DEEPRINFORCE TEAM delivered Cuda-L1: Default Learning Framework (RL) to find the power of an opening of a Cuda in 3x Power from GPUS
 to find the power of an opening of a Cuda in 3x Power from GPUS")
Time to read measured: 6 minutes
AI has just opened three times the energy from GPU-without human intervention. DeePreinforce group presented a new frame called Cuda-l1 That moves the rate 3.12 × Speedup up to 120 ×'s faster Peak To the actual 250 actual gPU activities. This is not just an educational promise: All the results can be rebuilt with an open source code, with a widely used hardware.
Success: Authentic reading (variation-rl)
In the heart of Cut-L1 very lying AI Learning Stratening Strategy: A different strengthening reading (variation-rl). Unlike rl traditional, where AI is simply producing solutions, receiving numerical rewards, and stimulates its model patterns blindly, variation-rl Feeding back to work scores and previous variations directly to the next generation.
- Workout scores and different items are given AI in each of the achievements.
- The model should Write “Work analysis” in the natural language-Reflecting in quick code, whyAnd what strategies have led to that for speed.
- Each step is forcing to be easy to thinkTold the model to combine not just a different kind of code but standard mental model, driven by the time of the Code code.
The result? AI Discovers not only knownbut also invisible tricks That even human experts often ignore – including the shortcuts of the mathematical numbers, or memory strategies are organized in certain hardware quirks.
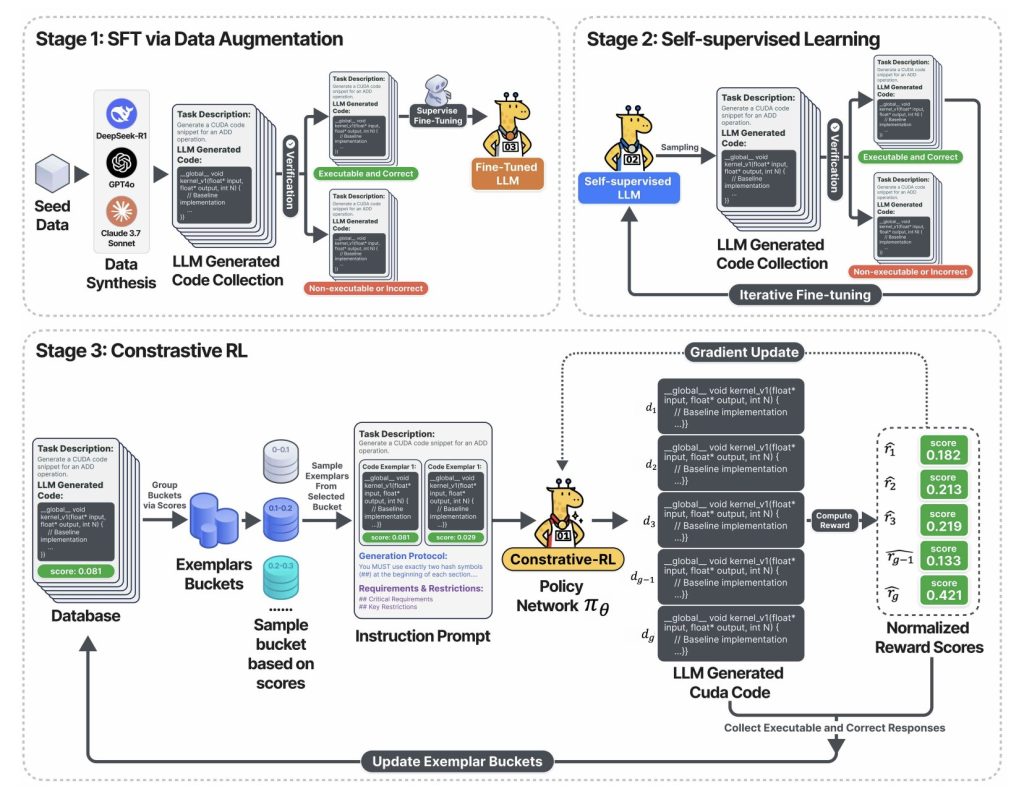
The above drawing is holding A pipe with three stage:
- Section 1: The llm is well organized using a certified Cuda Code for sample from the leading acquirer (DEEPSEEK-R1, GPT-4O, but maintains appropriate and effective results.
- Section 2: The model enters a training loan: produces a lot of cuda code, only lasts to work, and uses that to learn. Result: Quick improvements for code and coverage-covering and all of the written labels.
- Section 3: In REPRestititite-RL classThe sampling system of many codes, showing each of its measurements, and the challenges of AI are arguing, analyzing, and analyzes previous generations before producing the following cycle. This loop show and improving Flywheel locks that introduce the main pace.
