Google Depmind researchers raise the number of matyooshka: the process of developing a deep learning performance by making the accurate models make

The size is an important way to redemption of the cost of integrating and improve the model performance. Main language models seek main force processing, empowering the key to reduce the use of memory and the speed of development. By turning logical instruments in low-bit-bit format such as Int8, int4, or Int2, the increase reduces storage requirements. However, regular strategies often reduce the accuracy, especially in low data such as int2. The investigators should reduce the accuracy to work properly or maintain multiple models with different levels of value. New strategies are most needed to keep model quality while doing good computer performance.
The basic problem with qualification treats a reduction in accuracy with accuracy. The methods available so far train different models with accuracy or not to benefit the nature of the number number number. Loss of the accuracy of the amount, such as in AT2, is very difficult because its memory wins a widespread disturbance. The similarity of Gemma-2 9B and Miststral 7b is the largest organization, and the process that enables one model to work in a number of accuracy that can improve the efficiency. The need for higher, moderation changes that made researchers to seek solutions without ordinary ways.
Smaller balance strategies, each accuracy and efficiency. Minmax with no minimax and GPTQ methods use measurement statistics in Map Model Weight to reduce small width without changing parameters, but lost the accuracy of the right. Funding based on learning such as training is aware of prices (Qat) and efficient energy supply using Gradient Feather using Gradient Feather. The QAT stimulates models of models to reduce the accuracy of the accuracy of post-qualityization, while the Omniquancer learns measuring and modifying parameters without changing important metals. However, both methods still require different models for different information, strange submission.
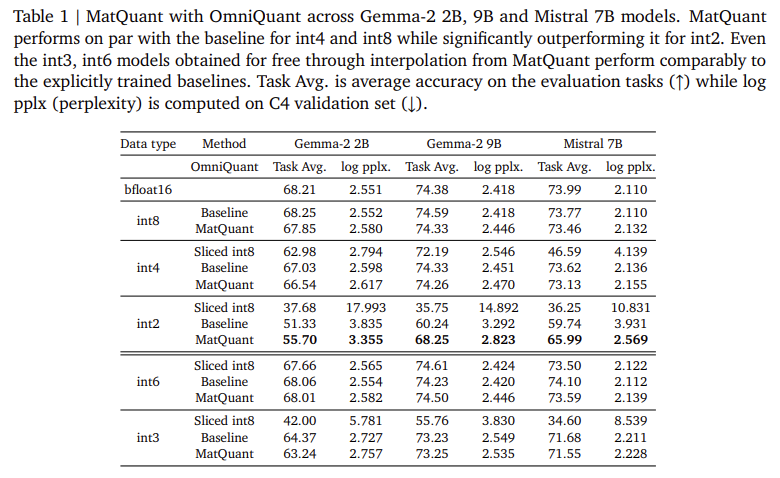
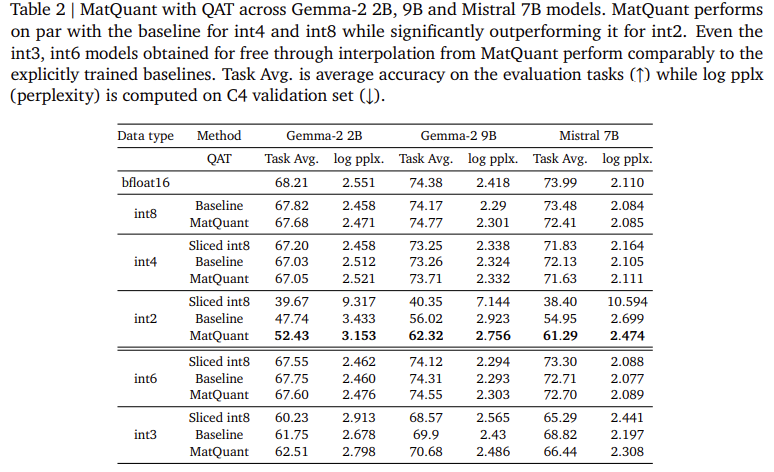
Investigators on Google Deepmind is introduced Matyooshka of naked (matquant) To create one model that applies to all the many levels. Unlike common ways to carry out the range of each part, it usually do it well for IT8 model, int4, and AT2 using a small stolen presentation. This allows models to be included in different information without returning, reducing the cost of integration. The matquant removes low-bit models from a higher model while storing accuracy by contributing hierarcicical structure of numbers of the number. Viewing Gemma-2B, Gemma-2 9. and Martqual 7B models show that matquants promote IT2 accuracy by reaching 10% over standard strategies such as Qat and Omniquant.
The Matquant represents the model instruments at different levels of the list using the most important bits (MSB) and informs them together to maintain accuracy. The procedure of training includes co-operative training and money laundering, ensures that IT2 presentation keeps sensitive information lost in general construction. Instead of renouncing low buildings, the matequant includes the framework for proper use of compressions, which work well without the loss of performance.
The Matquant Assessment Test shows its energy that reduces the loss of accuracy from the extent. Investigators checked the way in TransformMer based on the Feed-Fedwork parameters (FFN), the key feature of the key to the measuring key latency. The results indicate that Int8 and Int4 models of Mat8 and IT4 have reached the comparative accuracy with trained bantines while relieving them from IT2. In the Gemma-2B model, an advanced matriculation of 81%, while the MITTRAL 7B model recognizes 6.35% of the development of 6.35% over traditional ways. This study also found that the miscarriage of matquant weights improves accuracy throughout a minimum, beneficial range of accurate models. Also, matquant enables the translation of the Bit-Bulse of Emless
Several keys to the study from the study is marking:
- Multi-Scale Cautization: Mattquant introduces the novel method to one stream that can work in many levels.
- Bullying of a minor building: The method of receiving a structure with a natural resources within the integers data types, which allows little widths to be taken.
- Developed low-quality accuracy: The mattuquant develops the accuracy of IT2 models separated, the last traditional ways as Qat and the Ompernt with 8%.
- A flexible application: The matequant is compatible with existing learning strategies based on learning such as information training (Qat) and many players.
- Reference: How to successfully use the FFN parameters in the FFN ELMMA – 2B, 9b, and Misttral 7b, showing its active use.
- Acceptance of service delivery: Mattuquant enables the creation of models to provide better accuracy between accuracy and computers, making it better for the oppressed resources.
- Pareto-Optimal Trade-Offs: Allows fitty removal of a small detail, such as IT6 and AT3, and it has agreed to dense accuracy – calls Pareto-active trading by enabling different information.
In conclusion, the matequant brings a solution to a multi-model management solution using a lot of training in the Nesteqed Data. This provides a flexible option, the highest performance of the lowest quality of the actual detection. This study shows that one model can be trained in a multi-number model without a very low range, especially in the lowest range, marking important development in models.
Survey the paper. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 75k + ml subreddit.
🚨 Recommended for an open source of AI' (Updated)
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
✅ [Recommended] Join Our Telegraph Channel


 -Training written by LLMs for any AI agent")
