Yakha izinhlelo zokusebenza zokusakaza ngezwi ngesikhathi sangempela nge-Amazon Nova Sonic ne-WebRTC

Ukwakha izinhlelo zokusebenza zokusakaza bukhoma kusukela ekupheleni nokusetshenziswa kwezwi ngesikhathi sangempela kuveza izinselele ezimbalwa: izithiyo zomkhawulokudonsa wenethiwekhi zingabangela ukubambezeleka okuphezulu kanye nokuwohloka kwekhwalithi ezinhlelweni ezibucayi zesikhathi. Izithiyo zolimi zikhawulela ukusebenzisana okuphumelelayo komshini womuntu ekuxhumaneni kwezwi ngezilimi eziningi. Ukuqina nokuqina kudinga ibhalansi enzima phakathi kokusebenza nezindleko zengqalasizinda. I-Cross-browser kanye nokuhambisana kweselula kudinga umzamo omkhulu wokuthuthukisa, ikakhulukazi kwabaqalayo.
Lokhu okuthunyelwe kwethula isisombululo esisekelwe ku-Amazon Nova 2 Sonic (Nova Sonic) kanye ne-Amazon Kinesis Video Streams WebRTC (WebRTC) esibhekana nalezi zinselele. I-WebRTC inesibopho sokulungisa i-bitrate ngokuguquguqukayo kumanethiwekhi angazinzile, esiza ukugcina ikhwalithi yomsindo ngenkathi yehlisa ukuxhumeka okwehlayo. I-Nova Sonic inikeza izingxoxo ezisebenzayo zolimi lwabantu, ukuze abasebenzisi bakwazi ukuxhumana ngokwemvelo ngolimi abalukhethile. Zombili lezi zinsizakalo ziphethwe ngokugcwele yi-AWS, ngakho-ke zikala ngokuzenzakalelayo ngokuqina okuphezulu. I-AWS futhi ihlinzeka ngamasampula omthombo ovulekile ongawasebenzisa njengesiqalo sohlelo lwakho lokusebenza.
Kulokhu okuthunyelwe, sizohamba ngesakhiwo sesixazululo, amaphethini wokuqalisa, kanye nezibonelo ezimbili zesimo somhlaba wangempela.
I-Nova Sonic ne-WebRTC
Amapayipi omenzeli wezwi wezwi ngokuvamile afaka amamojula ahlukene okuqaphela inkulumo, ukucutshungulwa kolimi, nokuhlanganisa inkulumo. I-Nova Sonic inikeza ukwakheka okuhlanganisiwe kwenkulumo-kuya-inkulumo okuvumela izingxoxo zezwi zesikhathi sangempela phakathi kwabasebenzisi nama-ejenti e-AI anokubambezeleka okuphansi.
Ngokuqonda kwenkulumo okuhlanganisiwe nesizukulwane, i-Nova Sonic iletha i-AI yengxoxo yemvelo, efana neyomuntu. Imodeli ye-Nova Sonic inikeza izitayela zokukhuluma ezahlukene kanye nokuxhumana kwamathuluzi kwabasebenzeli bangaphandle. Ungayisebenzisa ukuze wakhe isixhumi esibonakalayo sezwi esiphendulayo nesinembile ngokuqwashisa okuphezulu komongo.
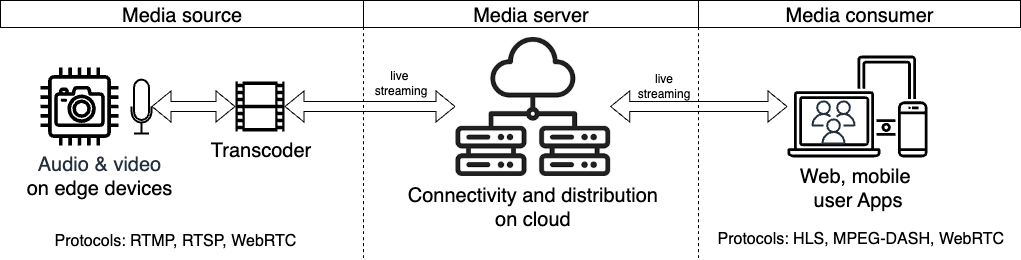
Ipayipi elivamile lokusakaza lihlanganisa izingxenye ezintathu eziyinhloko: umthombo wemidiya, iseva yemidiya, kanye nomthengi wemidiya. Umdwebo odlule ubonisa lezi zingxenye kanye nemithetho elandelwayo ngokulandelana kwazo, njenge-RTMP, RTSP, HLS, MPEG-DASH, ne-WebRTC.
