
With the advent of AI, the modern marketer is now responsible for creating more effective content, generating measurable engagement, and customizing the customer experience, all with reduced time and resources.
This is where Generative AI for marketing professionals redefines work. From helping teams scale content creation to automating strategic planning, GenAI is becoming a critical skill for those aiming to accelerate growth and make a real competitive difference.
In this article, we explore why GenAI is changing the game and some skills you need to develop to lead in this new era.
Summarize this topic with ChatGPT
Find important takeaways and ask questions
Obstacles That Prevent Marketers From Creating a High-Impact Strategy
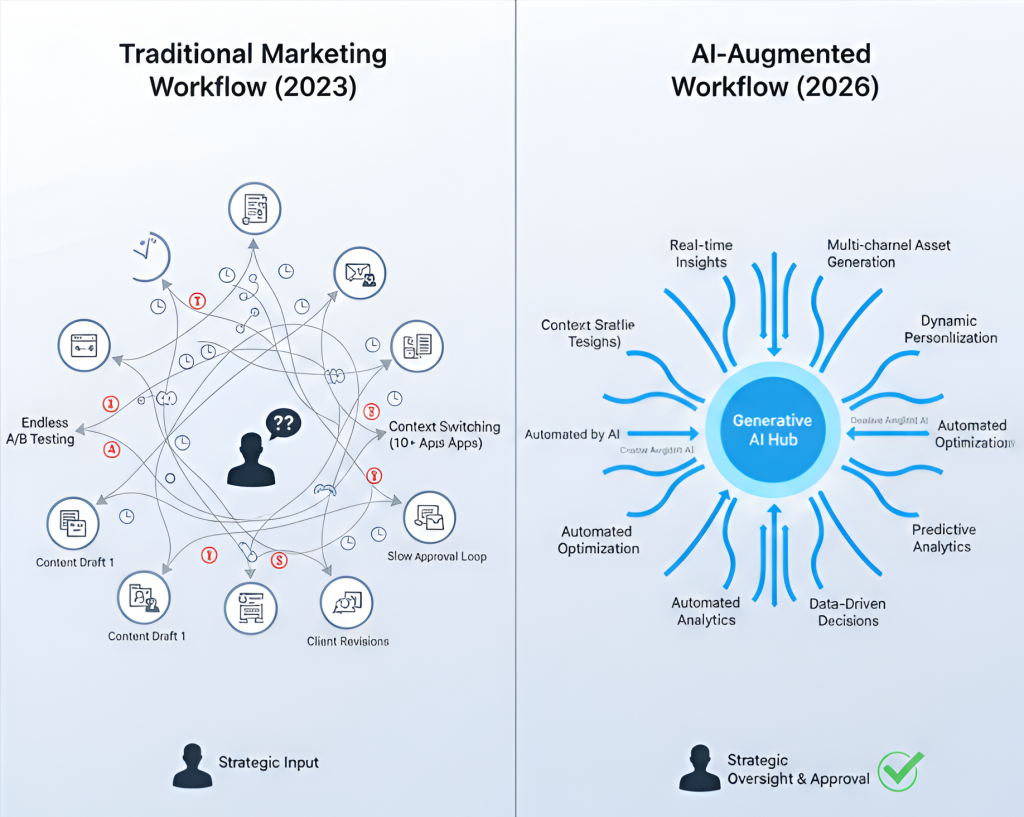
Before looking at the solution, we must acknowledge the “Operational Noise” that is currently blocking sales doors.
- Content Treadmill: Marketing teams spend about 41% of their workday on editorial tasks, repetitive content editing, manual asset sizing, A/B testing variations, and basic copy revisions. Many of these time-consuming tasks, such as reporting, approvals, formatting, and workflow communication, are increasingly being handled through AI-driven automation, as outlined in this guide to automating routine tasks with AI.
- Creative Burnout: If a creative lead has to jump between 10+ apps to put together a single campaign, the resulting “content shift” can reduce production time by up to 40%.
- The data-to-action gap: Although marketers have access to vast amounts of data, turning information into timely creative or strategic action remains a challenge. Analysis is often delayed in execution, leading to effective marketing instead of effective marketing.
- Pressure to Deliver Measurable ROI: With increasing expectations for speed, personalization, and performance, marketers are expected to do more with fewer resources, often prioritizing short-term execution over long-term product and growth strategy.
Generative AI changes this equation by removing talent a lot of work to strategic control.
How Generative AI Streamlines Work for High-Impact Marketing Results
Generative AI serves two distinct but complementary purposes: Default (taking “to do”) and To increase (developing “thinking”).
