StepFun AI releases Step-Audio-HIDX: A 3B LLM-grade open source programming model for dynamic and immersive audio editing

Can speech editing be as straightforward and manageable as simply rewriting a line of text? StepFun AI is open Step-Audio-audio-edidex, a 3B parameter llm model based on audio based on the arrangement of prominent expressions in the token-level text as a function, instead of a waveform signal processing function.
Why developers care about TTS controls?
Many ZERO Shot TTS programs Copy emotion, style, accent, and timbre directly from short audio. They may sound natural, but the control is weak. Style moves literary help only to background words, and the combined word often ignores the requested feelings or style of speech.
Previous work tries to eliminate features with added acpods, missing weapons, or complex structures. Step-Audio-HIDX preserves the highly causal presentation and instead transforms the data and the training objective. The model learns to control by seeing pairs and triplets where the text is arranged, but another attribute changes by a large margin.
Architecture, dual codebook tokenizer plus compact Audio LLM
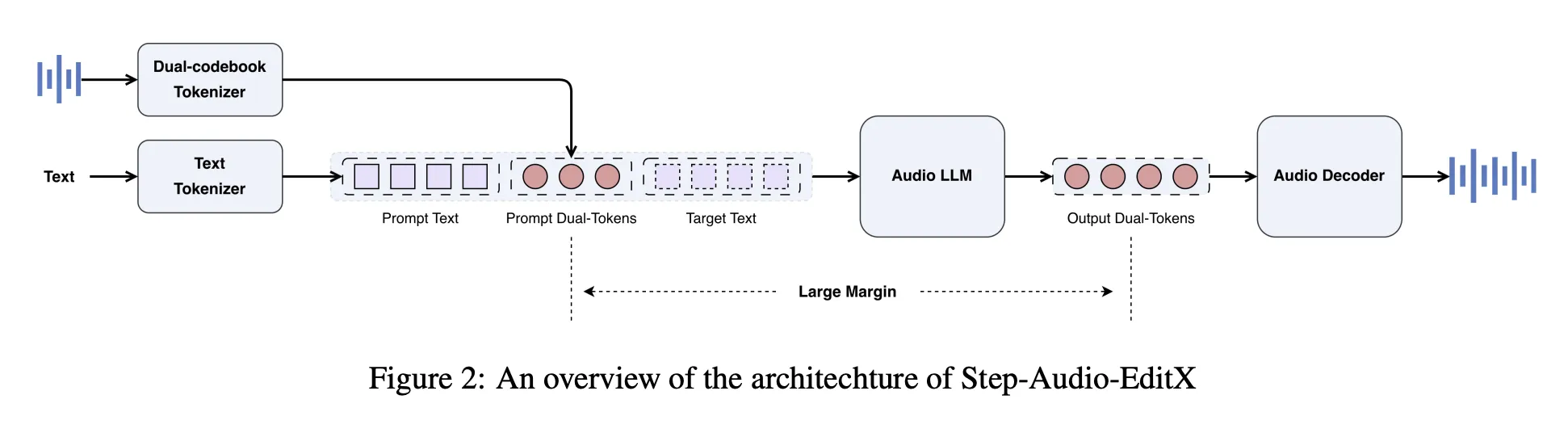
Step-Audio-Reduce includes step-audio toxenizer. Speech is encoded into two token streams, a linguistic stream at 16.7 Hz with a 1024-entry codebook, and a semantic stream at 25 hz with a 4096-by-4096-entry codebook. The combined tokens average 2 to 3. Tokenizer preserves prosody and emotion information, so it is not completely disabled.
On top of this toonizer, the Stepkelefun research team developed the 3B Parameter Audio LLM. The model is initialized from LLM text, then trained on a combined corpus with a 1 to 1 ratio of plain text and Dount Codebook audio tokens to conversational styles. The audio LLM reads text tokens, audio tokens, or both, and always produces multiple audio codebook audio tokens as output.
