Zibuu Ai Releases 'Glyph': An AI framework for measuring context length by compressing visual text

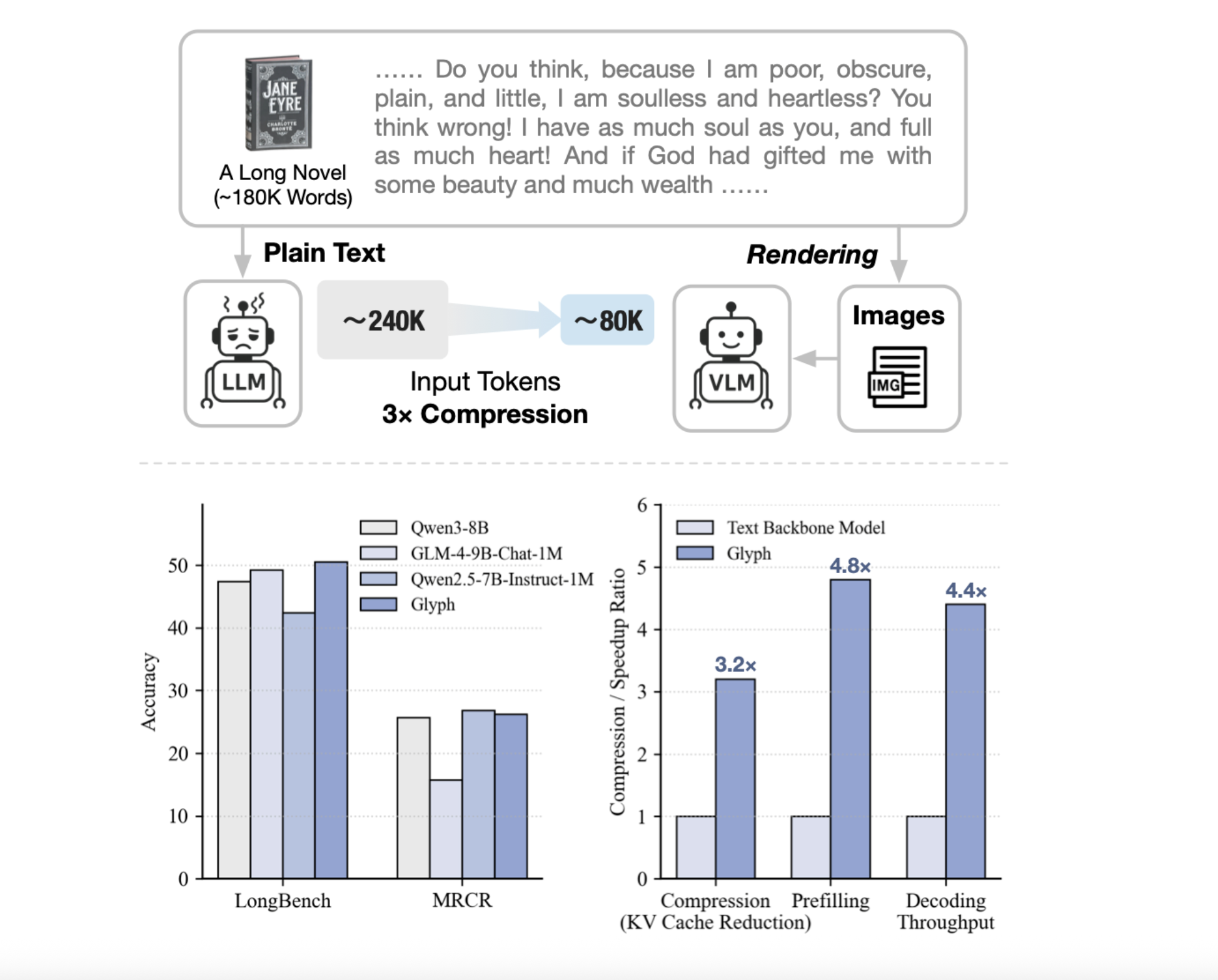
Can we render long texts as images and use VLM to achieve 3-4 x compression A group of investigators from Zibuu Ai Depent Glyphan AI framework for measuring context length with visual text compression. It renders long written sequences into images and processes them using visual language models. The system renders Ultra long text on page images, and then a visual language model, VLM, processes those pages end to end. Each virtual token contains multiple characters, so the effective reduction of the token, while the semantics is preserved. Glyph can achieve 3-4x compression tokens for long text sequences without performance degradation, enabling significant gains in memory efficiency, training load, and entertainment speed.
