Meta Ai Executive Investigaters: TransformMer T-End-END construction directly redirected, metric 3D area of geometry event

A group of researchers from Meta Reality Labs and Carnegie Mellon University has been ordered EMPANYTHINGThe construction of transformer to-wall structures repeatedly oppose the metric 3D scene in the geometry condition from photos and optimization of the will. Issued under the apache 2.0 with full training and a measuring code, the Mapalanything Development without specialist pipelines by supporting the unique 3D operation in one 3D Passage.

Why is the universal model of renewal 3D?
The 3D rebuilding is based on cracked pipes while working effectively, these modular solutions need workplace order, efficiency, and more performance.
The latest models of the Dust3R, Mast3r, and simplified VGG components, are restricted: Organized Design Deferrals, or Fidelines associated with integrated representation.
Mapaything defeats these issues by:
- To accept until 2,000 photographs to install in one passage.
- For customization using the use data such as Camera Intrilsics, goals, and depth maps.
- Generation Metric 3D Construction of Metric without a pile adjustment.
Representation of Model model – the depth of Ray, is due, and the Global Scale Factor – provides conditions and increase made in front.
Properties and representation
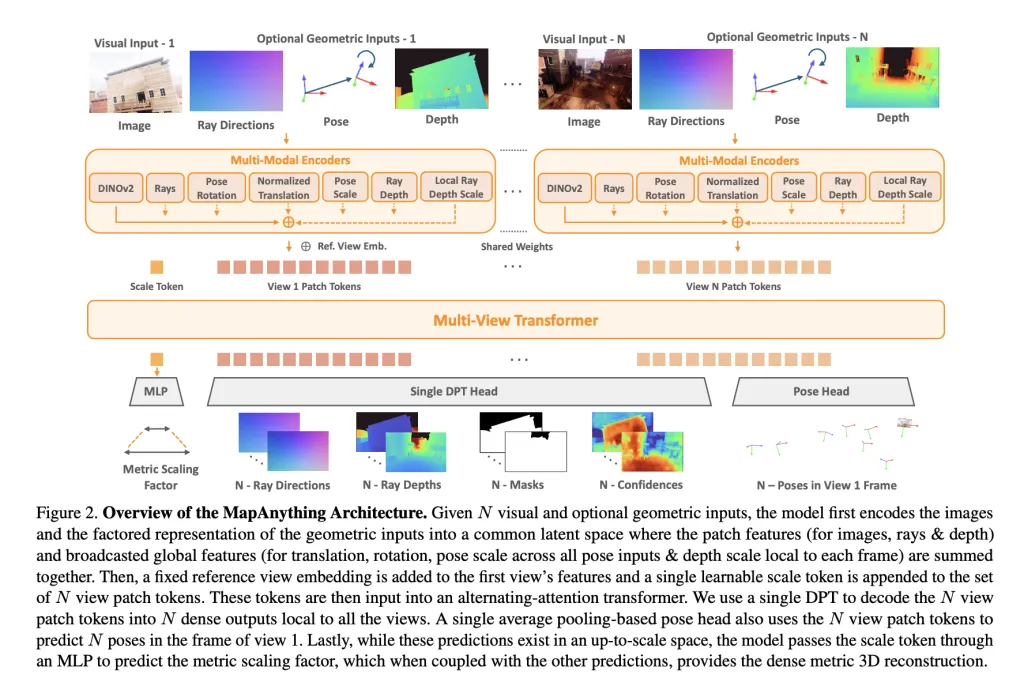
In its spine, the Mapanything uses a More views – looking for transformer modification. Each installation picture is included Dinov2 vit-l Features, while the preferred input (radiation, depth, letters) are included in the same CNS space or MLPS. A The readable quote token It enables metric orders all views.
Network outgoing a Proper representation:
- A complete view Ray Directions (Camera estimate).
- DepthHe predicted the top-to-scale.
- Camera Pose related to reference view.
- One Metric Scale Factor Converting local rebuilding into a dragonfly.
This visible factorication avoids return, which allows the same model to manage the intense monocar estimate, various stereo-from-movement (SFM), or to end depth without special heads.
Training Strategy
The Mapaything was trained across 13 Different details Internal, external, external backgrounds, including BlendedMVvers, Paltaneral PlanNantry depth, and tartanairv2 depth. Different two are issued:
- Apache 2.0 License A trained model in six dattasets.
- CC model is NC Training in all thirteen details are powerful functionality.
Important training strategies include:
- Input of the submission of the reverse: During training, geometric input, pose, pose) is provided with various opportunities, making the energy of feeding of heterogeneous configuration.
- Sample based on finding: Ensuring logical views there is logical, reorganization until 100+ views.
- The proper loss of in space: Depth, measurement, and pose is done properly using the loss of stimulating and strong to improve stability.
Training is done 64 H200 GPUS With a mixed accuracy, gradient editing, and curriculum planning, measuring from 4 to 24 inclusion views.
Results of measuring measurement
More critical sensitive views
In Eth3D, scannet + v2, along with TartanioIirv2-WB, the mapanything reaches State-of-The-Art (Sota) status Working in Pointmaps, Depth, Pose, and Ray Equity. It passes the basics such as vggt and pow3r even if they are limited to photos only, and promotes continuation or prose.
For example:
- Pointmap related error (REL) It also improves 0.16 with pictures only, compared to 0,20 with VGGT.
- With pictures + intrinscus + the frogs + the depth, the mistake is 0.01While achieving> 90% Inlier Ratios.
Two reconstruction
By opposing Dust3r, Mast3r, and Pow3r, Imapanonything consists of consistent spray, depth, and accuracy. Vividly, with additional priors, up to > 92% Inlier Ratios In two views, much more than previous hospitality models.
One viewing control
Despite special training is a single picture repair, the mapanything reaches an Anchar Anchar's average of 1.18 °Outgoing Anycalib (2.01 °) and MOGE-2 (1.95 °).
Deep estimate
For Robust-MVD cheeks:
- Mapannything sets new sota of The depth of many metrics estimate.
- With auxiliary installation, its Error prevents the rival or exceeds special depth models such as MVSA and Metric3D V2.
Overall, benchmarks confirm 2 × developments in previous Sota For many functions, it guarantees the benefits of united training.
Important Contributions
The research team highlights four donations:
- Unifed Feed-Fords model It can handle more than 12 problems, from the depth of monocar to SFM and stereo.
- Illustrating represents a place It enables clear radiation separation, depth, pose, and metric ratings.
- The performance of the state of the country Across different benchmarkets with fewer refundancies and higher stiffness.
- An open source removal Including data processing, training texts, benches, and beautiful metals under Apache 2.0.
Store
The Mapalanything establishes a new Benchmark vision by combining many rebuilding projects – SFM, stereo, depth, and comparison – under one model of the relevant transformation. It is not only special ideas practices that are only in royal practices but also agree with the heterogeneous installation, including intrinsics, pose, and depth. With open source code, beautiful models, and more than 12 jobs, Imapanonynthing sets the spinal core of 3D regular rebuilding.
Look Paper, codes and project page. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.

Michal Sutter is a Master of Science for Science in Data Science from the University of Padova. On the basis of a solid mathematical, machine-study, and data engineering, Excerels in transforming complex information from effective access.
🔥[Recommended Read] NVIDIA AI Open-Spaces Vipe (Video Video Engine): A Powerful and Powerful Tool to Enter the 3D Reference for 3D for Spatial Ai



