Agent0: A fully autonomous AI framework that generates highly efficient agents without external data through multiple evolutions

Large language models require large human datasets, so what happens if the model has to create its own curriculum and teach us how to use the tools? A group of researchers from UNC-Chapel Hill, Stanford Research University introduced 'Agent0', a completely autonomous framework that is expressed through multive-volulution toxic rel-evolution
Agent0 targets mathematical reasoning and general reasoning. It shows that careful work production and combined tooling can push a basic model beyond its original capacity, on all ten benches.
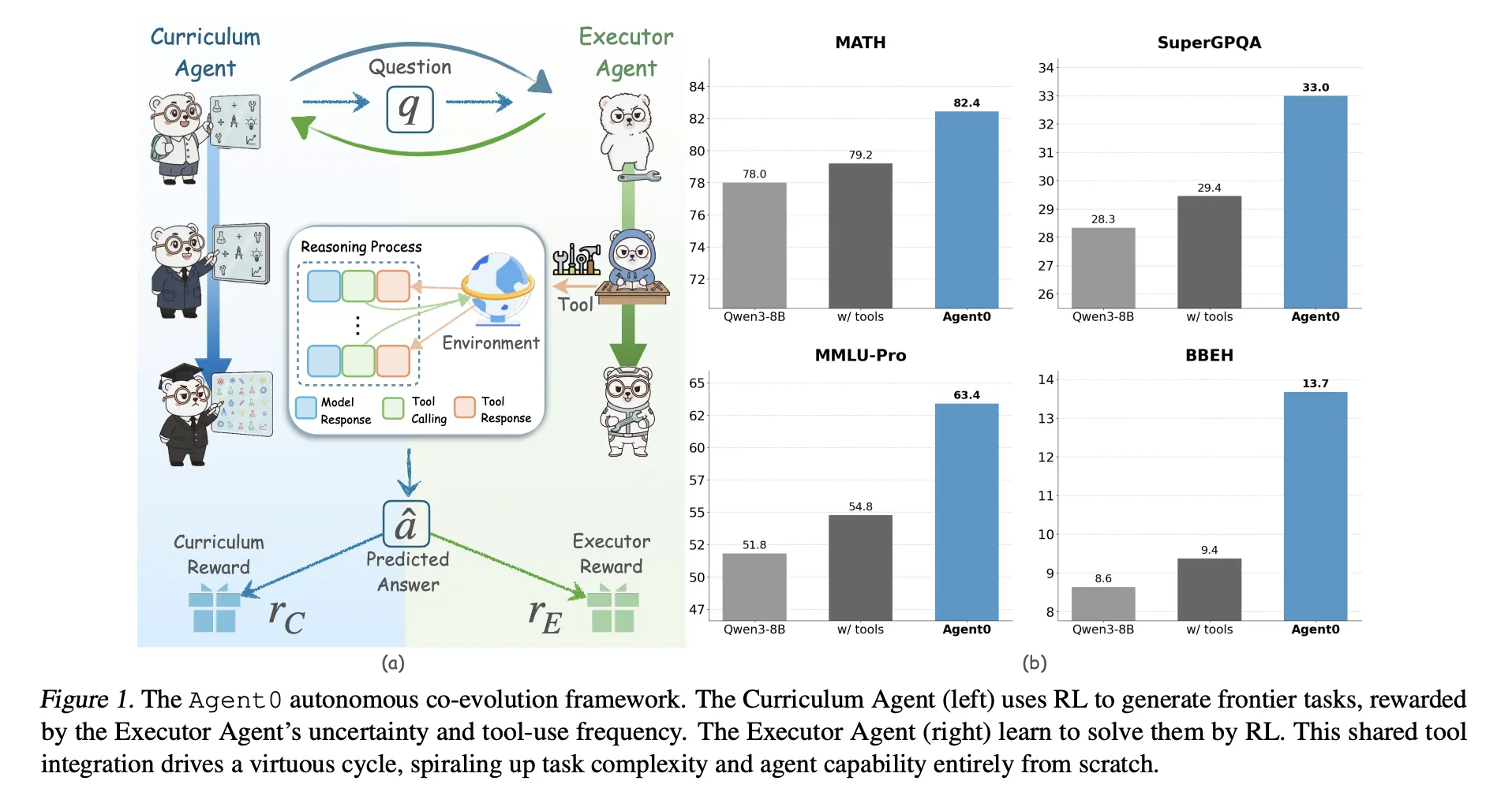
The two agents appear in one basic model
Agent0 starts from the base policy π_Base, for example Qwen3 4b base or QWEN3 8B Base. This policy applies to:
- a Curriculum agent Πθ operator,
- a Agent of Happiness Πφ which solves those functions with python tool.
Training proceeds in Iterations in two stages per iteration:
- Curriculum Evolution: The curriculum agent generates a batch of tasks. For each task, efator samples multiple responses. Compound reward methods can be sure that the executor, how often he uses the tool and how different the batch is. Πθ is updated with Policy related group (GrPO) using this reward.
- Exclul Evolution: The professional curriculum agent is frozen. It creates large job pools. Agent0 Filters this pool to keep only activities near the Exporter's Excetor boundary, and then trains the manager on these activities using the Ambiguity Aware RL intent Ambiguity Dynamic Policy Optimization (ADPO).
This loop creates a feedback loop. As the executor becomes more powerful through the interpreter of the Code, the curriculum must produce sharper, more stimulating problems for the tools to keep its reward high.