A separate audio decoder behaves differently. A deffized transformer modulation module based on mel spectrograms from audio tokens, reference Audio, and dynamic speaker, and bigVganv2 vocoder transforms mel spectrograms to waveform. The flow simulation module has been trained for approximately 200000 hours of high-level speech, improving pronunciation and timbre uniformity.
Large artificial margin data instead of complex encoders
The main idea is the large margin study. The post model is trained in triplets and quadruplets that keep the text organized and change only one attribute with a clear gap.
For Zero Shot TTS, Step-Audio-Hlitx uses a high-quality in-house database, mainly Chinese and English, with a small amount of Cantonese and Sichuanese, and 60000 speakers. The data includes extensive intra-speaker and inter-speaker variation in style and emotion. (ARXIV)
In order to organize the style and speech, the group created martenitic martigins (text, neutral emotions, sound, or sound style). The voice actors recorded about 10 second clips for each emotion and style. StepTTTTTTS ZERO SUST Cloning Then it produces neutral and emotional versions of the same text as the speaker. A Margin scoring model, trained on a subset of assigned individual, mailings on a scale of 1 to 10, and only samples with a Score of at least 6 are retained.
The compact editing, covering breathing, laughter, candlelight and other tags, uses an advanced processing strategy from the NVSpeech Dataset. The research group created quadruplets where the target is formal NVSpeech listening and writing, and the input is a combined version with tags removed from the text. This gives time to plan the domain without the margin model.
Reinforcement learning data uses two sources of interest. Annotators are updated 20 staff are qualified on a 5-point scale for accuracy, visibility, and nature, and two with a line greater than 3 are retained. The cognitive model detects emotions and speech style on a scale of 1 to 10, and two with a line greater than 8 are retained.
Post training, SFT PLUS PPO on token tracking
Post training has two stages, Good direction followed by A type of carton.
between Good directionprogram stimulation explains ZERO STATE TTS and programming functions in an integrated conversational format. In TTS, the instantaneous waveform is encoded into two codebook tokens, converted to string form, and programmed into the speaker information prompt as speaker information. The users message is the target text, and the model returns new audio tokens. To edit, the user's message includes real audio tokens and natural language commands, as well as special effects programmed tokens.
Emphasis on Learning then ensures subsequent learning. The 3B reward model is derived from the SFT test and trained for the loss of Bradley Terry in the Dear Mars Offer. The reward is calculated directly from the Dual Codebook Token sequence, without translating the waveform. PPO training uses this reward model, the clip limit, and the KL penalty to measure quality and deviation from the SFT policy.
Step-audio-editing-test, existing and general editing
In order to reduce the control, the research team presents an audio-audio editing test. It uses the Gemini 2.5 Pro as an LLM as a judge of emotion, speaking style and accuracy. The Benchmark has 8 speakers, drawn from Wenet4tt, Globe V2, and 4 Light, with 4 speakers per language.
Emove Set has 5 sections with 50 Chinese and English emotes. The speech style set has 7 styles with a maximum of 50 per language per style. The portable setup has 10 labels such as breath, laugh, surprise oh, and Uhm, with 50 peaks per label.