How beautiful is Cupra-L1? Hard Data
Haste across the board
Kernelbench-Inato valuations of gold with the production of GPU code (250 real-world pytro woods) -He used to measure cuda-l1:
| Model / category | AVG. Hurry | Max Speardup | Sentient | Success level |
|---|---|---|---|---|
| Vanilla Lla-3.1-405B | 0.23 × | 3.14 × | 0 × | 68/20050 |
| Deepseek-R1 (rl-tuned) | 1.41 × | 44.2 × | 1.17 × | 248/250 |
| Cuda-L1 (all categories) | 3.12 × | 120 × | 1.42 × | 249/25050 |
- 3.12 × average average: AI found progress in almost every job.
- The top 120 × speed: Other Ovenability and Computational) bottles and unemployment code (such as diagonal matrix repetition) changed with the highest solutions.
- It works on the other side of Hardware: Nvidia A100 GPU codes kept Major Benefits written to other buildings (L140, H100, RTX 3090, H20), with straight speedsups from 2.37 × to 3.12 ×Benefits in the Median above 1.1 × on all devices.
Project Lesson: Finding Hidden 64 X and 120 × Depupups
DIAG (A) * b-matrix multiplication with diagonal
- Index (does not work):
torch.diag(A) @ BIt creates a full matrix of diagonal, requiring io (N²m) Compute / Memory. - Cuda-L1 is well done:
A.unsqueeze(1) * Bstreaming to broadcast, just to achieve only the hardship-which leads to 64 teenager ×. - Why: AI thought that full diagonal allocation was unnecessary; This understanding was not inaccessibility in the conversion of Brute-Force Mitation, but included under comparisons of all the solutions produced.
3D converted version – 120 × faster
- Real code: Full estimates have been conducted, monitoring, and activating – even if it is entered input or statistical or statistically with zeros statistics.
- Prepared code: Used “Mathematical Short-Circuit” -Paping That
min_value=0The result can quickly be edited in zero, To pass all the combination and memory allocation. This one is one-sided Orders in magnitude More speed are hardware-level micro levels.
Business Impact: Why this is important
For business leaders
- To save the exact cost: Every 1% shadulu in GPU activities translate 1% clouds, low costs, and more model. Here, AI delivered, on average, more than 200% high extra from the same investment.
- Rapid product cycles: Automatic efficiency reduces the need for CUDA professionals. Groups can open up to achieve the benefit of hours, not months, and focus on factors and research of velocity instead of low planning.
For AI workers
- Confidence, Open Source: All Cuda's prepared Cuda is open. You can view the speed and laugh across A100, H100, L40, or 3090 GPUS-No Trust Trust.
- No Cutter Black Magic required: The process does not rely on confidentiality, customers' customers, or tuning person in-the-the-loop.
For researchers of AI
- The Background Displays Reasoning: Advertive-RL provides a new way of training AI on domains where accuracy and functionality – not only natural language.
- Reward to hack: Writers move inside the abuse of AI.
Technical Understanding: Why is the Rel-RL
- The working response is now the cure: Unlike Vanilla RL, AI can read not by trial and error, but by Pride of consideration.
- Improving FLWHEEL: Loop indicating that the model is strong to reward and strive both the paths of evolution (a fixed parameter, traditional reading of traditional healers).
- Turn and get basic principles: AI can include, AI, and use the Key Use Strategies as Memory Coalescing, Find Block Premeal, Warp-Level Memory, Warp Level, and statistics.
Table: Highest techniques found by Cuda-L1
| The process of doing well | General speed | Example Understanding |
|---|---|---|
| Memory usage | Fitness that can change | An exciting memory / storage storage |
| Memory access (Consolidation, Shortened) | Table-to-High | Avoid bank conflicts, you increases bandwidth |
| Operation Fusion | The high ops of w / Pipeled | Multi-OP Kernels reduces Memory to Read / Write |
| Short Mathematics | Highest (10-100 ×) | Receives when combined completely |
| Thread Block / Parallel Config | Moderate | Admatic size / Hardware Shapes / Work |
| Warp-Level / AdminCtion Unnecessary | Moderate | Reduce variety and synchronization |
| Subscribe / memory allocation | The middle of the top | Caches typical data near the computer |
| Async murder, little sync | Varies | Overlaps I / O, enables the written integration |
Conclusion: AI is now its good worker
With Cuda-L1, AI has be its operating engineersAccelerate accelerating production and hardware return-without leaning on human technology. The result is not just high benchmarks, but blue for AI programs that they taught them to combine the full power of hardware running.
AI is now building their own Flywheel: It works very well, healthy, and better able to grow the services we give in-scientific, industry, and beyond.
Look Paper, Codes including The project page. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.