1. Hyper-personalization and Dynamic Segmentation
Modern marketing needs to go beyond static people to continuously improve audience intelligence. Manually segmenting customers and aggregating information at scale is time-consuming and structurally limited.
How Generative AI helps:
Generative AI enables real-time segmentation by integrating behavioral, transactional, and contextual data across channels. Messaging, offers, and journeys can be flexibly tailored to individual users, improving relevance while reducing manual intervention. This allows marketing leaders to deliver personalization at scale without operational complexity.
For a direct look at how powerful personalization plays into audience targeting and messaging, see this article on personalization in email marketing.
2. Rapid Content Creation and Creative Development
Marketers face constant pressure to produce large volumes of channel-specific content. Manually building, resizing, and duplicating assets across formats drains creative energy without increasing strategic value.
How Generative AI helps:
Generative AI generates high-quality creative drafts, copy diversity, and multimodal assets from a single strategic brief. Generative AI for marketing professionals can provide a “bottom-up-front” result that allows teams to focus on driving emotions, product differentiation, and improving performance, rather than generating files, as explored in this detailed guide AI for content creation.
3. Predictive Consumer Intelligence and Real-Time Insights
Traditional analytics rely on retrospective analysis and slow research cycles, which limit the ability to respond proactively to market shifts.
How Generative AI helps:
Acting as an intelligence layer across all data sources, Generative AI combines customer experience, campaign performance, and market signals into actionable insights. Predictive modeling enables leaders to anticipate outcomes, stress test situations, and adjust strategies before performance declines, transforming marketing from proactive optimization to strategic foresight.
4. Automated Processing Across the Retail Value Chain
Marketing operations are burdened by repetitive, low-value tasks such as approvals, reporting, versioning, and field communications.
How Generative AI helps:
Generative AI automates workflows across the marketing lifecycle, from content adaptation and evaluation to reporting and in-house writing. By reducing conflict and hand-offs, teams reclaim time for high-quality decision-making and cross-functional collaboration.
For a comprehensive look at technologies that remove manual constraints from all marketing activities, check out this guide to the top automation tools.
5. Strategic Decision Support and Leadership Empowerment
As complexity increases, marketing leaders must make quick, high-quality decisions with incomplete information.
How Generative AI helps:
Generative AI supports executive decision-making by summarizing trade-offs, highlighting risks, and presenting data-driven strategic options. Rather than replacing judgment, it enhances leadership thinking, making it easier to prioritize, align faster, and act with more conviction.
Mastering the Shift: 3 Skills Every Marketer Needs
To successfully lead this change, marketers must go beyond the use of sophisticated tools. To “master” technology, you need to develop these three key skills:
- Advanced Prompt Architecture: Apart from simple instructions, you should know Chain of Thought (CoT) motivation. This involves building a multi-step workflow where AI breaks down complex marketing problems into a logical sequence, ensuring your output aligns with your brand voice.
- AI Data Literacy & Synthesis: Your value is now at rest definition. Marketers must be able to analyze the insights generated by AI, identify “negative ideas” in performance data, and synthesize disconnected signals into a coherent story.
- AI Management and Risk Management: You are the guardian of brand integrity. This means creating “Human-in-the-Loop” (HITL) agreements to prevent product dilution, bias, and legal risk. Mastery includes establishing internal guardrails to ensure data security and quality control.
Strategy: Moving from a single notification to an incremental workflow requires a special skill. Programs such as Johns Hopkins University's Generative AI Course provide the strategic frameworks needed to move from technology hype to real business value.
Challenges and Risks Marketers Must Avoid
While the benefits are many, the strategist must navigate the following challenges:
| Challenge / Danger | Explanation | Reducing Tactics |
| Brand reduction | AI content may not have a different voice or cultural context. | Enforce Human-in-the-Loop protocols for emotional depth. |
| Legal and Moral Bias | Models may reproduce copyrighted material or data bias. | Use business-grade platforms with refund protection. |
| Automation Bias | Overreliance on AI may reduce critical thinking. | Treat AI as an intermediary whose results must be verified. |
| Loss of Distinction | Widespread use of similar tools can lead to homogenized loading. | Anchor AI results in proprietary, first-party data. |
The conclusion
The future of marketing is not in creating more content, but in better results. Generative AI helps marketing professionals leave the noise behind the performance and get straight to the strategic clarity. Today, people using these tools as a decision support partner will determine the speed, power, and competitiveness of their products in the future.



