Alaba investigators raise Videologam 3: Improved Multimodal Foundation of the image and video comprehension

Progress in Multimodal intelligence To practice and understanding photos and videos. Pictures can produce static scenes by providing information about the details such as objects, text, and local relationships. However, this comes at the cost of being a very big challenge. Video understanding includes tracking changes over time, among other activities, when verifying the consensus, requires powerful content management and temporary relationships. These activities are strong because the collection and description of the video-text details are difficult compared to the data text data.
Traditional ways of Large models of the great language (MLMS) Deal with the challenges of video understanding. It comes closer to spalled independent, and the pictures used by the photographs fail to successfully install temporary dependence on strong content. Tocken Comtresses and expanded by the context windows struggled with long video difficulty, while combining audio and visual installation often lacks sound communication. Efforts to Real-Time Preview and Model Skills remain unemployed, and existing structures are designed to respond to long video activities.
Dealing with the challenges of video understanding, researchers from Alaba Group proposed Videolama3 Outline. This frame includes Any-memory repair (AVT) including Pruner of different frame (Difffp). AVT is developing in traditional Traditional Tokenization by enabling deving Encoders to process volatility, reduce the loss of information. This is available in synchronization based emails with 2D-rope to flexible position. Keeping important information, various deals with refreshing video tokens and tallering the frames that have little different variations as taken 1-ordinary distance between the clips. Hosting of a strong decision, in combination with the reduction of effective Token, promotes representation while reducing costs.
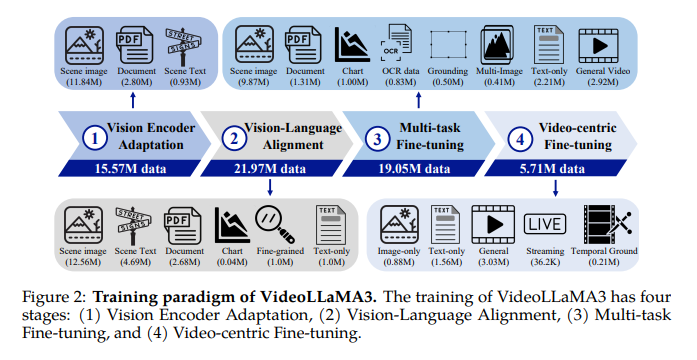
The model contains a Vision Encoder, Video Compressor, Projector, including Language's larger model (llm)Starts the Vision Encoder using the model of the previously trained SIGLIP. Issuing visible tokens, while the video compressces reduces video token representation. The project coordinates the Encoder's Vision in the LLM, and QWEN2.5 models used for the LLM. Training occurs in four sections: Transformation of Encoder Encoder, alignment, the good language formulation, video-Centuric's video order. The first three categories focus on the understanding of images, and the final phase improves video understanding by entering temporary information. This page Encoder Encoder Encoder Encoder It focuses on the good planning of Encoder Vision, hired by SIGLIP, the main image data, allowing to process pictures in different decisions. This page The Valuation section of the vision vision Information of multimodal information, making a llm and encoder's Vision accessible to combine the understanding and understanding of languages. In A MANY EDUCATION CENTERThe good teaching system is done using multimodal questions, including Image and video questions, enhancing the power of environmental law firm and processing temporary information. This page Video-Centinic Stage Search for Good UNFREZES ALL parameters to develop understanding skills of model. Details of training appear in various sources such as scenes, documents, charts, photography, and video data, confirming complete multimodal disconnection.
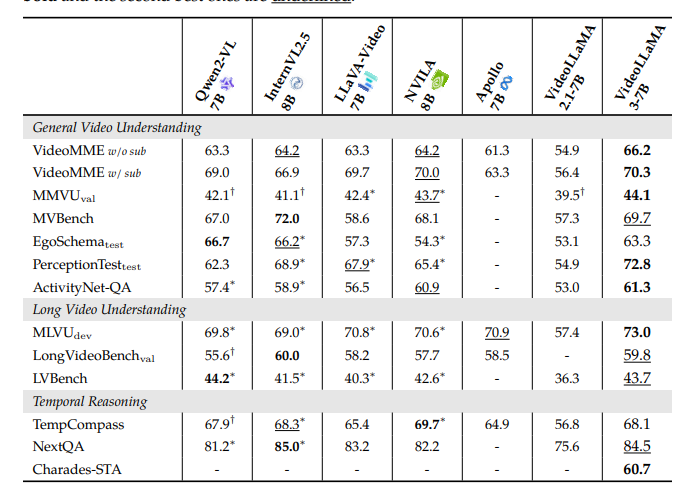
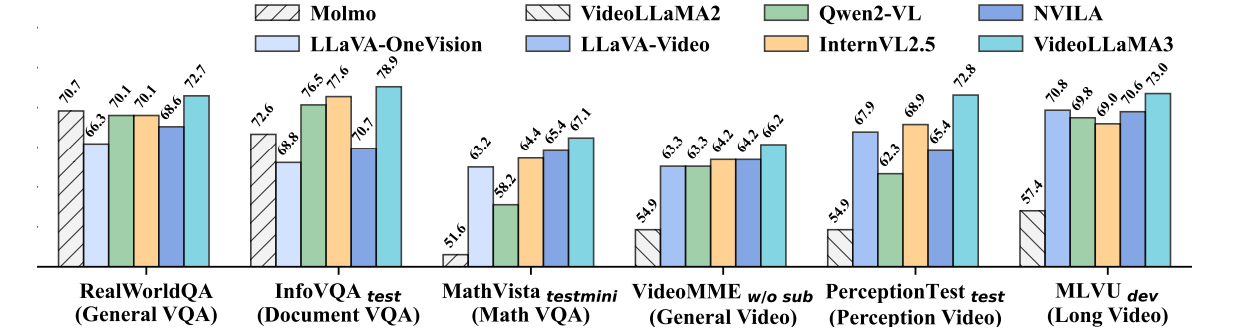
The investigators run the performance test exams of Videolama3 to Image and video activities. With the activities based on the illustration, the model was tested in the understanding of the document, mathematical thinking, and multiplication, where previous models passed, showing the understanding of the chart and the original country of the country. To answer the question (QA). In video-based activities, Videotama3 is firmly made from the benches like VideileMe including MVBANCHBeing skilled with a general video understanding, long video understanding, and temporary thinking. This page 2Se including 7 models do very competitive, and 7 The leading model in many video activities, emphasizing the functioning of model in multimodal activities. Some areas of the OCR report is reported by the OCR, consultation statistics, multiple understanding, and long-term video understanding.
Finally, the proposed framework is developing development of multimodal models and multimodal modimodal models, which provides a solid outline for understanding photos and videos. By using the high-text image-text-text it deals with the challenges of video recordings and temporary energy, they achieve strong results in all benches. However, challenges such as video data. Future research can improve video-text information, do well to perform actual performance, and combine additional modifices such as sound and speaking. This work can serve as a basis for future development in multimral understanding, to improve efficiency, common, and integration.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 70k + ml subreddit.
🚨 [Recommended Read] Nebius Ai Studio is increasing in observatory models, new language models, embodding and lora (Updated)
Divyesh is a contact in MarkteachPost. Pursuing BTech for agricultural and food engineers in the Indian Institute of Technology, Kharagpur. He is a scientific and typical scientific lover who wants to combine this leading technology in the agricultural background and resolve challenges.
📄 Multiate 'Equipment': A tool to manage private (sponsored) projects