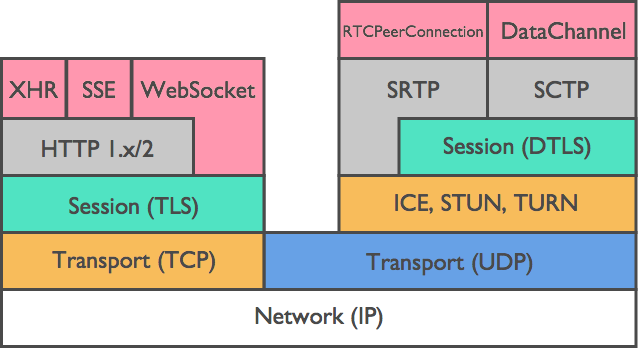
I-Web Real-Time Communication (WebRTC) iyiphrothokholi esesidlangalaleni eyenza ukusakaza bukhoma kube kusimanje ngokunikeza ukuxhumana okuqondile kwesikhathi sangempela kontanga ngaphandle kwama-plugin engeziwe noma ukufakwa kwesofthiwe. Le ndlela iqeda isidingo samaseva aphakathi futhi inciphisa kakhulu ukubambezeleka. Phakathi kwawo wonke amaphrothokholi okusakaza abezindaba, i-WebRTC iletha ukubambezeleka okuphansi kakhulu, njengoba kukhonjisiwe esithombeni esilandelayo.

I-WebRTC iphinda ihlanganise nezici ezakhelwe ngaphakathi ezifana nokusakaza-bukhoma kwe-bitrate eguquguqukayo (ABR), ukulungiswa kwephutha eliya phambili (i-FEC), nokuphathwa kwebhafa ye-jitter. Lezi zici zingalungisa ngokuzenzakalelayo ukusetshenziswa komkhawulokudonsa, futhi zixazulule ukulahlekelwa kwephakethe noma izinkinga ze-jitter ekuxhumekeni okubuthakathaka. Ungagcina izingxoxo ezishelelayo ngisho nasezimeni zenethiwekhi ezimbi.
Imvelo yomthombo ovulekile ye-WebRTC nokuhambisana kwesiphequluli esibanzi (i-Chrome, i-Firefox, i-Safari, i-Edge, i-Android, i-iOS, njll.) izosheshisa ukwamukelwa kwesixazululo futhi ikhuthaze ukuthuthuka okuqhubekayo. Futhi ifaneleka kahle ekucutshungulweni kwesikhathi sangempela kokusakaza kwemidiya ngemisebenzi ye-AI.
Isixazululo sezakhiwo
Ungase ufune ukuphakela izixazululo zokusakaza bukhoma ngokusebenzisana kwezwi ngezilimi eziningi kulezi zimo ezilandelayo: Izimoto ezixhunyiwe esiza abashayeli ngamakhono okuhumusha ngesikhathi sangempela. Izimboni ezihlakaniphile ezeseka ukuxhumana kwabasebenzisi bamasiko ahlukene ngamasistimu okulawula ikhwalithi asebenza ngezwi. Amarobhothi izinhlelo zokusebenza ezihlinzeka ngokusebenzelana kwamakhasimende ngezilimi eziningi. Ikhaya elihlakaniphile amadivayisi anikezela ngesilawuli sezwi esisheshayo ngezilimi ezahlukahlukene, ukuze ukwazi ukuthola ukwesekwa kobuchwepheshe bomhlaba wonke ngokuhumusha komsindo kwesikhathi sangempela neziqondiso ezibonakalayo.
Umdwebo olandelayo ubonisa indlela yokukhipha isisombululo se-Nova Sonic kanye ne-Kinesis Video Streams njengesevisi ye-WebRTC ephethwe. Ibonisa ukuhlanganiswa kwamathuluzi nemithombo edumile efana ne-Retrieval Augmented Generation (RAG), Model Context Protocol (MCP), kanye nama-Strands Agents.