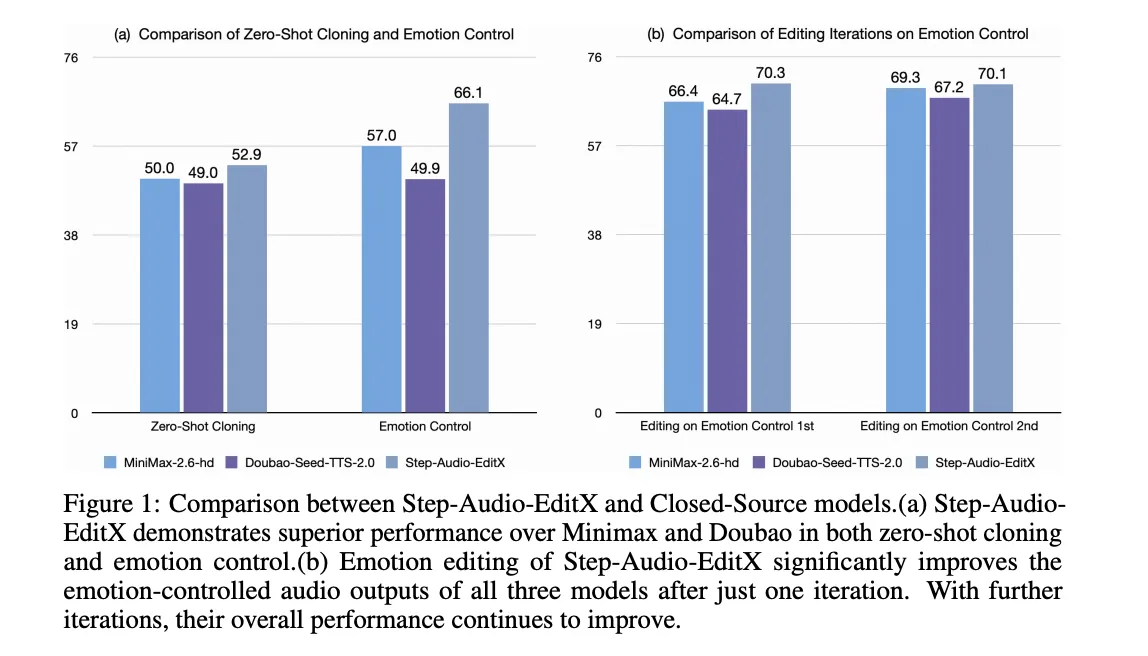
Planning is tested iteratively. Iteration 0 is the Inisticbo Shot Clone. After that the model runs 3 cycles of programming with text commands. For Chinese, emotion accuracy increases from 57.0 in Iteration 0 to 77.7 in Iteration 3. Stylistic expression increases from 41.6 to 69.2. English shows the same behavior, with a fast update, where the same sound is used in all iterations, it still improves the accuracy, which supports the large margin hypothesis.

The same programming model is used in four closed programs of TTS Systems, GPT 4O MINI TTS, velenlabs v2, Doubao seed TTS 2.0, and MiniMax Speech 2.6 HD. For all of them, one iteration programmed with step-audio-ediodx improves the feeling and accuracy of the style, and some progressive elements continue to help.
The most difficult arrangement is scored on a scale of 1 to 3. The average rating increases from 1.91 in iTenation 0 to 2.89 after one editing, both in Chinese and English, compared to the traditional integration of strong marketing programs.

Key acquisition
- Step Audio Download TOKENIZER TOKENIZER TOKENIZER TOKENIZER with 3B parameter Audio LLM so it can treat speech as direct toys and organize sound with text like a way like a way like a way.
- The model relies on big data for emotion, speech style, directions, speed, and sound, rather than adding additional encoders.
- Fine tuning and PPO with Token Level Reward Model adapts audio LLM to follow natural language programming commands for both TTS and programming tasks.
- Step by Step Editing Benchmark Tenckmark with Gemini 2.5 Pro as the judge shows clear accuracy that gets clear accuracy above 3 editing for emotional editing, style, and physical control in Chinese and English.
- The audio editor can process and improve speech from Screen Source TTS Systems, and the full stack, including code and Checkpoints, is available as open source for developers.
The sound editing step is a direct step forward in the evaluation of available speech, because it maintains a compact audio tokizer, and adds control of large margin and PPO data. The introduction of the step-by-step planning process with Gemini 2.5 Pro as a judge makes it possible to show the story of concrete by concrete, to talk about style and release, and the open release lowers the barrier of the active study of sound planning. Overall, this release makes audio editing feel much closer to text editing.
Look Paper, repo and Model weight. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