Why Glyph?
Common methods include re-entering information or changing attention, compute and memory scaling and token counting. Retrieving Trims Installation Trims, but they risk missing evidence and add latency. Glyph transforms the presentation, converts text to images and burns the load to VLM which is already learning OCR, layout, and consultation. This increases the quantitative information per token, so the fixed token budget includes the actual context. Under extreme pressure, the research team shows the 128k context state of the VLM can cope with operations from Token Level 1m text.
Design and training
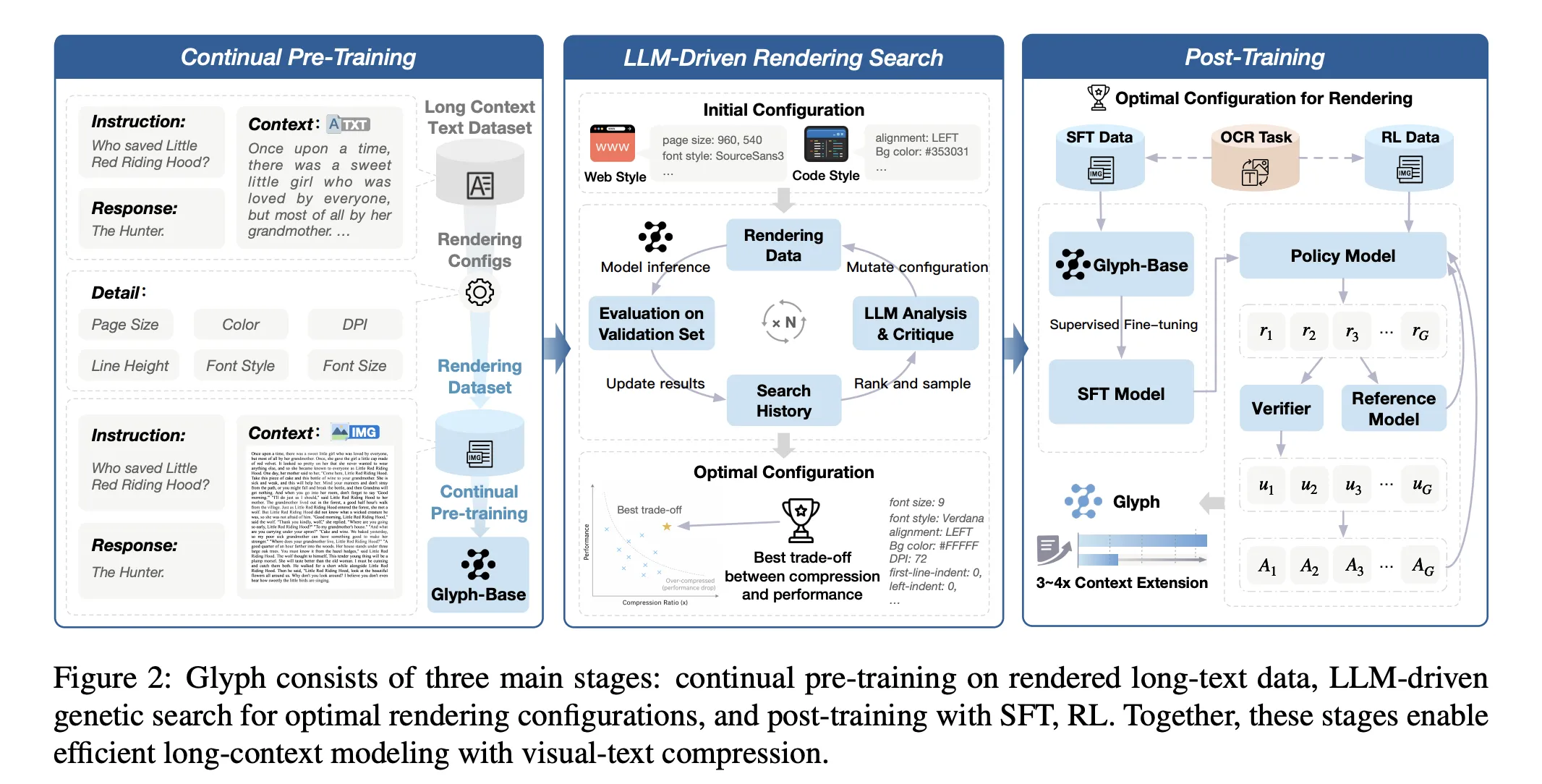
The method consists of three stages, pre-training and continuing training, and post-training. Continuous prior training exposes the VLM to the large organization of Corporac Purpose that adapts to visual and textual presentations, and transfers long mono skills from text tokens to visual tokens. The search offered is genetics driven by the LLM. Changes page size, DPI, font family, font size, line height, alignment, indents, and spacing. It evaluates candidates with validation set to maximize accuracy and minimize collaboration. Post training is used