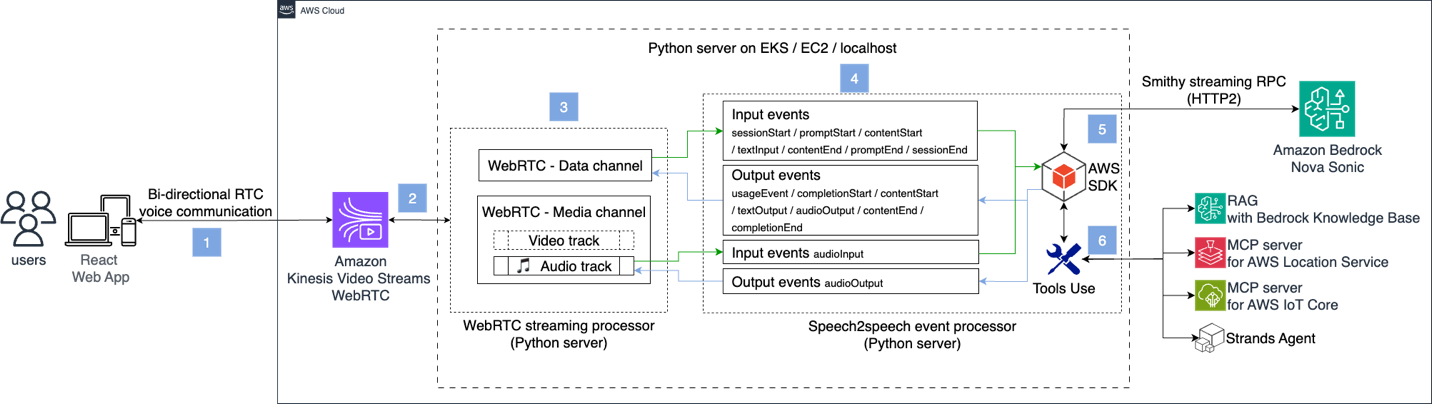
[1] Kuhlelo Lokusebenza Lweklayenti, abasebenzisi basungula inqubo yezingxoxo ye-WebRTC ngokuxhuma esiteshini sokusayina se-Kinesis Video Streams WebRTC. Idatha yomsindo nevidiyo idluliselwa ngoxhumano lwe-WebRTC olukabili.
[2] Ngemva kokusayina imilayezo yeSivumelwano Sencazelo Yeseshini (i-SDP) yokunikeza/impendulo kanye ne-Interactive Connectivity Establishment (ICE) ukushintshanisa amakhandidethi, iklayenti neseva baqala imizamo yokuxhumana kontanga ezinhlangothi zombili. Bese idatha yevidiyo neyomsindo ingadluliselwa ngokubambezeleka okuphansi ngoxhumo oluyimpumelelo lwe-RTC.
[3] Isiteshi semidiya siphatha ukusakazwa kwesikhathi sangempela komsindo nevidiyo ngokulawula okuguquguqukayo kwe-bitrate nokuxoxisana nge-codec. Ishaneli yedatha ihlinzeka ngokudluliswa okuthembekile nokuhlelekile kwedatha yohlelo lokusebenza ngokungafanele, isb umbhalo, amafayela, nemiyalezo yokulawula. Zombili zisebenzisa ukubethela kwe-Datagram Transport Layer Security (DTLS) kanye neSession Traversal Utilities ye-NAT (STUN)/Traversal Using Relays ezizungeze izivumelwano ze-NAT (TURN) zokuhumusha Ikheli Lenethiwekhi (NAT) ukuvundla.
[4] Iphrosesa yomcimbi wenkulumo-enkulumweni ihlela imicimbi yokufaka kanye nokuhlanganyela kwemicimbi yokuphumayo ne-Nova Sonic. Esixazululweni sethu, zihlukaniswa ngemicimbi yemidiya esakazwa ngesiteshi semidiya se-WebRTC, kanye nedatha yombhalo ngesiteshi sedatha ye-WebRTC.
[5] Usebenzisa i-Python SDK ukuze usungule uxhumo lwe-HTTP/2 ukuze usakaze izinhlangothi ezimbili nge-Nova Sonic. Lokhu kuxhumana kusekela ukuxhumana kwedatha yemidiya yesikhathi sangempela futhi kunciphisa ukubambezeleka kwabasebenzisi.
[6] Ngokungeziwe engxoxweni yomsindo yenkulumo-enkulumweni ngolwazi oluqeqeshwe kusengaphambili, i-Nova Sonic isekela ukushaya kwethuluzi elivumelanayo ukufinyelela amaseva e-MCP, ama-Strands agents, noma i-RAG. Lokhu okuthunyelwe kubonisa isici sokusebenzisa ithuluzi ngezibonelo.
