
If neural networks are now making decisions everywhere from coders to security organizations, how can we actually see the specific circuits within each behavior? Opelai has launched a new research tool that trains language models to use internal wiring, so that the model's behavior can be described using small, discrete circuits.
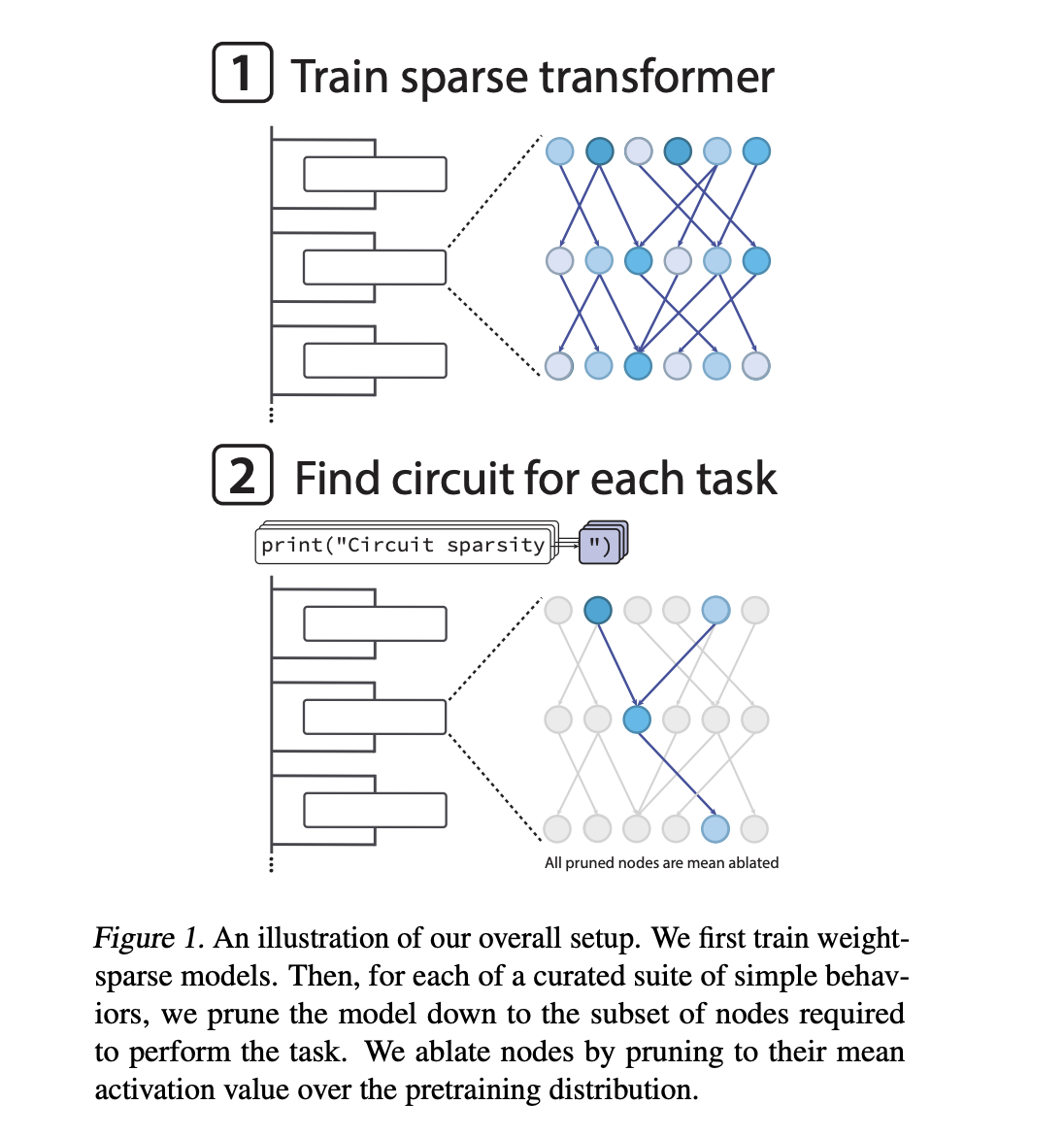
Training of converts to be sparse
The models of many dynamic languages are dark. Each neuron learns from and writes many of the remaining channels, and the characteristics are often benign. This makes circuit level analysis difficult. Previous OpenAi work attempted to learn sparse feature bases over dense models using sparse encoders. The new research work changes the basic model so that the transformer itself has weight.
The Opelai Team trains decoders only for transformers that come from a design similar to GPT 2. After each step of the optimizer with Adarw Optimizer, it emphasizes the Adarw Optimized ratio for all weight matrices and selections, including embedding tokens. The largest entry in each matrix is stored. Everything else is set to zero. Through training, the invocation program gradually drives the proportion of non-zero parameters down until the model reaches its target point.
In the most extreme case, about 1 in 1000 metals are non-zero. Activation is also somewhat visible. About 1 in 4 work is zero in a typical local area. The effective communication graph is very compact even if the model range is large. This encourages the collapsed elements to map cleanly to the remaining cheeks of the circuit.
