Minimax AI releases MonImax-M1: The 456b parameter model of the Long-Continex parameter

A long condition challenge showing AI models
The largest consultation models are not built to understand the language but also be organized to think about multiple steps that require long-careed spans and the best understanding. As expected from AI growing, especially in real-land development and software, researchers have searched for buildings that are able to manage a long-location and put deep, united, united.
Computational issues with traditional transformers
Great difficulty in expanding these skills to show lies in the overall integration of the overall generation. Traditional-based models based on SoftMax ignorance method, which is limited to install size. This reduces their ability to manage a remote sequence of inserting or extended specified specified chains. The problem becomes more stressful in areas that require actual interactions or costs of the cost, where measuring costs are important.
Other alternatives and limitations
Efforts to deal with the matter has shown different ways, including good attention and accurate attention. Some groups have attempted world space models and common networks such as other ways in traditional care facilities. However, these new ones have seen limited discovery in the competitive models in competitive due to the difficulties of construction or lack of a scale in real ground management. Even the big plans, such as Huyuntuan-T1 of the Tencen-T1, using Novel Maqa arts, are always closed – a source, thus preventing comprehensive research engagement.
MINIMAX-M1 Introduction: The Open Open Model
Inminimax Ai are laid by Minimax-M1, a new open model, with a greater measure include a mechanical manufacture mixture. It is designed as the appearance of the Minimax-text model, Minimax-M1 consists of 456 million parameters, with 45.9 billion ascribed by each token. It supports the length of the context that reaches 1 million-eight-tilled tokens of Deepseek R1. This model faces the corruption of completility during the measurement period, only 25% of flops needed by Deepseek R1 in the length of 100,000 generation. It was trained using the highest education of works, from Mathematics and installing codes in the software Engineering, marking the transitions of literal, context.
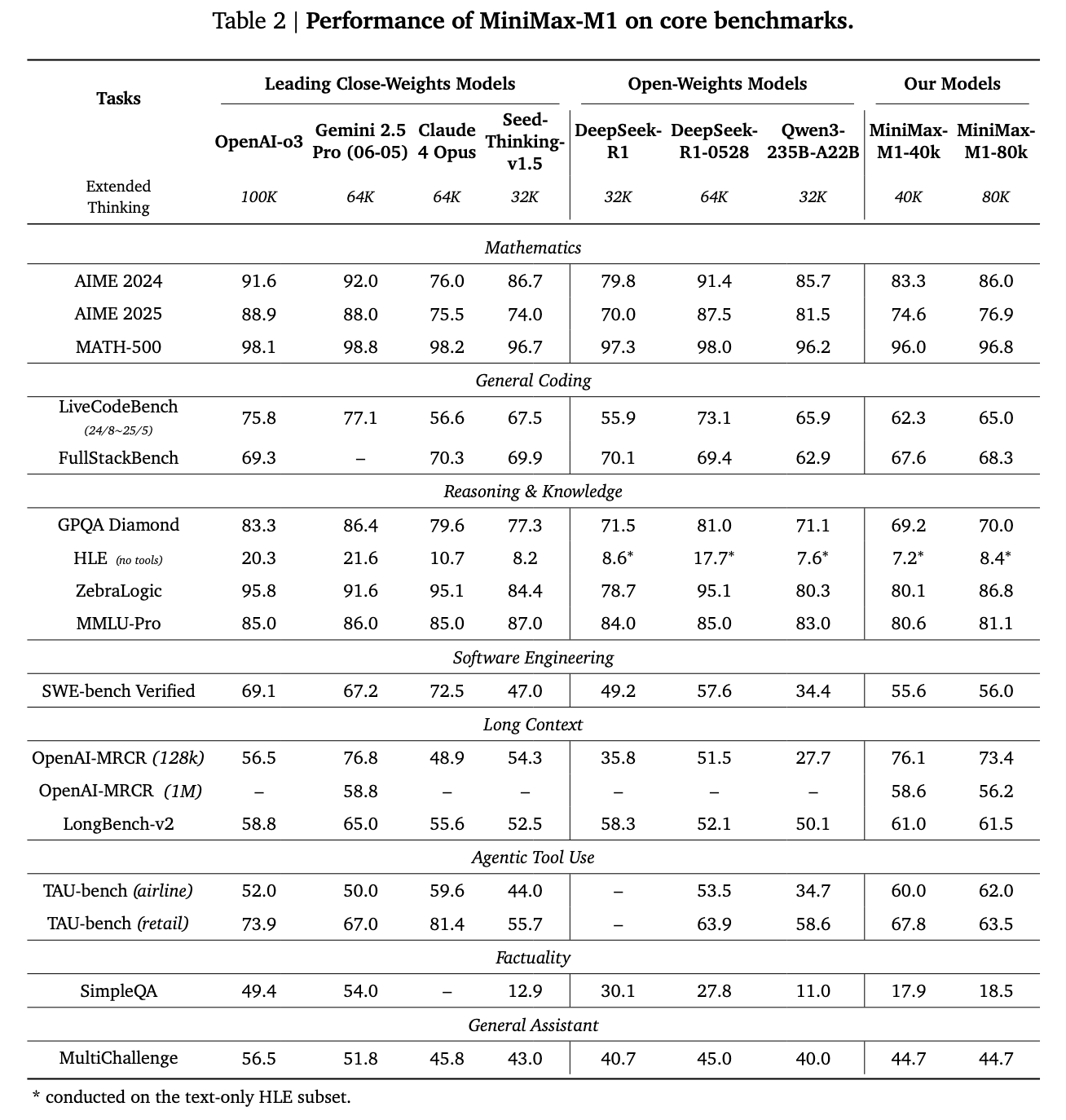
Hybrid-Attention With Lightning and Bloodmap blocks
Increasing this Kingdom, Minimax-M1 using a cleaning process for all transch transformers using traditional softmax care, followed by six blocks using lightning attention. This is very reducing the computational difficulties while preserving work. The attention of lightning is an I / O-Know, transformed from direct attention to direct attention, and it applies to measuring to reflect on the great lengths of thousands of tokens. For effective learning education, researchers present the CISPO algorithm called CISPO. Instead of renewal of Token methods such as traditional ways, CISPO CLISSION Important Weight, making training and consistent tokens, even in policy reviews.