to guide the learning and reinforcement of the policy of the policy, and the alignment function of AUXILISINE. Lossy OCR improves character fidelity when fonts are small and spacing is tight.
Results, performance and efficiency…
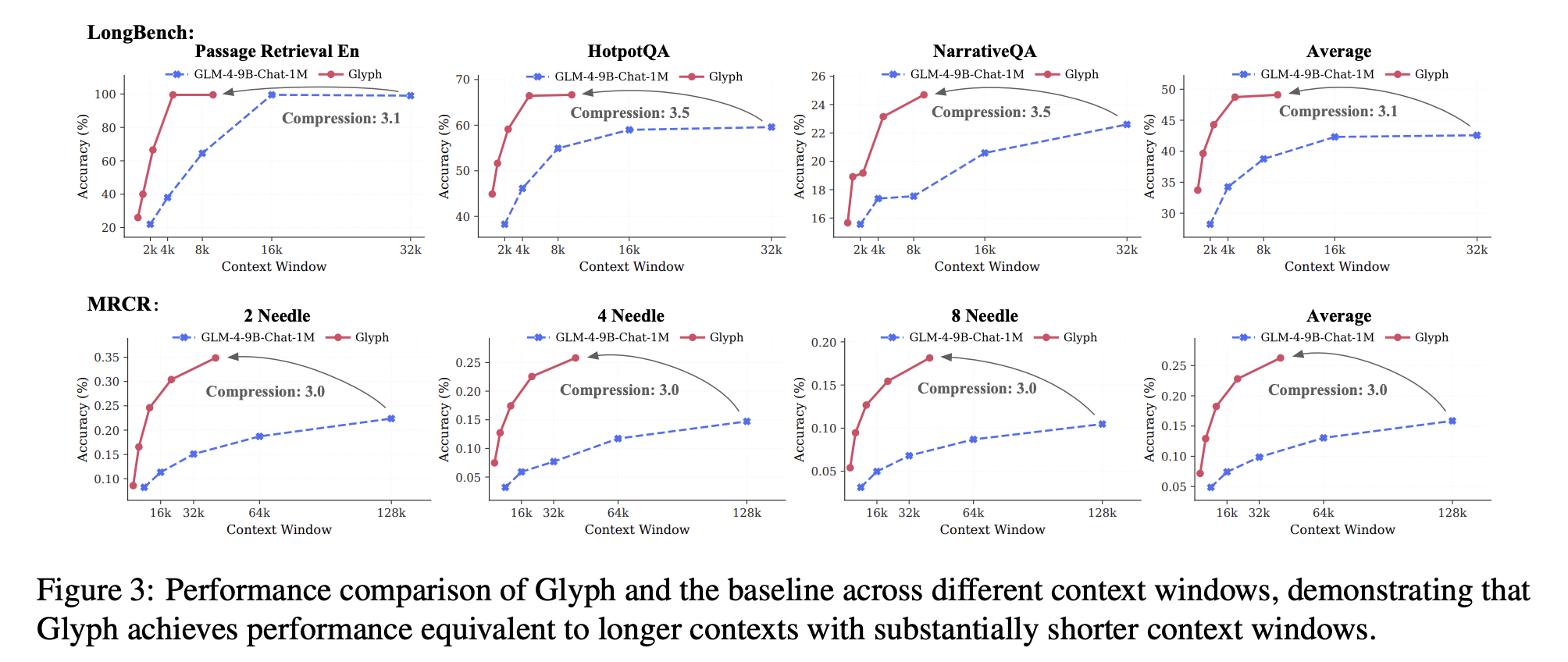
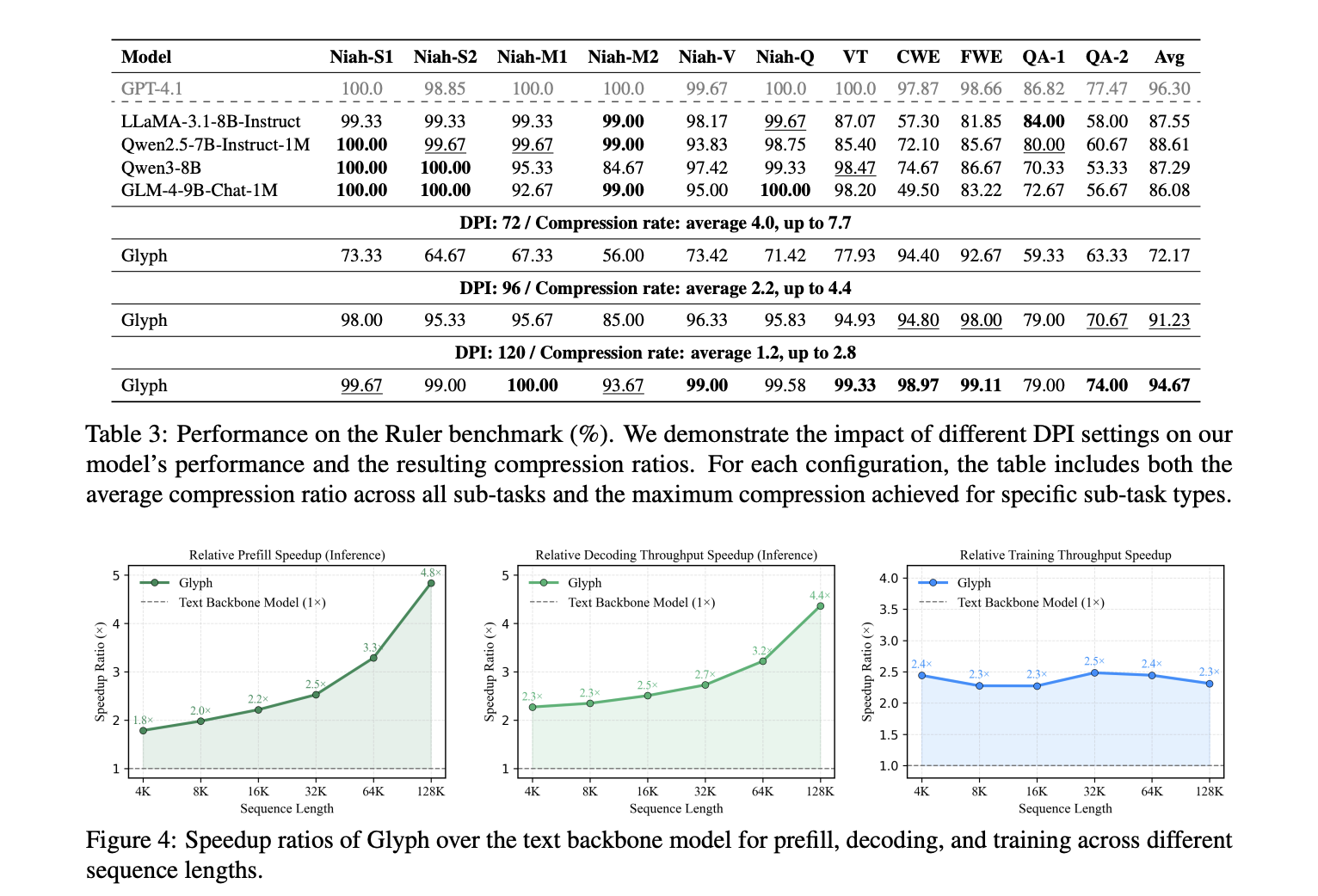
Longbench and MRCR for accuracy and compression under long-discussion history and document functions. The model achieves a quick rate of active pressure of about 3.3 on the longbench, with some activities close to 5, and about 3.0 on the mrcra. This achieves a long input scaling, because every virtual token carries multiple characters. SpeedSUPS reported compared to text input at 128k input 4.8 times 4.8 times, about 4 times fine print. Governor Benchmark confirms that a higher DPI during measurement improves scores, because crisper glyphs help OCR and layout parsing. The research team reports DPI 72 with an average compression of 4.0 and 7.7 for some tasks below, DPI 96 with an average compression of 2.2 and 4.4, and DPI 120 with an aund of 1,2 and an average of 2.8. The highest value of 7.7 is for the governor, not for Mr.
Now? Dogs