Uma usuvele usebenzisa i-Nova Sonic, uzobona ukuthi lesi sakhiwo siyafana nesixazululo seWebSocket. Ngizokukhombisa umehluko obalulekile.
Isilinganiso sesixazululo
Uma kuqhathaniswa nenketho yokuphakela ye-WebSocket, lesi sixazululo esisekelwe ku-WebRTC senkulumo-enkulumweni sinikeza isendlalelo senethiwekhi esihlukile esilungele amadivayisi eselula kanye ne-IoT. Lawa madivayisi ngokuvamile adinga ukuxhumeka okubambezeleke okuphansi ngaphandle komkhawulokudonsa wenethiwekhi ophezulu. Isixazululo siphinda sifake isendlalelo esenziwe ngokwezifiso Sokutholwa Kwezwi (VAD) ukuze uthole ulwazi olunzulu ngomsebenzisi.
Iphrothokholi yokusakaza umsindo ishintshile ukusuka ku-WebSocket kuya ku-WebRTC
Idatha yezwi idluliselwa ngesiteshi semidiya se-WebRTC ngendlela yokusakaza, okungukuthi ngengoma yomsindo yokuxhumana kontanga ngefomethi ye-Secure Real-time Transport Protocol (SRTP), esikhundleni semilayezo ye-WebSocket. Senze izici ze-WebRTC (ezifana nomnikelo/impendulo ye-SDP, i-DTLS, I-Stream Control Transmission Protocol (SCTP), SRTP, kanye nokuxhumana kontanga) sisebenzisa ilabhulali ye-aiortc Python.
Indlela yokuthola izwi lomuntu
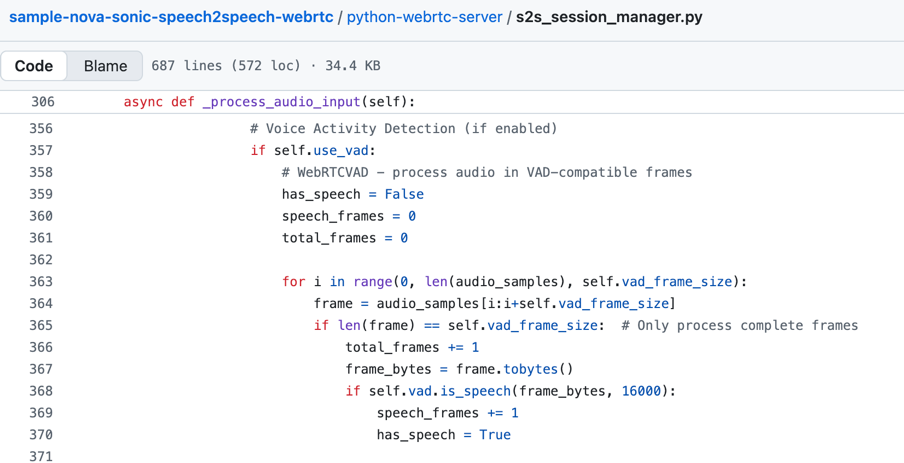
Iklayenti le-React WebRTC lithwebula ngokuqhubekayo umsindo futhi liwuthumela kuseva ye-Python WebRTC. Ukuze ucindezele umsindo, ukhuphule ukunemba kwenkulumo, futhi unciphise amathokheni omsindo we-Nova Sonic, isixazululo sisebenza Ukutholwa Kwezwi Lezwi (VAD) epayipini ohlangothini lweseva. Ukuqaliswa kwekhodi okusekelwe kulabhulali ye-Python WebRTCVAD kuboniswa esithombeni esilandelayo. Yakhelwe nge-Gaussian Mixture Model (GMM), le labhulali ayisindi, izinzile, futhi iyashesha ekucutshungulweni komsindo okuleveli yozimele ye-WebRTC. Ungasebenzisa futhi eminye imitapo yolwazi efana neSilero VAD, Pyannote VAD.
Ukujwayela ifomethi yedatha yomsindo
I-WebRTC ichaza amazinga athile efomethi yomsindo nevidiyo. Lapho uthumela futhi wamukela idatha yomsindo ngoxhumano lwe-WebRTC, kufanele wenze ifomethi ethile: [1] Ozimele be-stereo abaphakathi nendawo badinga ukukhipha isiteshi somsindo esingakwesokunxele noma kwesokudla; [2] 48kHz noma amanye amanani amasampula azokwenziwa kabusha abe ngu-16kHz, njengoba kudingwa i-Nova Sonic API; [3] Amanani edatha ye-Int16 azoguqulelwa ku-Float32 ukuze uthole ukunemba okuthuthukisiwe kwesibalo. Ukuze uthole imininingwane eyengeziwe, bheka imibhalo ye-GitHub.