CISPO algorithm and good work RL
CISPO Algorithm has proven significant to overcome the intensity of training facing hybrid buildings. In comparison studies using the QWEN2.5-32B foundation, CISPO has received a 2x schedule in comparison with a dapo. To blow this, the fully-strengthening cycle of MINIMAX-M1 was completed in just three weeks using 512 H800 GPU, at the cost of employing approximately $ 534,700. This model was trained in a variety of dataset that contains 41 logical activities generated by the Synlogic framework and the actual software engineering areas taken from the SWE bench. These good use rewards based on death, leading to strong results in coding activities.
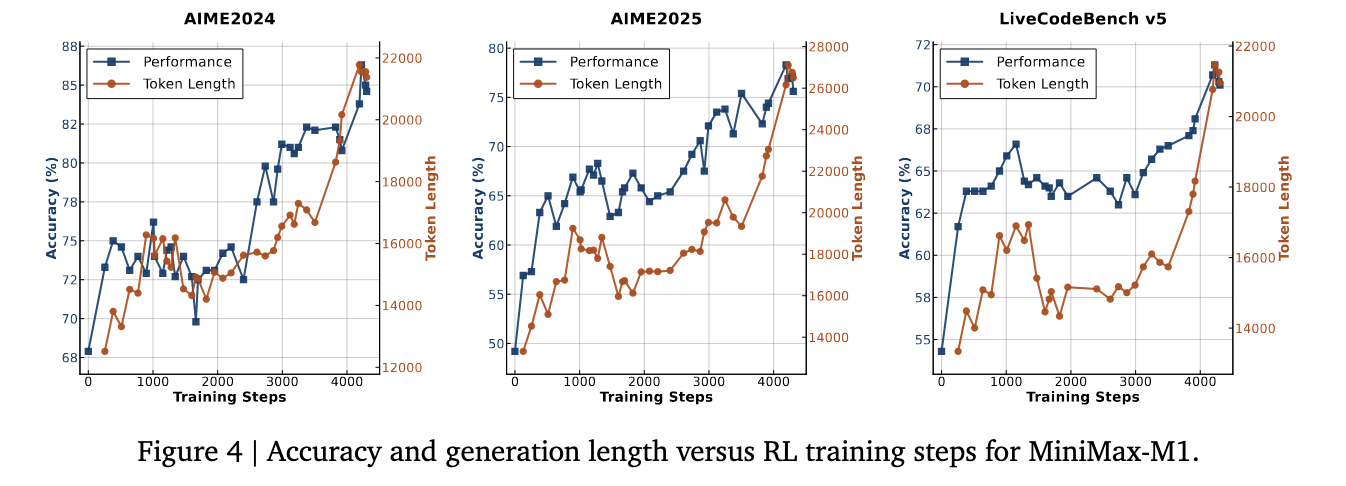
Benchmark and comparative effects
Minimax-M1 has brought Benchmark results. Compared with Deepseek-R1 and QWen3-23B, the beauty of the software engineering passed, processing a long context, and the use of Agentic tools. Although following the latest competitions – R1-0528 in Mathematical and codes, exceeded both Openaai O3 and Claudude 4 Opus in benches of comprehension. In addition, Gemini has passed 2.5 Pro for the tool test of TAU-BENCH AGECCH.
Conclusion: Scale and obvious model for Long-Context Ai
MINIMAX-M1 points to important step forward by giving clarity and disability. By observing the best performance of the performance and difficulty of training, a group of researchers at Minimal Ai has set open-open models. This work is not limited to the solution to the issues of bosses but also present practical ways to measure the language of language in real language.
Look Paper, model and Gititubh. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.

 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