How Curriculum Agent Scores Jobs?
Curriculum reward includes three signals:
Uncertain reward: For each generated person x, MAmptor samples responses k and the majority votes for the pseudo response. Independence P (X) is the proportion of responses that agree with the majority. The reward is Maximal when p is close to 0.5 and less when the tasks are very easy or very difficult. This encourages challenging tasks but is still being solved by the current architect.
Tool Use reward: The executor can cause the sandbox code interpreter to use python Tags and you get results mark as output. Agent0 calculates the number of tools in the trajectory and provides a measured, bounded reward, with cap c set to 4 trials. This favors tasks that actually require tool calls rather than pure mental math.
Repetition Penalty: Within each batch curriculum, agent0 measures the word similarity between tasks using a Bleu-based distance. Jobs are clustered, and the penalty time increases with the size of the cluster. This brings the curriculum to a close double production.
The composite reward multiplies the format check with an uncertainty-weighted value and the reward tool removes the multiplicity penalty. This is a composite value feed to grpo to update Πθ.
How EBLUCER learns from noisy labels?
The executor is trained for GRPO but with Multi Train, a combined tool of trajectories and pseudo labels instead of the real truth.
Construction of the Frontier Dataset: After the training of the curriculum in iteration, the frozen curriculum forms a large pool of selection. For each task, the agent0 combines the constant p (x) with the collaborator and keeps the tasks only when p lies where in the Phies that are fed, for example between 0.3 and 0.8. This defines a challenging dataset that protects against unbounded or impossible problems.
An integrated tool: For each external function, the constructor generates a trajectory that can be linked:
- Natural Language Reasoning Tokens,
pythoncode sections,outputFeedback tool.
Generation matuases when the tools appear, extract the code from the sandpreter it is bound to Verl tooland restart the result. The trajectory ends when the model generates the final internal response {boxed ...} Tags.
The majority of votes across sample trajectories define the pseudo label and terminal reward for each trajectory.
AdPO, ambiguity does not know rl: The standard GRPO treats all samples equally, which is not stable when the labels appear by majority voting on the positive functions. AdPO modifies GRPO in two ways using signal ambiguity.
- It measures average profit by a factor that increases with confidence, so trajectories from low-confidence jobs contribute less.
- It sets the maximum possible pressure by observing the ratio of importance, according to the subject. Intelligence analysis shows that the fixed upper limit affects the tokens with lower probability. Adpo relaxes this decoration by default, which improves testing on uncertain tasks, as shown by up tokens opportunities Mathematics.

It results in mathematical and general reasoning
Agent0 is created over Besekheki and tested Qwen3 4b base and QWEN3 8B Base. It uses the integrated sandthon interpreter as a single external tool.
The research team examines on ten benches:
- Mathematical Reasoning: AMC, Minerva, Math, GSM8K, Olimpiad Bench, AIESE24, AIESE25.
- General Consultation: SupergQa, MMLU Pro, BBEH.
They report Pass @ 1 for multiple datasets and say @ 32 for AMC and AIME functions.
It's simple QWEN3 8B Baseagent0 accesses:
- Math average 58.2 compared to 49.2 for the base model,
- The overall average is 42.1 Compared to 34.5 for the base model.
Agent0 also develops robust databases such as R zero, Absolutely zero, – Love each other and Socratic zeroboth with and without tools. In Qwen3 8b, it exceeds ur zero by 6.4% and absolute zeroes by 10.6 points in the general average. It also strikes a socratic zero, which relies on external aurai apeis.
Across three Evolution Iterations, the average math performance on the Qwen3 8B increases from 55.1 to 58.2 and the average consultation also improves with each iteration. This proves a steady improvement rather than a fall.
Relevant examples show that the curriculum activities range from basic geometry questions to complex problem-satisfaction problems, while Bluel Trajectories includes a script for consulting Python calls to access the correct answers.
Key acquisition
- Complete counce database: Agent0 completes external information and personal attributes. The two agents, the curriculum agent and the agent manager, are launched from the same LLM base and modified only by the reinforcement tool and the Python tool.
- An earlier curriculum from uncertainty validation: Curriculum agent uses excetor consistency and tool usage to score. It learns to produce previously meaningless or impossible tasks, and that clearly requires an integrated consulting tool.
- AdPO reinforces RL with pseudo-labels: The executor is trained in effective policy making. Adpo Down Weight Busy Activities and adjust the range of washing based on behavior, making GRPO style stable when rewards appear in many places of pseudo votes.
- Consistent benefits to nations and common sense: In QWEN3 8B Base, agent0 improves the statistical benchmarks from 49.2 to 58.2 average and the general consultation from 34.5 to 42.1, which corresponds to insects with 18 percent.
- Outperform's Outromform data structures: At the moment ten benches, agent0 surpasses the previous emerging methods such as r zero, absolutely zero, wind and social, including those that already use external tools or apis. This shows that the CO Evolution Plus Design of the instrument cluster is a logical step beyond the capabilities of the surrounding environment.
Editorial notes
Agent0 is a key step in active learning, free reinforcement data for the Integrated Tool. It shows that the foundation of LLM can work as both a curriculum agent and an agent agent, and that grpo with ADPO and the Verl Tool can drive a stable development from many pseudo-labels. This method also shows that the integrated tool of CO Evolution can make zero-zero data structures such as R zero and completely zero in qwen3 removed. Agent0 makes a strong case that an emergent, integrated LLM tool becomes a logical training paradigm.
Look Paper and repo. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.

Michal Sutter is a data scientist with a Master of Science in Data Science from the University of PADOVA. With a strong foundation in statistical analysis, machine learning, and data engineering, Mikhali excels at turning complex data into actionable findings.
Follow Marktechpost: Add us as a favorite source on Google.