Isixazululo sokuhamba
Isixazululo kule nqolobane ye-GitHub sihlinzeka ngesampula evamile kanye nezibonelo ezimbili eziqondile zesimo: isibonelo sasekhaya esihlakaniphile kanye nesibonelo semoto exhunyiwe. Ungajwayela la maphethini kwezinhlelo zakho zokusebenza.
Isibonelo sasekhaya esihlakaniphile
Esimeni sasekhaya esihlakaniphile, uvula ingxoxo ne-Nova Sonic ukuze ulawule amadivayisi e-IoT. Ukukhombisa ipayipi lomyalo ogcwele, isixazululo sisebenzisa i-Amazon Bedrock Knowledge Base ukubuyisa izihloko ze-MQTT futhi sikhiqize izimpendulo ze-AI. Ibese ixhuma kuseva ye-MCP ye-AWS IoT Core ukuze ilethe imilayezo yomyalo. I-architecture ephelele iboniswa esithombeni esilandelayo.
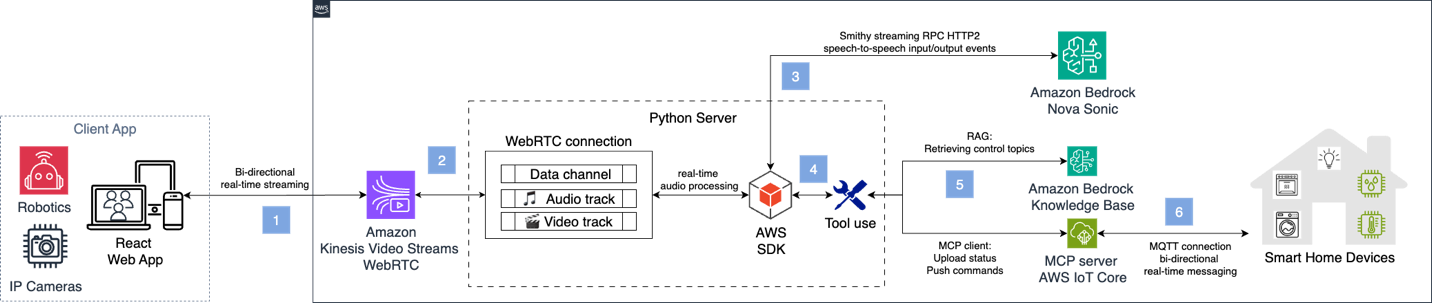
Ukuze uthole izinyathelo zokusetha, bona i-smart-home readme ku-GitHub.
Isibonelo semoto exhunyiwe
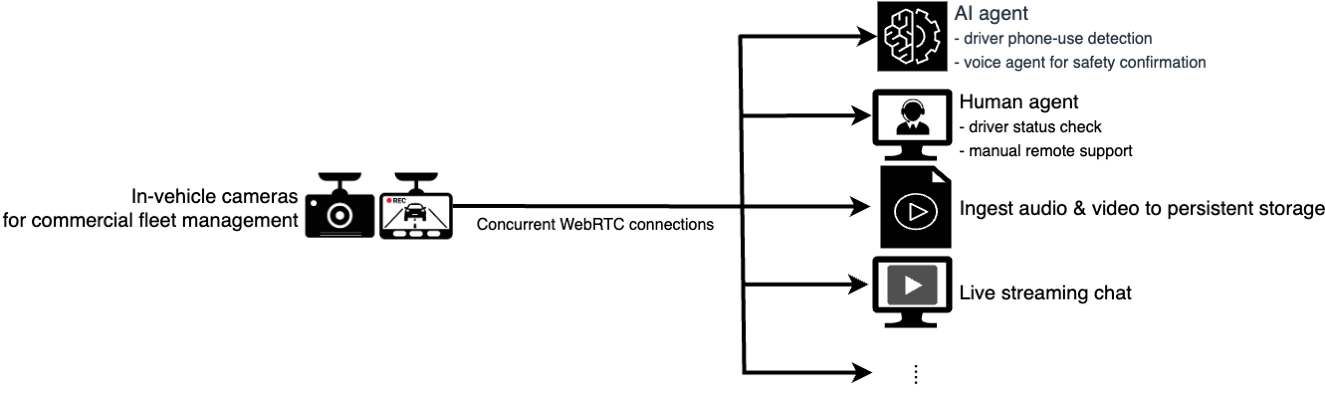
Esimeni semoto exhunyiwe, isistimu isungula ukuqapha kwesikhathi sangempela ukuze kutholwe ukuziphatha okuyingozi kokusetshenziswa kwefoni kwabashayeli. Uhlelo lusebenzisa abasizi bezwi ukuze babuze ukuthi ngabe usizo luyadingeka yini futhi baqinisekise ukunaka