Liquid Ai Releases LFM2-Colbert-350m: A small new model that brings a long overdue return to the multilingual and high-quality Rag

Is the compact late intambalu to retrieve the index and bring accurate cross search with fast submission? ICIM AI released LFM2-COLBERTETTH-350Mlate interaction to retrieve multilingual search and skip. Documents can be displayed in one language, queries can be written in multiple languages, and the system returns with high accuracy. The Liquid AI team reports infence speed in par play with 2.3 times smaller models, called the LFM2 Backbone. The model is available with a demo of the leaf face and a detailed model card for the integration of the systems to retrieve the systems of the optimal level.
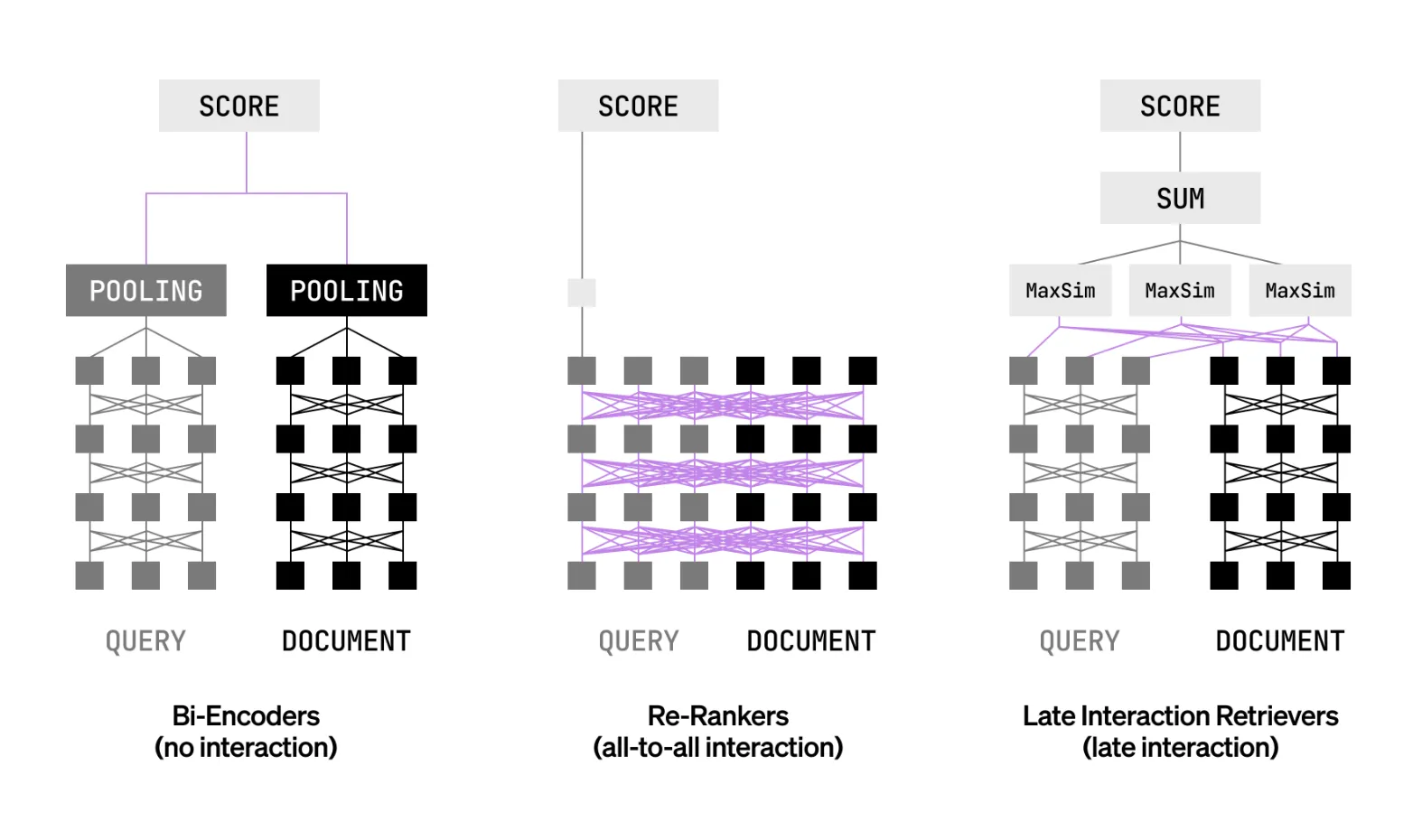
Late arrival communication means why it's important?
Most production systems use bi-encoders for speed or cross encoders for accuracy. Late communication aims to combine both benefits. Questions and texts are entered separately at the token level. The program compares token vevers during a query using Maxsim-like functions. This ends up aggregating tokens without the full cost of aggregating attention. It allows for early integration of documents and improves accuracy on time. It can serve as the first stage of recovery and just like the previous guide.
Model specifications
LFM2-Colbert-350m has 350 million parameters. There are 25 layers, with 18 blocks, 6 blocks, and 1 more layer. The context length is 32k tokens. The size of the dictionary is 65 536. The similarity function is Maxsim. Maximum output is 128. Training specification is BF16. The license is the lfm v1.0 open license.

Languages, supported and tested
The model supports 8 languages. These are English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish. The test adds Italian and Portuguese, bringing the matrix in 9 languages for document comparison and query languages. This classification is applicable when the planning is to cover certain customer markets.
