Umbzuai investigators release K2 Think: A long 32B open system of AI Reasoning to consult with 20x thousands

A group of researchers from the Embzuai's Institute of Foundate Models and G42 issued K2, 32b-parameter open open consultation program AI developed. Ling Goet Chain-of-You Thought to Be Good Guidance Feeding from Certified Rends, Agentic Arrangement, Measuring Testing Time, and Accercer-Scale-Scale-Scale Hardware decorations). The result is the primary-level mathematical performance and competitive cones and competitive results in the code and science-together with the weight of issuing, open data.
Looking for everything
K2 Think of Training After QWEN-weight training emphasizes the efficiency of parameter: 32b spine is deliberately selected to enable the fastesting and transportation while leaving Headown for training benefits after training. Core recipe include six “Pills”: (1) Long Chane (COT) time is logged in Tuning; (2) The validity of the learning with certified rewards (RLVR); (3) Agentic planning before resolving; (4) measure the test period for the excellent NU course for the learning; (5) A consideration of consideration; and (6) submission to the high-quality engine.
OBJECTIVES INCREUATIONS: EXCEPT ORDERY I @ 1 In Competitive Benches, Save Firms Code / Science Work, and save a Coder and Wall-Clock Latency Under Plan-Before Plant Management Management.
Pillar 1: Cong Cot SFT
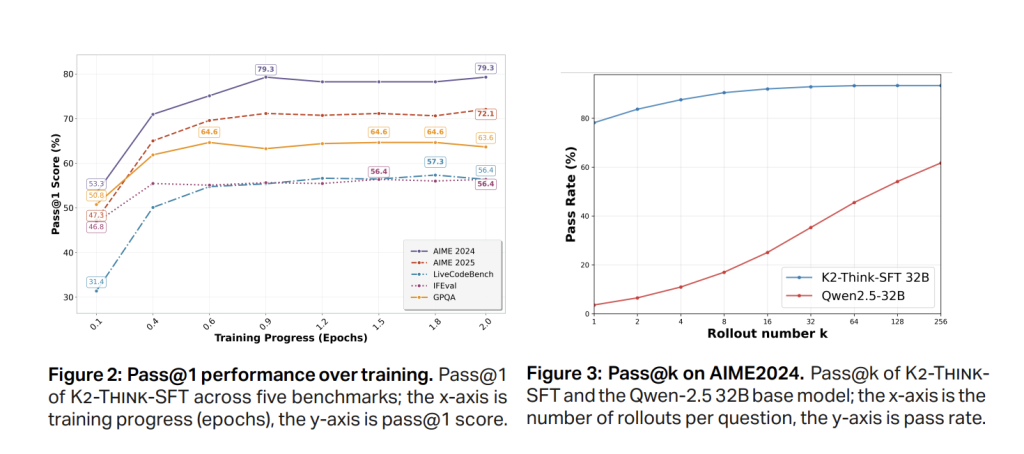
Section 1 SFT uses a curry trail, long-of-redit-of-redite commands / answer pairng spanning Math, code, science, the following version, and a regular conversation (Am-Dingial-V1-Diployed). The result is to teach the basic model to get medium-term thinking and accept the orderly output format. RAPID PASS @ 1 Benefits happen in advance (≈0.5 EPOCH), with AIM'24 settled around ~ 79% and Aim'25 around the SFT test before RL, indicating conversion.
Pillar 2: RL with certified rewards
K2 Think and Train RLVR CarA ~ 92k-Prompt, six domain dataset (figures, code, science, reasonable, simulating, simulating) is designed for the end of the end end. Implementation using Beenbird Library with a Grippo's algorithm. Significant observation: Starting RL from powerful The SFT checkpoint contains modest benefits and Cletheau / deteriorating benefits, and uses the same RL recipe directly to AIME'24 over AIME'24 on top of the Sort Gentroom.