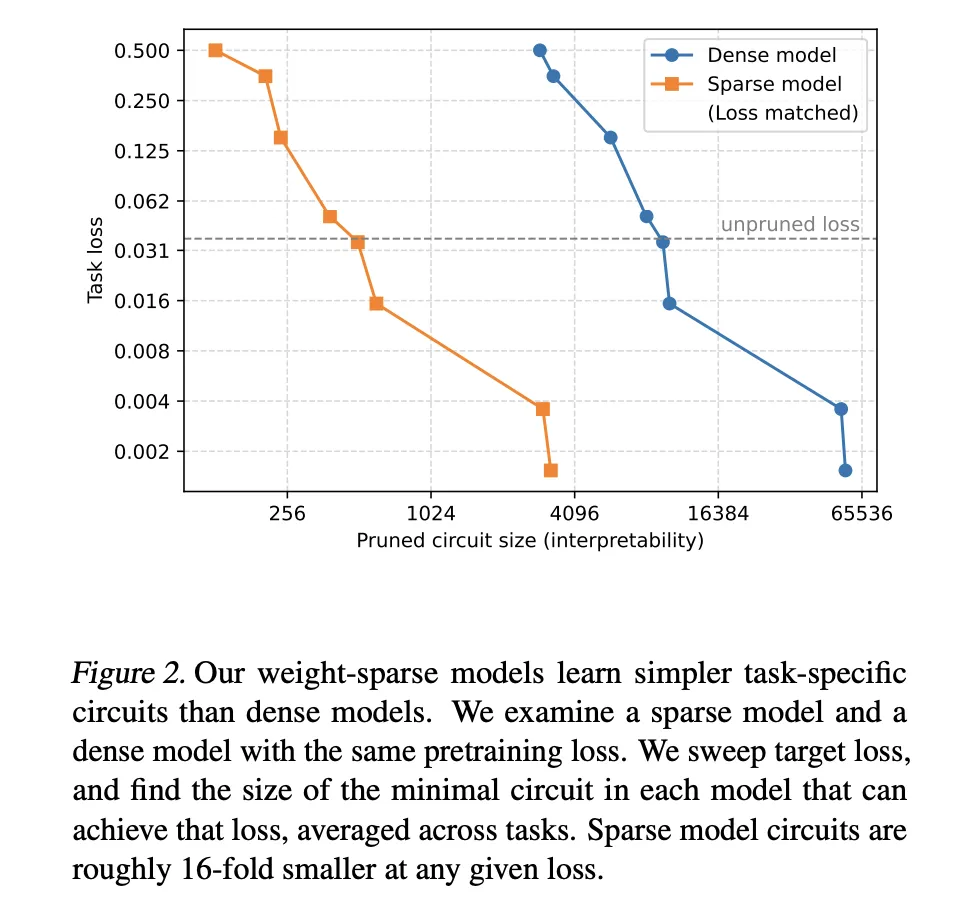
Evaluating the interpretation of the specific pruning of the work
In order to make these models easy to understand, the Vulai team does not rely on relevant examples alone. The research group describes a Suite of simple algorithmic functions based on Python for the following Token. One example, one_date_quote, requires a model to close a python string with the appropriate quote character. Another example, set_r_string, requires the model to choose between .Add and + = Based on whether the variable was initialized as a set or a string.
For each job, they want the smallest job, called a cycle, that can still do the job up to the planned loss limit. Trees are node-based. A node is an mlp neuron in a particular layer, an attention head, or a broadcast channel left in a particular segment. When a node is searched, its performance is replaced by the mean with the uncertainty distribution. This means destruction.
The search uses constant mask parameters for each style gate and style gate, configured directly by measuring as a surrogared. Regional hardness is measured as the number of active edges between the stored areas. The main metric for describing the geometric intsget that is calculated for all functions.
For example circuits in sparse transformers
In the single_double_quote function, the space models yield a clear and fully dynamic cycle. Beside the first MLP, a single neuron behaves as a quote acteriction detector on both single and double quotes. The second neuron behaves like a Quote type that separates these two types of measure. Later, the attention head uses these signals to return to the opening state of the measure and copy its form to the closing state.
In terms of the Circuit Graph, the method uses 5 remaining channels, 2 MLP Neurons in urer 0, and the attention head over time with one channel of the right key and one value channel. If the whole model is boiled down, this subsection still solves the task. If these few edges are removed, the model fails to function. Therefore, the cycle is therefore sufficient and necessary for the practical experience described by the paper.

For more complex methods, such as following the type of variable named internally within the body of the function, circuits are restored that are larger and partially understandable. The research group shows an example where the name of attention is put in that variable in Token Set () in the definition, and another operation of this soon copies the information of the type from that which is used later. This displays a small region graph.
Key acquisition
- Weight-sparse transformers by design: Open GPT-2 Transformers style trains so that almost all zeros are zero, more than 1 in 1000 are not zeros, forcing the tokens to embed which is easy to analyze.
- Translation is measured as the smallest circulation size: The function defines a set of simple Python functions that follow the following functions and, for each function, the search made by the smallest edges between the cleaning points, which still works with the purchase of the node level with the Estimator style of activation.
- Consesete circuits appear, they appear completely: In tasks such as predicting the same characters of the Quote, the sparse model presents a compact circuit with a few remaining channels, 2 key MLP Neurons and the attention head can fully engineer and verify as necessary.
- Sparsity brings very small circles with organized energy: For pre-training loss rates, weight space models require circuits 16 times smaller than those found in dense foundations, which explains more where the low power rises.
Opelai's work on Weight Sparse Transformers is a pragmatic step in making resource translation work. By enforcing sparsity directly in the basic model, the paper transforms the background discussions into concrete graphs with measurable parameters, clarity of need and needs assessment, and productive benchmarks in Python following Python functions. The models are small and inefficient, but a suitable method for future security audits and fraudulent travel. This study treats interpretation as a first-class design problem rather than a reality check.
Look Paper, github repo and Technical details. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.

Michal Sutter is a data scientist with a Master of Science in Data Science from the University of PADOVA. With a strong foundation in statistical analysis, machine learning, and data engineering, Mikhali excels at turning complex data into actionable findings.
Follow Marktechpost: Add us as a favorite source on Google.