Glyph advantage is multimodal understanding. Training on translated pages improves performance in Mmongbench Doc relative to the underlying visual model. This shows that the purpose is to provide a basic material for real document operations involving calculations and structure. The main failure mode is sensitivity to aggressive typing. Very small fonts and strong spacing to reduce character, especially rare alphanumeric strings. The research group does not include the UUID subtask in the controller. The approach assumes Server Side Rendering and VLM with robust OCR properties and layout priors.
Key acquisition
- Glyph renders long texts into images, and then a visual language model processes those pages. This emphasizes the long model as a multimodal problem and preserves semantics while reducing tokens.
- The Research Team reports that Token Compression has 3 to 4 times the accuracy compared to 8B text bases that are tight on 8B benchmarks.
- The initial speed is about 4,8 times, the Decoding SpeedUp is about 4,4 times, and the fine tuning of the fine editing is 2 times, measured at 128k input.
- The system uses continuous time on the translated pages, genetic search llm which is updated over the parameters, and then monitors the fine-tuning and strengthening of the GRPO objective, and the alignment objective of the OCR.
- The analysis includes longbench, Mr, and Governor, with the worst case showing the 128k state of context of the VLM talking about the 1m Token Level activities. The code and model card are public on GitHub and you kiss the face.
Glyph treats long content cold as visual text compression, puts long sequences into images and allows VLM to process them, reducing tokens while preserving semantics. The research team claims 3 to 4 Comp Compression with accuracy comparable to Qwen3 8B Baselines, about 4 times faster compression and compression, and about 2 times faster SFT. The pipeline is ordered, the previous training continues on the translated pages, the genetic LLM that offers entrance fees over typing, then the post training. The method is pragmatic for million token workloads under extreme pressure, however it relies on OCR selection and typing, which is always a headache. Overall, virtual text compression provides a concrete way to scale long content while managing compute and memory.
Look Paper, instruments and repo. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.
 -Training written by LLMs for any AI agent")