komshayeli. Izisebenzi ezigadayo zingafinyelela izifunzo zokuqapha ngesikhathi sangempela esiteshini esizimele sevidiyo ukuze ziqinisekise isimo sokuphepha kokubili kwezimoto nabashayeli. I-architecture elandelayo ibhekana nalesi simo:
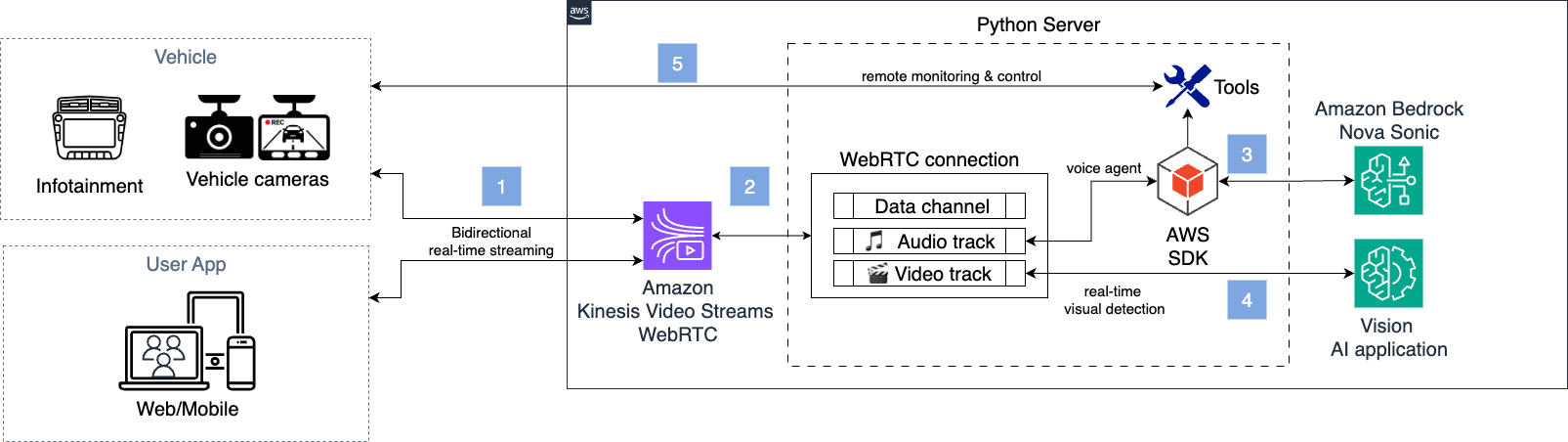
Ipayipi lemidiya eligcwele esimweni semoto exhunyiwe liboniswa kumdwebo olandelayo. Uxhumo lwe-WebRTC ngasikhathi sinye luzimele komunye nomunye ngokubethela okuzinikele kwe-TLS.
Ukuze uthole izinyathelo zokusetha, bona i-readme yemoto exhunyiwe ku-GitHub.
Isiphetho
Kulokhu okuthunyelwe, sikubonise ukuthi ungakha kanjani isixazululo esisekelwe ku-WebRTC esihlanganisa i-Amazon Nova 2 Sonic ne-Amazon Kinesis Video Streams WebRTC. Lesi sixazululo sibhekana nezithiyo ezivamile ekusakazeni bukhoma, njengokusebenza okonakele kumanethiwekhi angazinzile kanye nokuntuleka kobuhlakani bengxoxo. Ungasebenzisa lesi sixazululo njengesisekelo sokwakha eyakho i-low-latency, ehlakaniphile, eqinile, izicelo zomsizi wezwi eziguquguqukayo zabasebenzisi bamadivayisi ahlakaniphile nezimoto ezixhunyiwe.
Ukuze uqalise futhi ufunde kabanzi:
Mayelana nababhali



