT-5.
Analysis of the tools used supports this picture. Claude Opus 4.1 used as an Orchestrator for many GPT-5 calls. The GPT-5 used as an Orchestrator prefers the GPT-5 Mini. Orchestrator-8b distributes calls equally across solid models, cheap models, search, local retrieval and Code Conpter, and achieves high accuracy at low cost of the same budget.
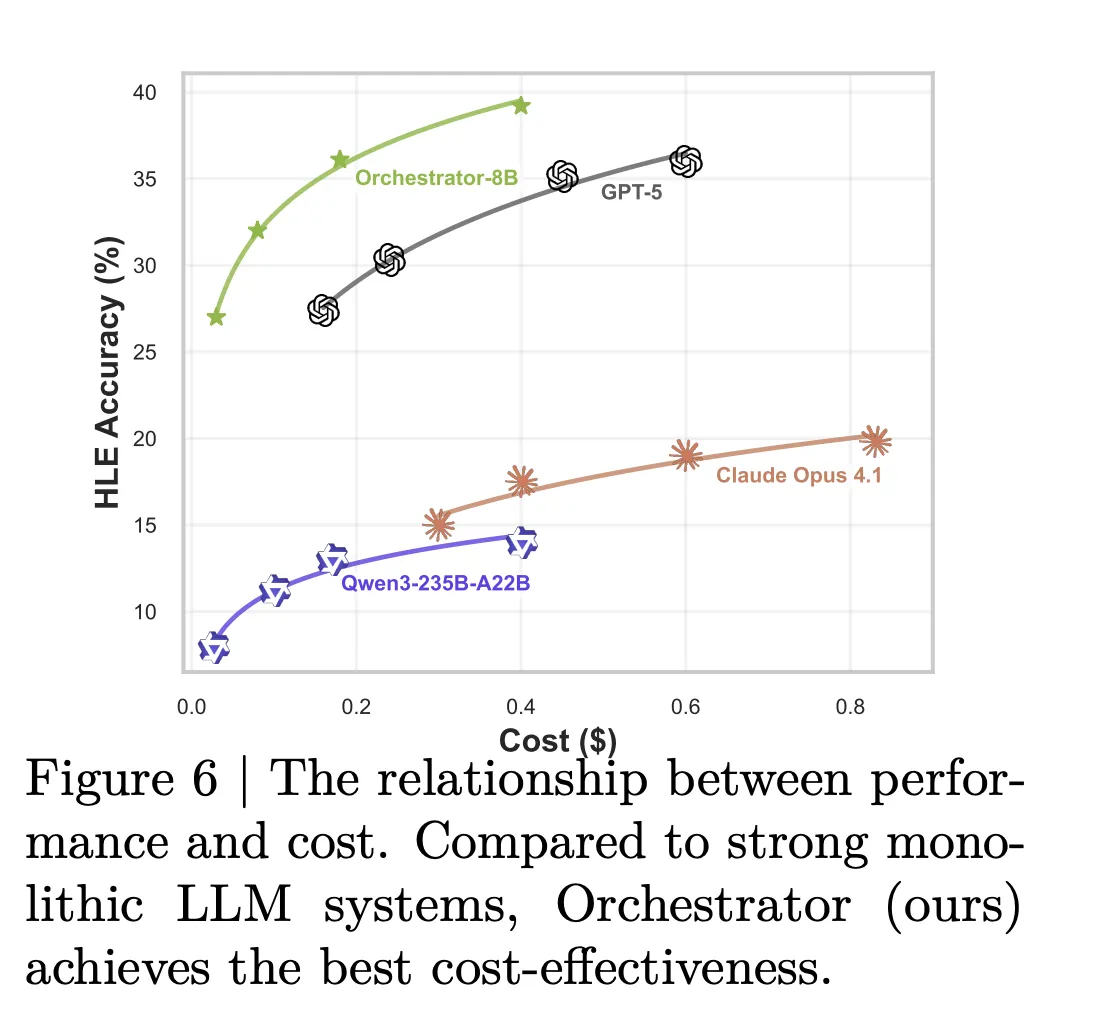
Standard tests take time to train tools with abstract models such as OpenMath LLMa-2-70b, Deepseek-Math-7B-stmbory, CodeSTRAL-22B-4.1 and Gemma-3-27b. Orchestrator-8B still finds the best trade-off between accuracy, cost and latency among all parameters in this configuration. A set of alternative selection tests show that Orchestrator-8B also tracks user tool usage options more closely than GPT-5, Claude Opus-4.1 and Qwen3-235b-A22b under the same reward metric.
Key acquisition
- ToolChestra trains an 8B parameter game model, Orchestrator-8B, which selects and tracks tools and LLMs to solve various agentic tasks using reinforcement learning with validation, efficiency.
- Orchestrator-8B is released as an open weight model on the binding surface. It is designed to connect various tools such as web search, code execution, retrieval and specialized llms with a unified schema.
- In the final human test, the Orchestrator-8B reaches an accuracy of 37.1 percent, surpassing 35.1 percent by 35.1 percent, while working with 2,5 on the bench and the GPT-5 exhausting frames while using about 30 percent of the cost.
- The framework shows that the naviving dynamics of the previous LLM as its router leads to the entertainment setting where it eats or a small set of strong models, while the trained orchestrator examiner learns the measurement policy, which is aware of many tools.
Editorial notes
Nvidia's ToolOrchestra is a practical step towards AI Compound systems where the 8B Orchestration model, Orchestrator-8B, learns an explicit routing policy over tools and LLMs instead of a single internal model. It shows clear gains in the final human, independent and bench tests that account for about 30 percent of the best negative cost over the best GPT-5 methods, making it directly compatible with teams that care about accuracy, latency and budget. This introduction makes policy orchestration the first optimization target in AI systems.
Look Paper, repo, project page and Model weight. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