The second abundance indicates RULTI-Stage RL with reduced content window (eg
Completals 3-4: Agentic “Plan-Pred-Want-You-Think” and Time Assessment
At the offer, the first system comes out together plan Before making a full solution, then do the best-of N (eg two results: (i) relevant benefits from the combined scaffold; and (ii) short The last answers in spite of the Token's Token figures drop across the benches, decreasing up to ~ 11.7% (eg this is important for both latency and costs.
The level analysis of the table shows K2 response length short than the QWEN3-23B-A22B and the same distance as GPT-OSS-120B in mathematics; After adding a Plan-Premias and Verifiers, regular K2 tokens Think of common appear in post-training exams (eg '
Possiers 5-6: Obstructed assumptions and limited speculation
K2 to think intended The engine of cerebras wafer-scale Containing with The thought-guessing guessPer-Request PrepPut to the top 2,000 Token / SEC tokensWhat makes scaffefld test used the production and research of loops. Hardware-Azing Starting method is the central part of issue and alignment and philosophy “quick” program.
Protocol to check
Benchmarking includes competing figures (AISE'4, AIME'25, HMNT'25, Omni-Math-Math-Hard); Research V5; A Signup Group: Simple Generation Tokens and individual points such as Average 16 Independent Pass @ 1 Checking to reduce the difference of running.
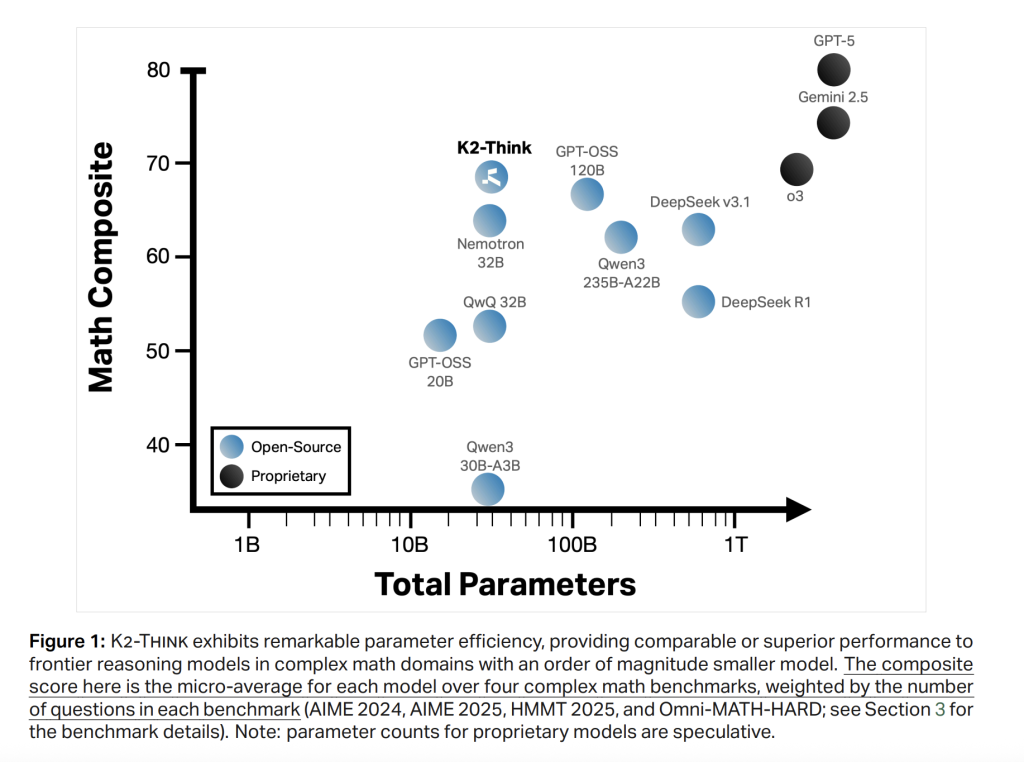
Result
Math (mediums between AIM'24 / '25, HMMT25, Omni-Hard). K2 Think of Access 67.99leading a high quality cohort and in well comparing the largest programs; Sent 90.83 (Aim'24), 81.24 (Aime'25), 73.75 (Hmmt25), and 60.73 In Omni-Hard-Hard-the watter is the most difficult crack. Standing associated with the functionality of a strong parameter related to Deepseek V3.1 (671b) and GPT-OSS-120B (120B).