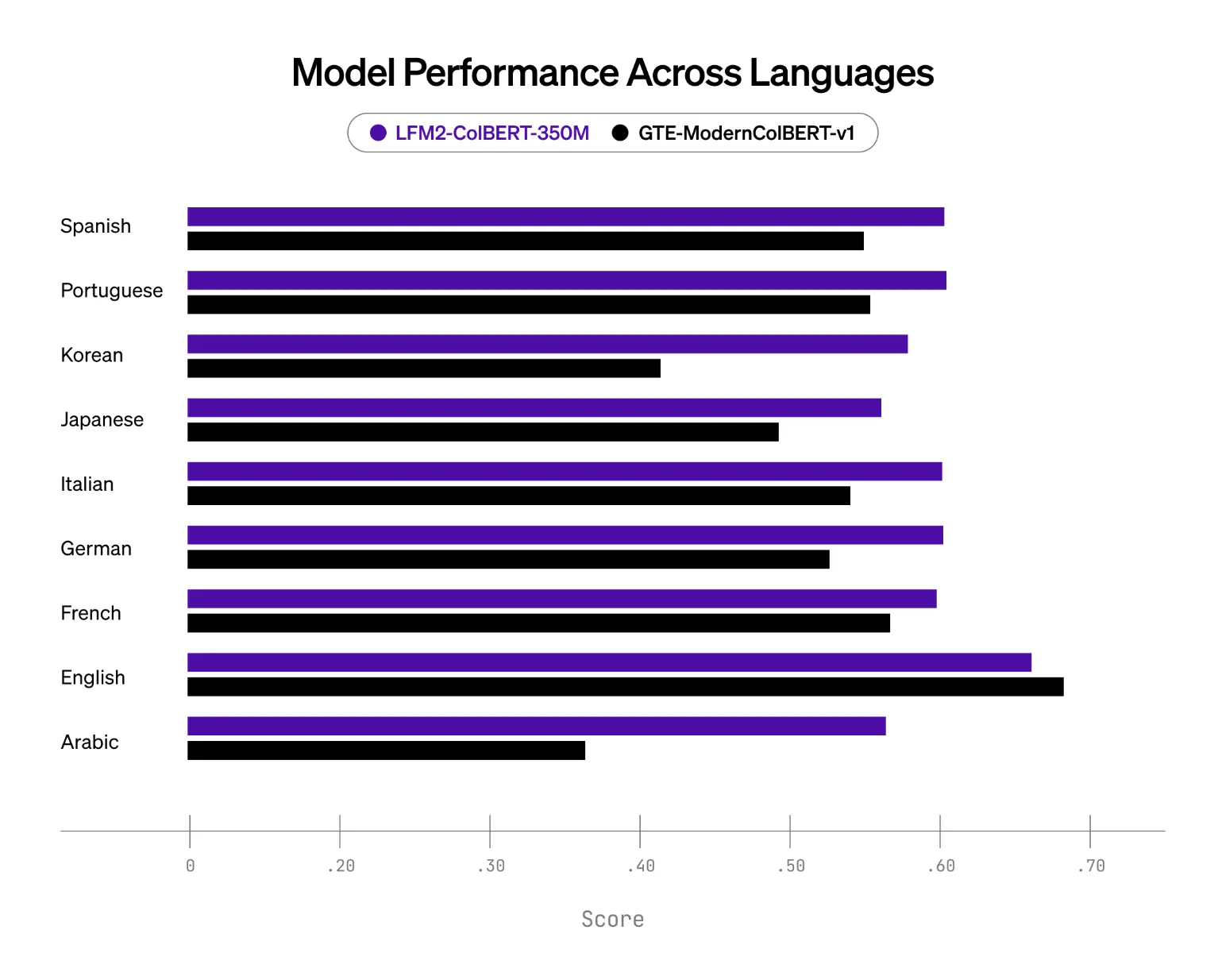
Test setup and key results
IIDID AI is expanding the NanobeIR brand in Japanese and Korean and publishing an extension for further fulfillment. In this setup, the LFM2-COLBERTETH-350m shows stronger multilingual capabilities than the late interactive model in this class, which is the Gte-ModernColbert-V1 on the 150m parameters. The biggest gains come from German, Arabic, Korean, and Japanese, while English performance is maintained.
Key acquisition
- Token-Level points with Maxsim have preserved cold interactions while maintaining unique vendors, so document embedding can appear and query properly.
- Documents can be displayed in one language and found in many. The model card lists 8 languages supported, while testing SPAN with 9 languages for cross-languages.
- In the hands of many languages of NanobeIR, LFM2-COLBERTER-350M suffered the Baseline of the previous Intere -naction (Gte-ModernColbert-V1 at 150m) and maintains English performance.
- Infence speed is reported on par with models 2.3 × smaller for all batch sizes, called LFM2 Backbone.
Editorial notes
Liquid Ai's LFM2-Colbert-350M implements the late Corbert application with maxsim, embeds queries and documents separately, then embeds Token Level vectors and enables level input wording. It aims for multilingual retrieval and cross-time retrieval of languages, index and query in multiple languages, with tests described in the NanobeIR multilingual extension. The Liquid AI TEAM reports benchmark speed at par with 2.3 models and 2 sacrifices. Overall, the late collaboration in the Nano period seems to be produced by the production of many rag trials.
Look Model instruments, demo and Technical details. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.
 -Training written by LLMs for any AI agent")