Code. LIVECEBELCH V5 Score is 63.97Exceeding the same wide peers and high open models (eg,> QWEN35B-A22B in 56.64). In scicode, k2 think 39.2 / 12.0 (Sub / main), tracking the best programs open with the accuracy of the lower problem.
Science. GPQA-Diamond reaches 71.08; Respectable 9.95. The model is not just a math technician: It always contains all information-free information.
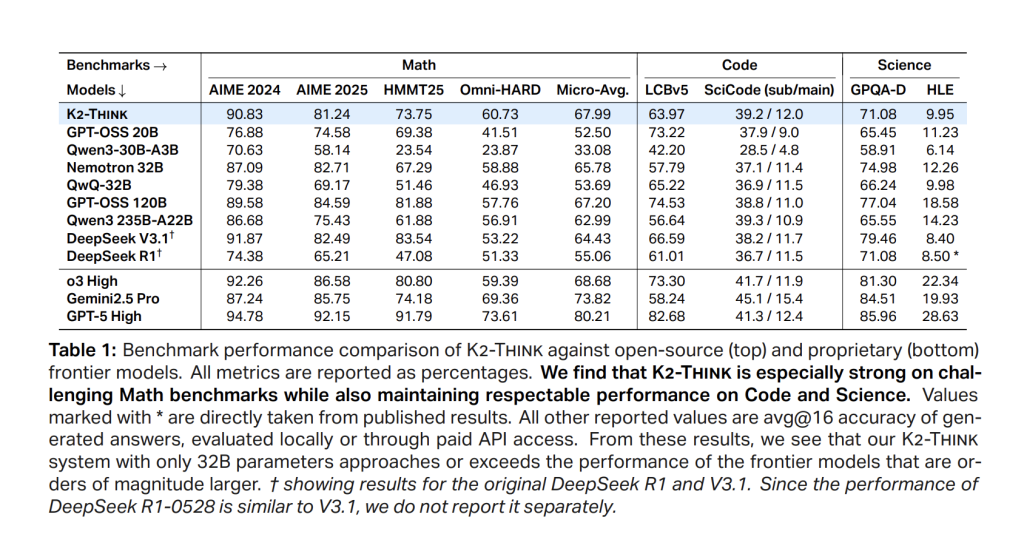

Important numbers are ignored
- Backbeone: QWEN2.5-32B (open weight), after training with Cot Soft + RLVR (grpo with Beenbird).
- RL data: Guru (~ 92K is encouraging) in all math / code / science / logic / simular / tabrer.
- Indence Scaffold: Plan -the before you think + Bon with reasons; Short consequences (eg, -11.7% tokens in Omni-Hard) with high accuracy.
- Target target: ~2,000 Tok / S In cerebras wse in thought testing.
- Micro-AVG: 67.99 (Aim'24 90.83Aieme'25 81.24Hmmt'25 73.75Omnyi-Hard 60.73).
- Code / Science: LCBV5 63.97; Scicode 39.2 / 12.0; GPQA-D 71.08; Wilderness 9.95.
- Safety-4 Macro: 0.75 (0.83 refusal, tested. Clothing 0.89, cybersecurity 0.56, jailbreak 0.72).
Summary
K2 think show that Mixed training of post + Hartware + Hargeer-Waare to understand It can shut down a lot of gap into major, relating to relation. In 32b, it is carefully busting and serving; with a plan-before thinking and bon-win-venifiers, it is controlling the budget of[Line;Withconsiderabledecorationsinawifer-scalehardwarereaches~ 2K Tok / S per application. K2 Think of the presentation as completely open program-Weight, Training Data, Shipping Code, and Code for Use Time.
Look Paper, Model in the face of face, GitHub and direct access. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.



